
kentoh - Fotolia
Funktionsweise und Konfiguration von Proactive High Availability in vSphere 6.5
vSphere 6.5 enthält einige neue Funktionen zum Ressourcen-Management. Vor allem Proactive HA und Predictive DRS versprechen große Vorteile.

Zusammen mit Updates für den Distributed Resource Scheduler (DRS) und Fault Tolerance (FT) bringt vSphere 6.5 auch die neue Funktion Proactive High Availability, mit der sich das Ressourcen-Management mit vSphere weiter verbessern lässt. Diese neue Version von vSphere High Availability arbeitet mit vSphere DRS und Agents verschiedener Hardwarehersteller zusammen, um virtuelle Maschinen von Hosts zu evakuieren, noch bevor überhaupt ein Problem auftritt.
Man denke zum Beispiel an Szenarien, in denen Hardwaresensoren einen Alarm auslösen, weil eine der beiden Stromversorgungen im Server-Rack ausgefallen ist oder ein CPU-Lüfter nicht mehr arbeitet. In beiden Fällen könnte man den Server natürlich auch weiterbetreiben, aber die Wahrscheinlichkeit eines Ausfalls ist in diesen Fällen deutlich höher.
Wer auf Nummer sicher gehen will, der sollte die auf diesem Server ausgeführten virtuellen Maschinen aber lieber auf einen weniger angeschlagenen Host migrieren. Damit besteht zum Beispiel auch die Möglichkeit, den Hardwarefehler zu beseitigen und den Server anschließend wieder in Betrieb zu nehmen – idealerweise ohne, dass Anwender etwas davon bemerken.
Aktivieren von Proactive High Availability in vSphere 6.5
Um die neue Funktion Proactive High Availability aktivieren zu können, muss zunächst vSphere DRS auf dem Cluster aktiv sein, weil DRS über vMotion die Migration der virtuellen Maschinen vornimmt. Zudem wird ein spezieller Agent des jeweiligen Serverherstellers benötigt, beispielsweise Dell Customized Image of VMware ESXi 6.5. Nur über diesen Agent ist das proaktive Überprüfen der Hardware möglich, entsprechende Agents sind bereits oder werden noch von anderen Herstellern verfügbar.
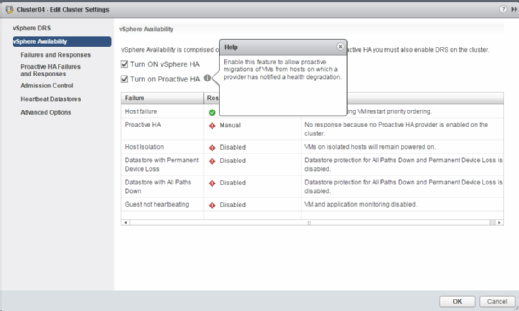
Im Menüpunkt vSphere Availability lässt sich anschließend das Verhalten definieren, wenn Hardwareprobleme erkannt werden. Wie Abbildung 2 zeigt, gibt es für Proactive HA zwei mögliche Quarantänemodi. Abhängig von der Schwere des erkannten Problems lässt sich der Hosts im Notfall auch weiterbetreiben, allerdings nur, wenn sonst DRS-Affinitätsregeln verletzt werden müssten.
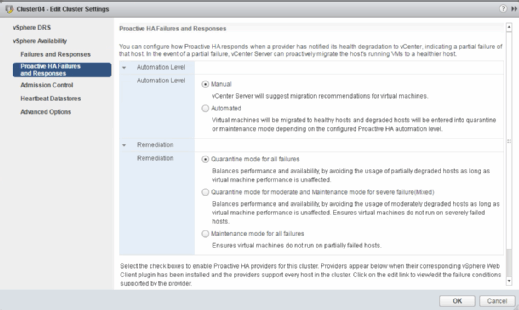
Wenn es keine Affinitätsregeln gibt und alle virtuellen Maschinen auf allen Hosts ausgeführt werden können, dann wird Proactive HA die Migration auch in diesem Fall vornehmen. Die zweite Quarantäneoption versetzt den Host in den Wartungsmodus, wodurch virtuelle Maschinen immer auf andere Hosts migriert werden, falls ein Hardwarealarm ausgelöst wird.
Predictive DRS ermöglicht Proactive HA auf Cluster-Ebene
vSphere HA ist dabei nicht das einzige Tool mit proaktiven Hochverfügbarkeitsfunktionen: DRS kann entsprechende Maßnahmen auch auf Cluster-Ebene ergreifen. Zusammen mit vRealize Operations (vROps) kann vSphere DRS auf Basis historischer Verlaufsdaten des bisherigen Betriebs Lastspitzen vorhersagen und so Vorkehrungen treffen, beispielsweise die VM-Migration auf andere Hosts, um Lastspitzen proaktiv abzufedern, noch bevor sich diese überhaupt auswirken.
Normalerweise würde DRS erst reaktiv eingreifen, also wenn die Lastspitzen bereits auftreten. Mit der neuen Funktion Predictive DRS bringt VMware gewissermaßen Proactive HA auf die Cluster-Ebene, dabei sammelt vROps bestimmte Kennzahlen der virtuellen Maschinen und nutzt diese zur Berechnung dynamischer Grenzwerte. vROps hatte ein ähnliches Verfahren bereits genutzt, um Systemanomalien aufzuspüren, mit vSphere 6.5 kommt es jetzt aber zum Einsatz, um Lastspitzen beim Ressourcenverbrauch vorhersagen zu können.
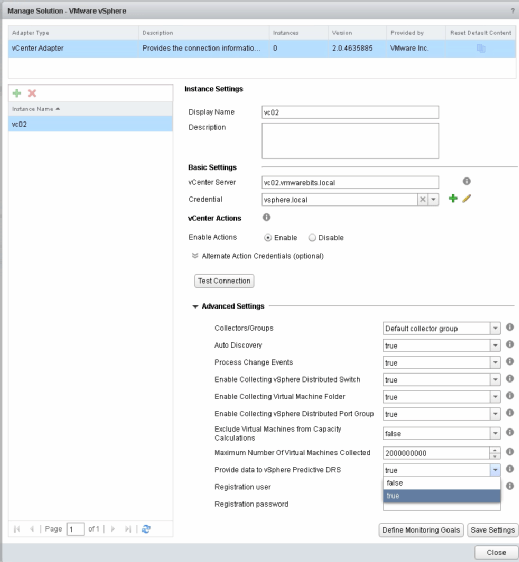
Diese Methode funktioniert dabei am besten in Rechenzentren, in denen das Load Balancing vorhersagbaren Mustern folgt, beispielsweise weil sich die Mitarbeiter alle zur selben Zeit am System anmelden oder ähnliches. Um Proactive HA auch auf Cluster-Ebene nutzen zu können, wird die aktuellste Version von vROps (derzeit Version 6.4) benötigt. Abbildung 3 zeigt die Verbindung zu vCenter Server, wo der gewünschte Cluster ausgewählt wird.
Weitere Neuerungen beim Ressourcen-Management mit vSphere 6.5
Sobald vROps so konfiguriert wurde, dass Daten zu vCenter geschickt werden, lässt sich Predictive DRS auf dem Cluster aktivieren. Anschließend kann man sich zurücklehnen und den Systemen beim Arbeiten zusehen. Wie Proactive HA ist aber auch Predictive DRS eine völlig neue Funktion, ob damit die Verfügbarkeit von Cluster-Ressourcen wirklich verbessert werden kann, muss sich also erst noch zeigen. Wichtig ist zudem, dass Predictive DRS nur für Cluster mit einer maximalen Anzahl von 4.000 virtuellen Maschinen lizenziert werden kann.
Wie Abbildung 4 zeigt, gibt es aber noch drei weitere Funktionen, die mit vSphere 6.5 neu für das Ressourcen-Management per vSphere DRS sind: VM Distribution, Memory Metric for Load Balancing und CPU Over-Commitment.
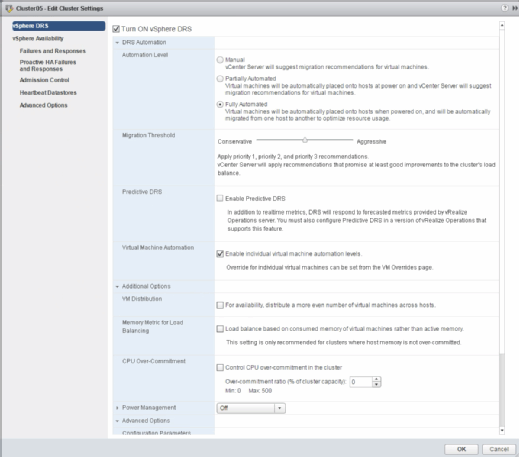
VM Distribution ermöglicht das VM-Balancing auf Cluster-Nodes auf Basis der Anzahl vorhandener virtueller Maschinen statt auf Basis des Ressourcenverbrauchs. Es gibt Szenarien, in denen eine große Gruppe virtueller Maschinen auf wenigen Hosts ausgeführt wird, während auf anderen Hosts nur wenige oder sogar gar keine VMs laufen. So etwas würde passieren, wenn nach einem Serverausfall der Host wieder dem Cluster hinzugefügt wird, aber so viele Ressourcen im Cluster verfügbar sind, dass DRS keine Notwendigkeit zur VM-Migration sieht.
So etwas kommt allerdings nur dann vor, wenn DRS keinen Grund zur VM-Migration sieht. VM Distribution reduziert also die Folgen eines Serverausfalls, falls virtuelle Maschinen gleichmäßig über einen Cluster verteilt sind im Gegensatz zu einer Situation, in der eine große Anzahl virtueller Maschinen auf einem ausgefallenen Host ausgeführt wurden. Diese Funktion ist allerdings dem regulären Load Balancing nachgelagert, virtuelle Maschinen werden also nur dann gleichmäßig verteilt, wenn dabei die Ressourcen-Balance nicht in Mitleidenschaft gezogen wird.
Weitere Artikel zu vSphere 6.5:
Die Neuerungen bei Secure Boot, VIC und vSphere Client
vSphere-Änderungen bei Web Client, CIP und vCSA
Neue Cmdlets für die PowerCLI 6.5
Die beiden letzten neuen Funktionen in vSphere DRS kontrollieren das Load Balancing in Verbindung mit Overcommitment. Memory Metric for Load Balancing ermöglicht die Verwendung von aktuell verwendetem Arbeitsspeicher statt aktivem Arbeitsspeicher. Mit Blick auf die VM-Einstellungen sieht man, dass die meisten VMs ihre gesamten RAM-Ressourcen als derzeit verwendet anzeigen. Per Memory Metric können virtuelle Maschinen auf Basis der RAM-Zuweisung statt der tatsächlich verwendeten RAM-Menge ausbalanciert werden.
Die Funktion CPU Over-Commitment wiederum ermöglicht die Konfiguration eines maximalen vCPU-zu-pCPU-Verhältnisses. Wer diesen Wert beispielsweise auf 200 Prozent setzt, der kann für jeden pCPU zwei vCPUs starten. Der Maximalwert hierfür liegt bei 500 Prozent. Mit dieser Einstellung kann also exzessives CPU-Overcommitment verhindert werden.
Folgen Sie SearchDataCenter.de auch auf Twitter, Google+, Xing und Facebook!





