
Getty Images/iStockphoto
Kubeflow-Tutorial: So richten Sie eine Pipeline für ML ein
Für Teams, die Workflows für maschinelles Lernen mit Kubernetes ausführen, kann die Verwendung von Kubeflow zu schnelleren und reibungsloseren Bereitstellungen führen.

Sie müssen Kubernetes nicht verwenden, um Machine-Learning-Bereitstellungen zu betreiben. Wenn Sie dies jedoch tun möchten, und es gibt viele Gründe, warum Sie dies sinnvoll sein kann, ist Kubeflow die einfachste und schnellste Möglichkeit, Machine-Learning-Arbeitslasten auf Kubernetes zum Laufen zu bringen.
Kubeflow ist ein Open Source Tool, das die Bereitstellung von Workflows für maschinelles Lernen auf Kubernetes rationalisiert. Der Hauptzweck von Kubeflow besteht darin, die Einrichtung von Umgebungen zum Erstellen, Testen, Trainieren und Betreiben von Modellen und Anwendungen für maschinelles Lernen für Data Science- und MLOps-Teams zu vereinfachen.
Es ist möglich, Machine Learning Tools wie TensorFlow und PyTorch direkt auf einem Kubernetes-Cluster einzusetzen, ohne Kubeflow zu verwenden, aber Kubeflow automatisiert einen Großteil des Prozesses, der erforderlich ist, um diese Tools zum Laufen zu bringen. Um zu entscheiden, ob Kubeflow die richtige Wahl für Ihre Machine-Learning-Projekte ist, erfahren Sie hier, wie Kubeflow funktioniert, wann es zu verwenden ist und wie man es installiert, um eine ML-Pipeline bereitzustellen.
Die Vor- und Nachteile von Kubernetes und Kubeflow für maschinelles Lernen
Bevor Sie sich für den Einsatz von Kubeflow entscheiden, ist es wichtig, die Vor- und Nachteile der Ausführung von KI- und ML-Workflows auf Kubernetes im Allgemeinen zu verstehen.
Sollten Sie Modelle für maschinelles Lernen auf Kubernetes ausführen?
Als Plattform für das Hosting von Workflows für maschinelles Lernen bietet Kubernetes mehrere Vorteile.
Der erste ist die Skalierbarkeit. Mit Kubernetes können Sie ganz einfach Knoten zu einem Cluster hinzufügen oder aus ihm entfernen, um die für diesen Cluster verfügbaren Gesamtressourcen zu ändern. Dies ist besonders vorteilhaft für Arbeitslasten des maschinellen Lernens, deren Ressourcenbedarf stark schwanken kann. So kann es beispielsweise sinnvoll sein, das Cluster während des Modelltraining, die in der Regel viele Ressourcen erfordert, zu vergrößern und nach Abschluss des Trainings wieder zu verkleinern, um die Infrastrukturkosten zu senken.
Das Hosten von Workflows für maschinelles Lernen auf Kubernetes bietet außerdem den Vorteil, dass Container Zugriff auf Bare-Metal-Hardware haben. Dies ist nützlich, um die Leistung Ihrer Workloads mit GPUs oder anderer Hardware zu beschleunigen, die in einer virtuellen Infrastruktur nicht zugänglich wäre. Obwohl Sie auch ohne Kubernetes auf Bare-Metal-Infrastrukturen zugreifen können, indem Sie Arbeitslasten in eigenständigen Containern ausführen, erleichtert die Orchestrierung von Containern mit Kubernetes die Verwaltung von Arbeitslasten in großem Umfang.
Ein wichtiger Grund, warum Sie Kubernetes nicht zum Hosten von Workflows für maschinelles Lernen verwenden sollten, ist jedoch, dass es Ihrem Software-Stack eine weitere Komplexitätsebene hinzufügt. Für kleinere Workloads könnte eine Kubernetes-basierte Bereitstellung zu viel des Guten sein. In solchen Situationen könnte es sinnvoller sein, Workloads direkt auf VMs oder Bare-Metal-Servern auszuführen.
Wann sollten Sie sich für Kubeflow entscheiden?
Der Hauptvorteil der Verwendung von Kubeflow für maschinelles Lernen ist der schnelle und einfache Bereitstellungsprozess des Tools. Mit nur wenigen kubectl-Befehlen erhalten Sie eine einsatzbereite Umgebung, in der Sie mit der Bereitstellung von Workflows für maschinelles Lernen beginnen können.
Andererseits beschränkt sich Kubeflow auf die von ihm unterstützten Tools und Frameworks und enthält möglicherweise einige Ressourcen, die Sie am Ende nicht verwenden werden. Wenn Sie nur ein oder zwei bestimmte Tools für maschinelles Lernen benötigen, ist es vielleicht einfacher, diese einzeln zu implementieren, als mit Kubeflow. Aber für alle, die eine Allzweckumgebung für maschinelles Lernen auf Kubernetes benötigen, ist es schwer, gegen Kubeflow zu argumentieren.
Kubeflow-Anleitung: Installation
Bei den meisten Kubernetes-Distributionen beschränkt sich die Installation von Kubeflow auf die Ausführung einiger weniger Befehle.
In diesem Tutorial wird der Prozess anhand von K3s demonstriert, einer leichtgewichtigen Kubernetes-Distribution, die Sie auf einem Laptop oder PC ausführen können, aber Sie sollten in der Lage sein, die gleichen Schritte auf jeder gängigen Kubernetes-Plattform auszuführen.
Schritt 1. Erstellen eines Kubernetes-Clusters
Beginnen Sie mit der Erstellung eines Kubernetes-Clusters, falls Sie noch keins haben.
Um ein Cluster mit K3s einzurichten, laden Sie zunächst K3s mit dem folgenden Befehl herunter.
curl -sfL https://get.k3s.io | sh -
Führen Sie anschließend den folgenden Befehl aus, um ein Cluster zu starten.
sudo k3s server &
Um zu überprüfen, ob alles wie erwartet läuft, führen Sie den folgenden Befehl aus.
sudo k3s kubectl get node
Die Ausgabe sollte aussehen wie in Abbildung 2.
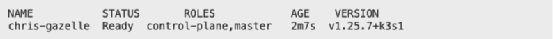
Schritt 2. Kubeflow installieren
Nachdem Ihr Cluster eingerichtet ist und läuft, ist der nächste Schritt die Installation von Kubeflow. Verwenden Sie die folgenden Befehle, um dies auf einem lokalen Rechner mit K3s zu tun.
sudo -s
export PIPELINE_VERSION=1.8.5
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/cluster-scoped-resources?ref=$PIPELINE_VERSION"
kubectl wait --for condition=established --timeout=60s crd/applications.app.k8s.io
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/platform-agnostic-pns?ref=$PIPELINE_VERSION"
Wenn Sie Kubeflow auf einem nicht-lokalen Kubernetes-Cluster installieren, funktionieren die folgenden Befehle in den meisten Fällen.
export PIPELINE_VERSION=<kfp-version-zwischen-0.2.0-und-0.3.0>
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/base/crds?ref=$PIPELINE_VERSION"
kubectl wait --for condition=established --timeout=60s crd/applications.app.k8s.io
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/dev?ref=$PIPELINE_VERSION"
Schritt 3. Überprüfen Sie, ob die Container laufen
Auch nach der Installation von Kubeflow ist es erst dann voll einsatzfähig, wenn alle Container, aus denen es besteht, ausgeführt werden. Überprüfen Sie den Status Ihrer Container mit dem folgenden Befehl.
kubectl get pods -n kubeflow
Wenn die Container nach einigen Minuten noch nicht erfolgreich laufen, überprüfen Sie die Protokolle, um die Ursache zu ermitteln.
Schritt 4. Starten Sie mit Kubeflow
Kubeflow bietet ein webbasiertes Dashboard zum Erstellen und Bereitstellen von Pipelines. Um auf dieses Dashboard zuzugreifen, stellen Sie zunächst sicher, dass die Portweiterleitung korrekt konfiguriert ist, indem Sie den folgenden Befehl ausführen.
kubectl port-forward -n kubeflow svc/ml-pipeline-ui 8080:80
Wenn Sie Kubeflow lokal ausführen, können Sie auf das Dashboard zugreifen, indem Sie einen Webbrowser unter der URL http://localhost/8080 öffnen. Wenn Sie Kubeflow auf einem entfernten Rechner installiert haben, ersetzen Sie localhost durch die IP-Adresse oder den Hostnamen des Servers, auf dem Sie Kubeflow ausführen.






