
Getty Images
Wann und wie Sie Datenbanken auf Kubernetes betreiben
Die Entscheidung, ob Sie Datenbanken auf Kubernetes verlagern sollten, erfordert eine sorgfältige Abwägung, besonders bei der Wahl zwischen verschiedenen Bereitstellungsoptionen.

Obwohl Kubernetes vor allem für die Ausführung von Anwendungen bekannt ist, kann es auch Datenbanken ausführen. Es ist jedoch wichtig, sorgfältig zu prüfen, ob Ihre Datenbank für Kubernetes geeignet ist und wie sie am besten in einer Kubernetes-Umgebung eingesetzt werden kann.
Es gibt zwei Hauptoptionen für den Einsatz einer Datenbank in Kubernetes: StatefulSets und benutzerdefinierte Operators. Obwohl es eine Reihe von Optionen gibt, gehören StatefulSets und benutzerdefinierte Operators zu den beliebtesten Optionen, und welche Methode zu verwenden ist, hängt weitgehend von der Art der Datenbank ab, die Sie nutzen.
Wann StatefulSets für die Ausführung von Datenbanken in Kubernetes verwendet werden sollten
StatefulSets sind eine Art von Kubernetes-Controller. Sie eignen sich gut für Datenbanken, da jedes StatefulSet ein zugehöriges persistentes Storage-Volume mit einer zugewiesenen, eindeutigen Netzwerkidentität haben kann. Das macht sie praktisch für die Verwendung mit zustandsabhängigen Anwendungen, aber sie erfordern oft mehr Arbeit und Planung als andere Kubernetes Controller.
Da Kubernetes Pods dynamisch erstellt, skaliert und gelöscht werden, ist die Dauerhaftigkeit eines einzelnen Pods nicht garantiert. StatefulSets ermöglichen jedoch persistentes Storage, sodass die Datenbankanwendung in einem Pod ausgeführt werden kann, während die Daten auf dem persistenten Storage-Volume gespeichert sind.
Das bedeutet, dass selbst wenn ein Pod gelöscht wird, seine Daten erhalten bleiben. Da das persistente Storage-Volume eine bekannte Netzwerkidentität hat, wissen Pods, die in Zukunft aufgrund von Skalierungen erstellt werden, wo die Anwendungsdaten zu finden sind.
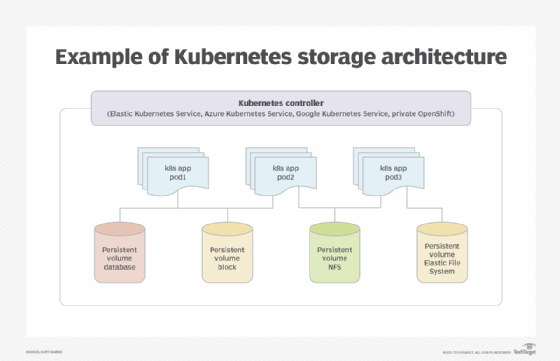
Das Wichtigste, was Sie bei der Verwendung von StatefulSets für das Hosting von Datenbanken beachten müssen, ist, dass Pods nicht persistent sind. Betrachten Sie die Pods als flüchtig; es ist nicht zu erwarten, dass ein Pod eine lange Lebensdauer hat. Wählen Sie daher eine Datenbankplattform, die die ständige Erstellung und Löschung von Pods bewältigen kann und synchrone Schreibvorgänge in der Datenbank unterstützt.
Darüber hinaus setzen einige Datenbanken stark auf Caching, bei dem Schreibvorgänge im Arbeitsspeicher oder in Transaktionsprotokollen gespeichert werden, bis diese Schreibvorgänge auf eine Festplatte übertragen werden können. Das Problem bei diesem Ansatz ist, dass bei einer Verkleinerung der Kubernetes-Arbeitslast ein bestimmter Pod gelöscht werden könnte, bevor seine Transaktionen in den persistenten Speicher übertragen werden, was bedeutet, dass diese Transaktionen verschwinden würden. Durch das direkte Schreiben von Transaktionen in die Datenbank wird hingegen sichergestellt, dass die Daten erhalten bleiben, auch wenn einzelne Pods kommen und gehen.
StatefulSets vs. eigene Operators für Kubernetes-Datenbanken
Wenn Sie sich entscheiden, Ihre Datenbank unter Kubernetes laufen zu lassen, ist die Verwendung von StatefulSets in der Regel die einfachste Option, solange Ihre Datenbank die grundlegenden Anforderungen dafür erfüllt. Die Verwendung von benutzerdefinierten Operators ist dagegen mit viel mehr Arbeit verbunden, bietet aber im Vergleich zu StatefulSets eine größere Flexibilität.
Wann sollten Sie benutzerdefinierte Operators verwenden, um Datenbanken in Kubernetes auszuführen?
Wie StatefulSets sind Operators eine Art von Kubernetes-Controller. Benutzerdefinierte Operators fungieren jedoch als Abstraktionsschicht, die es ermöglicht, dass Anwendungen, die ursprünglich nicht für Kubernetes entwickelt wurden, in der Kubernetes-Umgebung funktionieren.
Obwohl benutzerdefinierte Operators eng mit der Datenbankverwaltung verbunden sind, können sie auch zum Datenbankbereitstellungsprozess beitragen. Datenbankanwendungen umfassen oft mehrere Ebenen und zahlreiche Komponenten. Daher können Sie einen benutzerdefinierten Operator verwenden, um sicherzustellen, dass alle erforderlichen Komponenten vorhanden sind und in der richtigen Reihenfolge gestartet werden.
Der Nachteil der Verwendung eines benutzerdefinierten Operators ist, dass Sie entweder das Kubernetes Operator SDKverwenden müssen, um Ihren eigenen benutzerdefinierten Operator zu erstellen, oder einen vorhandenen Operator für Ihre Datenbankplattform herunterladen müssen. Für diejenigen, die ihren eigenen benutzerdefinierten Operator erstellen möchten, fungiert das Kubernetes Operator SDK im Wesentlichen als Entwicklungs-Framework zur Erstellung der für die Verwaltung von Datenbankressourcen erforderlichen Logik.
Die Funktionen, die dieses Framework ermöglicht, variieren stark von einer Datenbankbereitstellung zur anderen. Zu den gebräuchlichsten Funktionen gehören das Erstellen und Skalieren von Datenbankinstanzen und die Erleichterung von Datenbank-Backups.






