NVIDIA GPU Cloud vereint Data Science und Container
NVIDIA GPU Cloud ermöglicht die Bereitstellung von Data Science Workloads, die sich über lokale Systeme und Public Clouds erstrecken – mit Hilfe von Containern.
GPUs, die Machine-Learning- und Deep-Learning-Algorithmen beschleunigen können, treiben die nächste Generation von Data Science und KI-Workloads an. Gründe für die Verbindung zwischen GPUs und Data Science gibt es viele.
Die Image-Rendering-Algorithmen, die GPUs traditionell zur Simulation von 3D-Umgebungen verwenden, setzen auf ein ähnliches mathematisches Modell, wie es Data Scientists verwenden. Darüber hinaus eignen sich die bei Machine Learning und Deep Learning verwendeten Tensoren (mehrdimensionale Matrizen) gut für die parallele Ausführung auf GPU-Kernen. Das Ergebnis dieser Entwicklung ist eine wahre Explosion der Möglichkeiten für Data-Science- und Machine-Learning- Programmier-Frameworks. Die Generierung anspruchsvoller Algorithmen wird damit deutlich erleichtert und für die GPU-Ausführung optimiert.
Für Neueinsteiger in Data Science und GPU Computing kann es jedoch kompliziert sein, Machine Learning Frameworks wie Caffe2, PyTorch oder TensorFlow zu erstellen, zu konfigurieren und zu integrieren. Das gilt insbesondere für diejenigen, die mit systeminternen Prozessen, Abhängigkeiten und Konfigurationsparametern nicht vertraut sind.
Angebote wie NVIDIA GPU Cloud zielen darauf ab, Data Science auf GPU-Basis zugänglicher zu machen – mit Hilfe von Containern.
Doch auch Insider finden sich nicht so leicht zurecht: Im Allgemeinen ist es eine große Herausforderung, die richtigen Data-Science-Werkzeuge zu finden und sie in ein zusammenhängendes Ökosystem zu integrieren.
Glücklicherweise ändert sich diese unbefriedigende Situation gerade. Angebote wie NVIDIA GPU Cloud zielen darauf ab, Data Science auf GPU-Basis zugänglicher zu machen – mit Hilfe von Containern.
Einführung in NVIDIA GPU Cloud
NVIDIA GPU Cloud ist eine Bibliothek von containerisierten, GPU-optimierten und integrierten Paketen. Diese enthalten Data Science und Deep Learning Development Frameworks und sind für den Einsatz in der Cloud geeignet. Jedes Container-Image, das sowohl auf Single- als auch auf Multi-GPU-Systemen funktioniert, beinhaltet alle notwendigen Abhängigkeiten.
Die NVIDIA GPU Cloud enthält derzeit folgende Frameworks:
CUDA Toolkit: Eine native Entwicklungsumgebung für CUDA, NVIDIAs GPU Application Framework. Das Toolkit enthält einen C/C++-Compiler, Bibliotheken, Debugger und Optimierungswerkzeuge.
DIGITS (Deep Learning GPU Training System): Ein Deep Learning GPU-Trainingssystem mit Dashboard, Echtzeit-Überwachung und Deep-Learning-Netzwerkvisualisierung.
NVCaffe und Caffe2: Deep Learning Development Frameworks mit C++- und Python-Schnittstellen, die eine Vielzahl von Deep-Learning-Modelltypen unterstützen.
Microsoft Cognitive Toolkit: Ein Open-Source-Toolkit, das auch C++ und Python unterstützt, aber die High-Level-Modellbeschreibungssprache Branscript enthält und Open Neural Network Exchange unterstützt.
MXNet: Ein Apache Open-Source-Projekt, das eine High-Level Bibliothek von neuronalen Netzwerk-Bausteinen enthält.
PyTorch: Ein Python-Paket, das GPU-optimierte Tensor-Berechnungen und dynamische neuronale Netzwerke unterstützt.
TensorFlow: Eine von Google entwickelte Open-Source-Bibliothek zur Tensor-Berechnung.
Theano: Eine Python-Bibliothek für allgemeine mathematische und statistische Berechnungen.
Torch: Ein Framework für wissenschaftliches Rechnen, das eine schnelle Skriptsprache verwendet und Array-Verarbeitung unterstützt, lineare Algebra und neuronale Netze mit einer umfangreichen Bibliothek von nützlichen Paketen.
Eine hybride Data-Science-Plattform aufbauen
Diese Data Science Container-Pakete funktionieren auf jedem System mit einer NVIDIA GPU – egal ob es sich dabei um einen lokalen Server mit GPU-Grafikkarten handelt, ein dediziertes GPU-Entwicklungssystem, eine Data Science Workstation oder eine GPU-fähige Cloud-Instanz.
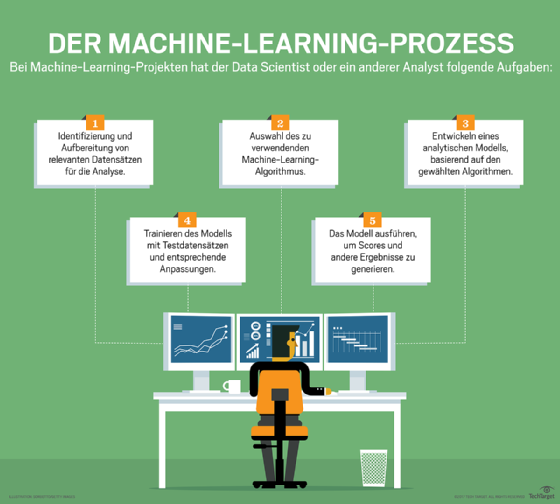
Abbildung 1: Der Machine-Learning-Prozess aus Sicht eines Data Scientists.
Die drei großen Public Cloud-Anbieter bieten derzeit die folgenden GPU-Compute-Instanzen an:
AWS: P3-Instanzen mit einem, vier oder acht NVIDIA Tesla V100 GPUs und P2-Instanzen mit einem, acht oder 16 NVIDIA Tesla K80 GPUs.
Microsoft Azure: NCv3 mit einem, zwei oder vier V100 GPUs; NCv2 mit einem, zwei oder vier P100 GPUs; NC mit einem, zwei oder vier K80 GPUs; und ND mit einem, zwei oder vier P40 GPUs.
Google Cloud: Compute-Engine-Instanzen mit einem, zwei, vier oder acht V100 GPUs, einem, zwei oder vier P100 GPUs und einem, zwei, vier oder acht K80 GPUs.
Da NVIDIA GPU Cloud Images Standard Docker-Container sind, können sie auf jedem System, lokal oder remote, mit einer Container Runtime ausgeführt werden. Die Container-Portabilität erleichtert den Aufbau hybrider Data-Science-Plattformen. Auf diesen können Entwickler Modelle auf lokalen Systemen generieren, trainieren und testen und dann produktive Modelle für Cloud-GPU-Instanzen bereitstellen.
Mehr Data-Science-Optionen mit Containern
Data-Science-Anwendungen verwenden oft sehr große Datensätze für das Modelltraining. Sie werden zudem oft parallel eingesetzt, um Datenströme in Echtzeit zu analysieren. Das macht sie besonders gut für Containerisierung geeignet, da die Modelle auf einem ganzen Cluster von Maschinen laufen können.
Darüber hinaus können Unternehmen Container Orchestrator wie Kubernetes so konfigurieren, dass sie Workloads automatisch nach oben und unten skalieren, um sie der Nutzung anzupassen. Außerdem kann Kubernetes mittlerweile Workloads auf gemischten Clustern planen. Diese enthalten sowohl GPU- als auch Nicht-GPU-Knoten, und leiten die Data Science Workloads an diejenigen mit GPUs weiter. Einige Cloud-Dienste, wie die Google Kubernetes Engine, unterstützen dieses Feature ebenfalls.
Docker Hub enthält ebenfalls Container-Images, die die Data Science Frameworks ergänzen. Viele von ihnen kommen bereits mit den notwendigen GPU-Treibern und -Bibliotheken an Bord. Im Gegensatz zu NVIDIA GPU Cloud ist die Qualität dieser Images leider nicht bekannt, da Experten sie nicht kuratieren. Auch die Frameworks selbst sind wahrscheinlich nicht für GPUs angepasst und optimiert. Und wenn doch, dann entsprechen sie nicht den von NVIDIA gesetzten Standards.
Folgen Sie SearchDataCenter.de auch auf Twitter, Google+, Xing und Facebook!