
kunakorn - stock.adobe.com
SIP und RTP: Effektive Methoden zur VoIP-Fehlersuche
Ein methodisches Vorgehen bei der Diagnose von SIP- und RTP-Störungen sichert die Verfügbarkeit von VoIP-Diensten. Strukturierte Prozesse führen schneller zur Fehlerbehebung.

Die Diagnose von Störungen in SIP- und RTP-basierten Kommunikationssystemen ist komplex, da die Ursachen für Qualitätsprobleme, Verbindungsabbrüche oder Signalisierungsfehler auf verschiedenen Ebenen des Netzwerks und der Protokollstacks liegen können. Ein strukturiertes Vorgehen ist daher unerlässlich, um Fehler effizient zu identifizieren und nachhaltig zu beheben. In diesem Abschnitt werden bewährte Methoden vorgestellt, die Administratoren und Systemtechnikern dabei helfen, sowohl temporäre als auch permanente Fehlerbilder systematisch zu analysieren und zu lösen. Dabei wird besonders auf die Bedeutung des Kontextes, die Anwendung des OSI-Modells als analytisches Rahmenwerk sowie die Notwendigkeit einer lückenlosen Dokumentation eingegangen.
Analyse von zeitweiligen Fehlern
Bei der Fehlersuche wird grundsätzlich zwischen zeitweiligen und permanenten Phänomenen unterschieden. Während permanente Fehler aufgrund ihrer Reproduzierbarkeit oft schneller eingegrenzt werden können, ist bei sporadischen Problemen eine tiefgreifende Korrelationsanalyse erforderlich. Dabei steht zunächst die Frage im Mittelpunkt, unter welchen spezifischen Bedingungen das Problem auftritt. Bei der Untersuchung zeitweiliger Fehler sollten Administratoren folgende Aspekte prüfen:
- Es gilt zu klären, ob der Fehler in Zusammenhang mit bestimmten Endgeräten, Servern, Rufnummern oder Netzwerkpfaden steht.
- Ebenso relevant ist die zeitliche Dimension. Tritt das Problem zu bestimmten Tageszeiten auf, nach einer definierten Gesprächszeit oder in Abhängigkeit von der Netzwerklast?
- In redundanten Netzwerkarchitekturen sollte zudem geprüft werden, ob der Fehler konsistent bei Datenflüssen über bestimmte Komponenten wie Router, Firewalls oder Session Border Controllern (SBC) auftritt.
Ein besonders effektiver Ansatz zur Eingrenzung zeitweiliger Fehler ist der Vergleich eines fehlerhaften mit einem fehlerfreien Szenario, auch Baselining genannt. Dabei wird der Netzwerkverkehr in einem funktionierenden Zustand aufgezeichnet und dem gestörten Szenario gegenübergestellt. Die Aufzeichnung sollte idealerweise direkt vor der Komponente beginnen, bei der der Fehler vermutet wird. Durch diesen Vergleich lassen sich Abweichungen in der Signalisierung, im Medienfluss oder in Netzwerkmetriken wie Paketverlust oder Jitter identifizieren, die auf die Ursache des Problems hinweisen.
Artikelserie zum SIP- und RTP-Troubleshooting
Artikelserie zum SIP- und RTP-Troubleshooting
Der erste Teil dieser Artikelserie befasste sich mit dem Aufbau des SIP- und RTP-Protokolls sowie Dialogen und Transaktionen. Der zweite Beitrag konzentriert sich auf die Werkzeuge zum VoIP-Troubleshooting. In diesem Teil geht es um konkrete Methoden und die Planung für ein effizientes und effektives Troubleshooting. Der vierte Teil veranschaulicht anhand von Beispielen die Fehlerbehebung in der Praxis.
Falls Sicherheitskomponenten wie Firewalls oder Session Border Controller im Verdacht stehen, das Fehlverhalten zu verursachen, kann es hilfreich sein, das Problem an einem anderen Punkt im Netzwerk nachzustellen. Hierzu werden entweder Mehrpunktmessungen oder ein iteratives Vorgehen eingesetzt, bei dem schrittweise verschiedene Netzwerkabschnitte überprüft werden. So lassen sich falsch konfigurierte Regeln oder asymmetrische Routing-Pfade erkennen, die zu den beobachteten Störungen führen könnten.
Analyse von permanenten Fehlern
Im Gegensatz zu zeitweisen Fehlern geht es bei permanenten Fehlerbildern direkt um die systematische Eingrenzung durch schrittweise Analyse. Diese gestaltet sich direkter, da die Fehler reproduzierbar sind und somit eine gezielte Fehlersuche ermöglichen.
Der erste Schritt besteht darin, den Fehler an dem Punkt zu lokalisieren, an dem er auftritt. In der Regel ist dies das Endgerät, beispielsweise ein Softphone oder ein Hardwaretelefon. Von dort aus arbeitet man sich schrittweise durch den Signalisierungs- oder Medienpfad vor, wobei an jedem relevanten Knotenpunkt, beispielsweise einem Switch, einem Router, einer Firewall oder einer WAN-Anbindung, der Datenverkehr aufgezeichnet wird.
Durch den Vergleich der Mitschnitte zwischen den Punkten, an denen der Fehler auftritt, und den Punkten, an denen er nicht auftaucht, lässt sich der fehlerhafte Abschnitt des Netzwerks eingrenzen. Dieser Abschnitt kann dann gezielt untersucht werden, etwa durch die Überprüfung von Konfigurationen, das Auswerten von Log-Dateien oder das Messen von Paketverlusten. Mithilfe dieser Methode lässt sich die Fehlerquelle präzise identifizieren und es können gezielte Maßnahmen zur Behebung eingeleitet werden.
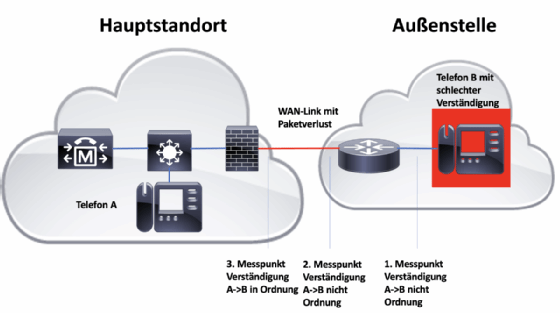
Ein typisches Beispiel wäre ein permanent auftretender Paketverlust bei RTP-Streams. Durch das schrittweise Vorarbeiten von einem Endgerät bis zum anderen könnte festgestellt werden, dass der Fehler erst nach dem Passieren eines bestimmten WAN-Links oder einer Firewall auftritt, wie in Abbildung 2 dargestellt. Im Fall des WAN-Links würde dies auf einen Fehler im Netz des Providers hindeuten, im Fall der Firewall müssten die Firewall-Regelwerke oder die Quality-of-Service-Einstellungen angepasst werden, um den Medienverkehr korrekt zu priorisieren.
Strukturierte Fehleranalyse anhand des OSI-Modells
Das OSI-7-Schichten-Modell ist ein bewährtes Rahmenwerk zur systematischen Analyse von Netzwerk- und Applikationsproblemen. Je nach Art des Fehlers und den Erfahrungen des Analysierenden können verschiedene Strategien angewendet werden, die sich an den Schichten des Modells orientieren. Im Folgenden werden die gängigsten Methoden vorgestellt. Sie weisen jeweils unterschiedliche Vor- und Nachteile auf und eignen sich für verschiedene Fehlerszenarien.
Bottom-up-Methode
Bei der Bottom-up-Methode arbeitet sich der Fehlersuchende von der physischen Schicht bis hin zur Anwendung vor. Die Bottom-up-Methode beginnt also bei der untersten Schicht des OSI-Modells, der Bitübertragungsschicht (Layer 1), und geht schrittweise nach oben vor. Dieser Ansatz eignet sich besonders dann, wenn der Verdacht auf physische oder netzwerktechnische Probleme besteht, wie etwa defekte Kabel, Ports oder Switches.
- Der Fehlersuchende prüft zunächst die physische Verbindung auf Layer 1, etwa durch Check von Kabeln, Steckverbindungen oder Port-Statusmeldungen auf Switches oder Routern.
- Anschließend wird die Datenverbindungsschicht (Layer 2) untersucht, wobei Aspekte wie Ethernet-Frames, VLAN-Konfigurationen oder MAC-Adressen im Fokus stehen.
- Auf der Netzwerkschicht (Layer 3) folgt die Kontrolle der IPv4- oder IPv6-Konnektivität, des Routings und der ICMP-Erreichbarkeit.
- Auf der Transportschicht (Layer 4) wird die korrekte Funktion von UDP- oder TCP-Ports etwa über Socket-Prüfungen oder Tools wie nmap geprüft.
- Erst wenn alle unteren Schichten fehlerfrei funktionieren, wird die Analyse auf die Sitzungs-, Darstellungs- und Anwendungsschicht (Layer 5–7) ausgeweitet. Hier stehen dann die SIP-Signalisierung, die SDP-Aushandlung oder die Codec-Kompatibilität im Mittelpunkt.
Ein typisches Beispiel für die Anwendung dieser Methode wäre ein Qualitätsproblem bei RTP-Streams, das zunächst auf Paketverluste in den Schichten 2 oder 3 zurückgeführt wird. Erst nach dem Ausschluss dieser Schichten als Fehlerquelle wäre die Analyse auf die höheren Schichten auszuweiten.
Ein Nachteil der Bottom-up-Methode ist, dass sie zeitaufwendig sein kann – insbesondere, wenn das Problem tatsächlich in den höheren Schichten liegt. Dennoch bietet sie den Vorteil einer systematischen und umfassenden Überprüfung aller Netzwerkkomponenten, was besonders in komplexen oder unbekannten Umgebungen von Vorteil ist.
Top-down-Methode
Bei der Top-down-Methode wird die Fehleranalyse auf der Anwendungsschicht (Layer 7) begonnen und dann schrittweise nach unten fortgesetzt. Dieser Ansatz ist besonders sinnvoll, wenn der Verdacht auf Anwendungs- oder Protokollprobleme besteht, etwa nach Software-Updates, Konfigurationsänderungen oder der Einführung neuer Dienste.
- Der Prozess beginnt mit der Überprüfung der Sprachübertragung auf Schicht 7.
- Anschließend wird die Darstellungsschicht (Layer 6) untersucht, etwa im Hinblick auf Datenformatierung und verwendete Codecs.
- Die Sitzungsschicht (Layer 5) steht im Fokus, wenn es um die Verwaltung von SIP-Dialogen oder Re-INVITEs geht.
- Auf der Transportschicht (Layer 4) wird die korrekte Nutzung und fehlerfreie Übertragung von UDP oder TCP geprüft, also beispielsweise ein Drei-Wege-Handshake mit SYN, SYN/ACK und ACK für TCP.
- Erst wenn die höheren Schichten fehlerfrei funktionieren, wird die Analyse auf die Netzwerk-, Datenverbindungs- und Bitübertragungsschicht (Layer 1–3) ausgeweitet.
Ein typisches Anwendungsbeispiel ist ein Anrufabbruch unmittelbar nach dem Wählen, der auf ein SIP-Protokollproblem, wie etwa eine fehlende Unterstützung für bestimmte Header oder eine inkompatible SDP-Konfiguration, hindeutet. Bei der Top-down-Methode wird direkt mit den Anwendungsschichten begonnen, folglich wird also recht schnell bei der SIP-Signalisierung angesetzt. Erst wenn diese Schicht als Fehlerquelle ausgeschlossen werden kann, werden die unteren Schichten geprüft.
Ein Vorteil dieser Methode ist die schnelle Identifikation von Anwendungsfehlern, insbesondere wenn der Fehler nur bei einzelnen Nutzern oder nach bestimmten Änderungen auftritt. Ein Nachteil besteht jedoch darin, dass die Suche zeitintensiv werden kann, wenn die Ursache tatsächlich in den unteren Schichten liegt, wie etwa bei einem Faserbruch einer Lichtwellenleiter-Verbindung durch nicht eingehaltene Biegeradien.
Divide and Conquer
Der Autor dieses Artikels bevorzugt in den meisten Fällen die differenzierte Analyse mittels der Divide-and-Conquer-Methode. Diese stellt einen hybriden Ansatz dar, der weder streng von unten noch von oben beginnt, sondern in der Regel auf der Vermittlungsschicht (Layer 3) startet und sich je nach Ergebnis nach oben oder unten bewegt. Dieser Ansatz eignet sich besonders für erfahrene Netzwerkanalysten, die auf Basis von Symptomen und Erfahrungswerten die Fehlerquelle effizient eingrenzen können.
- Der Prozess beginnt in der Regel mit ICMP-Tests wie Ping oder Traceroute, um die grundsätzliche Erreichbarkeit und den Pfad zum Ziel zu überprüfen.
- Funktioniert die geprüfte Schicht einwandfrei, wird die nächsthöhere Schicht untersucht.
- Liegt hingegen ein Problem vor, wird die Analyse auf die darunterliegende Schicht ausgeweitet.
Ein typisches Beispiel wäre ein Nutzer, der eine bestimmte Rufnummer nicht erreichen kann, während andere Anrufe problemlos funktionieren. In diesem Fall würde die Analyse direkt auf der Sitzungs- oder Anwendungsschicht (Layer 5/7) beginnen, etwa durch die Überprüfung der SIP-Routing-Tabellen oder der Rufnummernformatierung, anstatt bei der physischen Verbindung.
Der Vorteil dieser Methode liegt in ihrer Effizienz, da nicht alle Schichten des OSI-Modells geprüft werden müssen. Sie eignet sich besonders für erfahrene Techniker, die in der Lage sind, Symptome schnell einzuordnen und die Analyse gezielt zu steuern. Ein Nachteil könnte jedoch darin bestehen, dass weniger erfahrene Personen die Fehlerquelle möglicherweise übersehen, wenn sie nicht systematisch genug vorgehen.
Iterativer Prozess
Beim iterativen Prozess handelt es sich um eine pragmatische Methode, bei der der Analyst schrittweise entlang des Kommunikationspfads vorgeht, um den Ort des Fehlers einzugrenzen. Dieser Ansatz eignet sich besonders für komplexe Netzwerke mit vielen Komponenten wie Firewalls, Session Border Controllern oder WAN-Links, bei denen die Fehlerquelle nicht sofort offensichtlich ist.
Der Prozess beginnt mit der Aufzeichnung des Datenverkehrs direkt am fehlerhaften Endgerät, etwa durch den Einsatz eines Test Access Points (TAP). Anschließend werden an mehreren Punkten im Netzwerk weitere Mitschnitte erstellt, etwa vor und nach Firewalls, Routern oder WAN-Anbindungen. Durch den Vergleich dieser Mitschnitte lässt sich der Abschnitt identifizieren, in dem der Fehler erstmals auftritt. Dieser Abschnitt kann dann gezielt analysiert werden, um die genaue Ursache zu ermitteln.
Ein praktisches Beispiel wäre ein Telefon, das bei allen Gesprächen einen erhöhten Paketverlust aufweist. Durch Mitschnitte könnte festgestellt werden, dass der Fehler nicht am WAN-Übergang auftritt, sondern davor. Dies deutet darauf hin, dass die Ursache im lokalen Netzwerksegment liegt. Dieser Ansatz ist besonders effizient in verteilten Netzwerken, da er eine gezielte Eingrenzung des Fehlerorts ermöglicht, ohne dass alle Komponenten umfassend geprüft werden müssen.
Ein Nachteil dieses Verfahrens besteht darin, dass es Mehrpunktmessungen erfordert, was in großen Netzwerken mit vielen Hops aufwendig sein kann. Zudem kann der Einsatz von TAPs oder SPAN-Ports zusätzlichen Hardware- oder Konfigurationsaufwand bedeuten und im Fall von TAPs auch zusätzliche Kosten verursachen.
Dokumentation
Es ist eine Binsenweisheit, aber eine Dokumentation ist für die strukturierte Nachverfolgung und Wissenssicherung unerlässlich. Eine lückenlose Dokumentation ist ein wichtiger Bestandteil des Troubleshooting-Prozesses – insbesondere, wenn mehrere Personen beteiligt sind oder komplexe Fehlerbilder vorliegen. Sie dient der Nachvollziehbarkeit der durchgeführten Schritte und der Vermeidung von Dopplungen sowie der Wissenssicherung für zukünftige Fälle.
Die Dokumentation sollte mindestens die folgenden Bestandteile umfassen:
- Zunächst gilt es, das konkrete Fehlerbild detailliert zu beschreiben. Dazu gehören Angaben zu Quell- und Zielrufnummer, Uhrzeit und Datum des Auftretens, die Häufigkeit des Fehlers sowie seine Reproduzierbarkeit. Zudem sollten die Symptome so präzise wie möglich festgehalten werden, etwa „einseitiger Audioverlust“, „Anrufabbruch nach 30 Sekunden“ oder „keine Registrierung am SIP-Server“.
- Anschließend werden die durchgeführten Aufzeichnungen dokumentiert, etwa welche Mitschnitte (PCAP-Dateien) an welchen Punkten im Netzwerk erstellt wurden, welche Tools und Filter zum Einsatz kamen und welche Log-Dateien oder Screenshots gesichert wurden. Dies ermöglicht es, die Analyse später nachzuvollziehen oder durch andere Teammitglieder überprüfen zu lassen.
- Der Analyseprozess selbst sollte ebenfalls strukturiert festgehalten werden. Dazu gehört die Beschreibung der identifizierten Abweichungen, etwa ungewöhnliche SIP-Antwortcodes, Paketverluste in RTP-Streams oder Inkompatibilitäten in der SDP-Aushandlung. Ein Vergleich mit einem fehlerfreien Baseline-Szenario kann dabei helfen, die relevanten Unterschiede herauszuarbeiten.
- Schließlich müssen alle zur Fehlerbehebung durchgeführten Änderungen (Changes) dokumentiert werden. Dabei ist es entscheidend, nur eine Änderung gleichzeitig vorzunehmen und diese bei negativem Ergebnis sofort rückgängig zu machen. Idealerweise wird jede Änderung mit den daraufhin durchgeführten Tests und den erzielten Ergebnissen verknüpft, um sicherzustellen, dass die Maßnahme tatsächlich die gewünschte Wirkung hatte.
Praktische Tipps für die Dokumentation
Es empfiehlt sich, ein Incident-Management-System einzusetzen, um alle Schritte in Tickets zu erfassen und den Bearbeitungsverlauf nachvollziehbar zu gestalten. Für die nachhaltige Verwertung der gewonnenen Erkenntnisse ist eine Knowledge-Base sehr hilfreich. In dieser werden Lösungen für wiederkehrende Fehler gesammelt, so dass bei ähnlichen Problemen in der Zukunft schneller reagiert werden kann. Zur verständlichen Darstellung komplexer Zusammenhänge sind Visualisierungen wie Netzwerk- oder Flussdiagramme hilfreich.
Ein beispielhafter Dokumentationsablauf könnte wie folgt aussehen:
- Zunächst wird das Fehlerbild beschrieben: „Einseitiger Audioverlust bei Anrufen von Rufnummer A zu Rufnummer B, reproduzierbar seit 10:00 Uhr.“
- Anschließend werden die Aufzeichnungen festgehalten: „PCAP-Mitschnitt vor Firewall X, Filter: SIP und RTP, Dauer: 5 Minuten.“
- Die Analyse ergibt: „Paketverlust von 20 % auf dem RTP-Stream von A zu B, SIP-Signalisierung intakt.“
- Als Change wird notiert: „DSCP-Markierung auf Router R-WAN-1 von 0 bzw. Best Effort auf 46 bzw. Expedited Forwarding mit Low Latency Queueing angepasst.“
- Anschließendes Messergebnis: Audio wieder bidirektional.“
Fazit
Die methodische Herangehensweise ist der Schlüssel zu einem effizienten und effektiven Troubleshooting von SIP- und RTP-basierten Kommunikationssystemen. Je nach Art des Fehlers – zeitweilig oder permanent – können verschiedene Strategien wie Bottom-up, Top-down, Divide and Conquer oder iterative Prozesse angewendet werden. Das OSI-Modell bietet dabei ein bewährtes Rahmenwerk, um Fehler systematisch einzugrenzen und zu beheben.
Eine lückenlose Dokumentation aller Schritte sichert nicht nur die Nachvollziehbarkeit, sondern schafft auch eine wertvolle Wissensbasis für zukünftige Fälle. Durch die Kombination aus strukturierter Analyse, gezielter Eingrenzung und detaillierter Protokollierung lassen sich selbst komplexe Fehlerbilder effizient lösen und die Stabilität der Kommunikationsinfrastruktur nachhaltig sichern.


