MPP-Datenbank (Massive Parallel Processing Database)

Was ist eine MPP-Datenbank (Massive Parallel Processing Database)?
Eine MPP-Datenbank (Massively Parallel Processing) ist eine Datenbank, die für die parallele Verarbeitung vieler Operationen optimiert ist, die von vielen Verarbeitungseinheiten gleichzeitig ausgeführt werden.
MPP ist die koordinierte Verarbeitung eines Programms durch mehrere Prozessoren, die an verschiedenen Teilen des Programms arbeiten. Jeder Prozessor hat sein eigenes Betriebssystem (OS) und seinen eigenen Speicher.
MPP-Datenbanken sind eine Art von Data Warehouse, bei dem mehrere Knoten (Server) die Verarbeitung übernehmen. Die Verarbeitung wird also auf mehrere Knoten aufgeteilt. Die Prozessoren kommunizieren miteinander, um die Beantwortung von Abfragen zu beschleunigen, insbesondere von Abfragen im Zusammenhang mit komplexen Suchen in großen Datenbeständen. Ohne MPP wäre die Leistung großer Datenbanken suboptimal und die Ausführung selbst einfacher Abfragen würde lange dauern.
Wie MPP-Datenbanken funktionieren
MPP-Datenbanken verwenden Multicore-Prozessoren, mehrere Prozessoren und Server sowie Speichergeräte, die für die Parallelverarbeitung ausgerüstet sind. Diese Kombination ermöglicht es, viele Daten gleichzeitig über viele Verarbeitungseinheiten zu lesen, um die Geschwindigkeit zu erhöhen. Diese Methode ist notwendig, weil die Frequenzen der Prozessoren an die Grenzen der verwendeten Technologien stoßen und nur langsam gesteigert werden können.
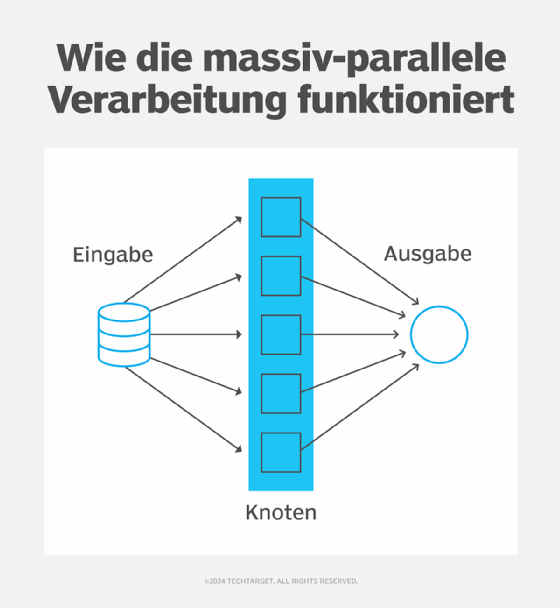
Bei der Aufteilung der Verarbeitung auf mehrere Knoten fungiert ein Knoten als Leitknoten. Dieser Knoten kommuniziert mit allen anderen Rechenknoten und erteilt ihnen Anweisungen. Die Rechenknoten führen die Anfragen des Leitknoten aus. Außerdem teilen sie große Aufgaben in kleinere, besser zu verwaltende Aufgaben (Chunks) auf und arbeiten unabhängig und gleichzeitig (das heißt parallel) an diesen Aufgaben, um die Verarbeitung zu beschleunigen und Abfrageergebnisse schneller zu liefern. Das Hinzufügen weiterer Prozessoren zur Datenbank zusammen mit einer Verbindung mit hoher Bandbreite zwischen den Knoten beschleunigt die Verarbeitung weiter, was bei einer großen Datenbank enorme Leistungs- und Verarbeitungsvorteile bringen kann.
In einer MPP-Datenbank bezieht sich ein Knoten normalerweise auf einen Server. Aber auch Desktop-PCs und virtuelle Server können als Knoten fungieren. Jeder Knoten kann eine oder mehrere Verarbeitungseinheiten haben und wird als Baustein einer MPP-Datenbank betrachtet.
Wofür werden MPP-Datenbanken verwendet?
MPP-Datenbanken eignen sich am besten für Entscheidungsunterstützungssysteme, Data-Warehouse-Anwendungen, maschinelles Lernen und Simulationen. Auch wissenschaftliche Anwendungen, bei denen auf große Datenmengen zugegriffen und diese abgefragt werden müssen, profitieren von MPP-Datenbanken. Cloud Computing und Big-Data-Analysen sind weitere gängige Anwendungen für MPP-Datenbanken.
Anwendungen, bei denen große Mengen strukturierter Daten zentralisiert und an einem einzigen Ort verfügbar sein müssen, nutzen ebenfalls MPP-Datenbanken. Ein solches Data Warehouse ermöglicht einen einfachen Datenzugriff unabhängig vom Standort des Benutzers. Außerdem bietet es eine Single Source of Truth (SSOT), so dass jeder zu jeder Zeit auf dieselben Daten zugreifen kann.
Was sind die Vorteile einer MPP-Datenbank?
MPP beschleunigt die Leistung riesiger Datenbanken, die mit großen Datenmengen arbeiten. Durch das Hinzufügen weiterer Server (Knoten) verringert sich die Zeit, die für die Durchführung komplexer Suchvorgänge in großen Datenbeständen benötigt wird. MPP-Datenbanken bieten außerdem eine nahezu unbegrenzte Skalierbarkeit, was eine weitere Beschleunigung der Abfrageergebnisse und einen schnelleren Datenzugriff ermöglicht.
MPP-Datenbanken sind auch kosteneffizient. Bei diesen Datenbanken wird für Aufgaben, die mehr Verarbeitungsleistung erfordern, nicht die schnellste oder teuerste Hardware benötigt. Stattdessen können Knoten hinzugefügt werden, um die Arbeitslast zu verteilen und die Verarbeitung zu beschleunigen, ohne dass die Hardwarekosten spürbar steigen. Außerdem wird beim Hinzufügen von Knoten nicht der gesamte Cluster außer Betrieb gesetzt.
Ein weiterer Vorteil einer MPP-Datenbank ist die hohe Zuverlässigkeit. Wenn ein Knoten ausfällt, arbeiten die anderen Knoten weiter und minimieren so die Gefahr eines Single Point of Failure. Schließlich sind MPP-Datenbanken eine gute Wahl, wenn detaillierte Analysen oder tiefe Einblicke in große oder komplexe Data Warehouses erforderlich sind.
MPP versus symmetrisches Multiprocessing-System
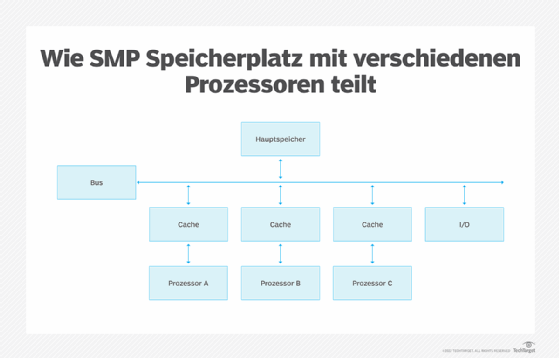
Ein symmetrisches Multiprozessorsystem (SMP) bezieht sich auf eine Art von Computerarchitektur, die mehrere Prozessoren verwendet, wobei jeder Prozessor den gleichen Zugriff auf den Arbeitsspeicher, die Software und die Eingabe-/Ausgaberessourcen (E/A) eines Computers hat. Neben der gemeinsamen Nutzung von Ressourcen in einer Clusterkonfiguration verwenden die Prozessoren auch ein gemeinsames Betriebssystem.
Die gemeinsame Nutzung des Speichers ermöglicht schnelle Berechnungen, da die Prozessoren schnell kommunizieren und sich synchronisieren können. Dennoch ist diese Verarbeitungsgeschwindigkeit nur für Anwendungen wie E-Mail und kleine Websites geeignet, bei denen keine hohe Rechenleistung (und Geschwindigkeit) erforderlich ist. Außerdem verfügen die Prozessoren über einen eigenen Cache-Speicher, was zu einer Cache-Inkohärenz führen kann, die mehr Overhead erzeugt, Engpässe zwischen den Prozessoren und dem Hauptspeicher schafft und den Gesamtdurchsatz der Prozessoren verringert.
Fast alle Unternehmen, die mit großen Datenmengen arbeiten, haben Datenbanken, die massiv parallel sind. Ein MPP-System eignet sich besser als ein SMP-System für Anwendungen, bei denen mehrere Datenbanken parallel durchsucht werden können. Durch die parallele Verarbeitung bieten MPP-Datenbanken schnellere Suchzeiten als SMP-Datenbanken.
SMP bietet außerdem eine begrenzte Skalierbarkeit, da alle Prozessoren in einem einzigen System denselben Speicher nutzen und dort arbeiten. Im Gegensatz dazu werden bei MPP mehrere Prozessoren eingesetzt, die jeweils parallel an einem einzigen Rechenproblem arbeiten. Die Anzahl der Prozessoren kann je nach Art und Größe des Problems leicht erhöht werden, wodurch MPP-Datenbanken besser skalierbar sind als SMP-Systeme.






