
Kesu - Fotolia
Die 5 wichtigsten Performance-Befehle für Administratoren
Die Ermittlung von Leistungsproblemen bei Linux-Hosts ist ohne die richtigen Tools zeitaufwändig. Es gibt fünf Befehle, die hier helfen, CPU-, Geräte- und Speicherdaten zu erhalten.
Leistungsmanagement auf Linux-Hosts ist eine Aufgabe, die Zeit, Kenntnisse der Befehlszeilenschnittstelle und ein wenig Intuition erfordert. Als Systemadministrator wagen Sie sich vielleicht nur selten über die wenigen Befehle hinaus, mit denen Sie vertraut sind, oder Sie versuchen, vermeintliche Leistungsprobleme einfach mit mehr Hardware, mehr Speicher und mehr CPU zu lösen.
Fünf einfache Linux-Performance-Befehle können jedoch eine Vielzahl von Details über Ihren Host offenbaren und Ihnen helfen, Ihre Probleme schnell zu lösen.
1. top
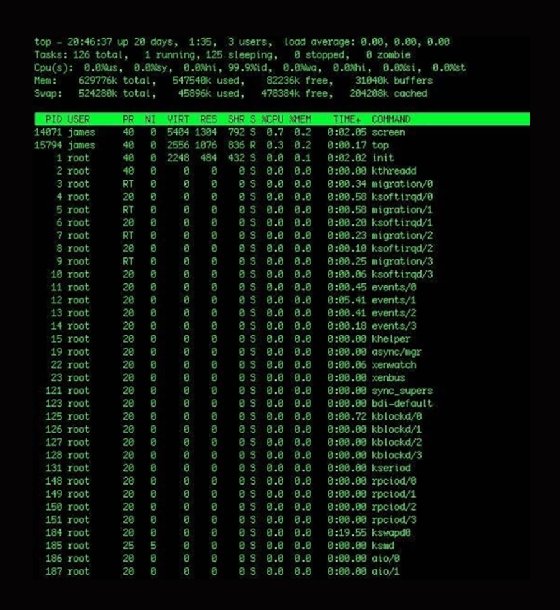
Der Befehl top zeigt an, welche Aufgaben der Kernel derzeit unterstützt, sowie einige allgemeine statistische Daten über den Zustand des Hosts. Der Befehl top aktualisiert diese Daten automatisch alle fünf Sekunden, wenn Sie keinen eigenen Zeitrahmen festlegen.
Dieser Linux-Performance-Befehl ist sehr umfangreich, und Sie werden vielleicht nicht die Hälfte der verfügbaren Funktionen nutzen.
Um top auszuführen, beginnen Sie mit der Taste h, um Hilfe zu erhalten, oder verwenden Sie die man-Seite (man page). Die Hilfe-Eingabeaufforderung zeigt, dass Sie Felder zur Anzeige hinzufügen und von ihr abziehen sowie die Sortierungsreihenfolge ändern können. Mit k und r können Sie auch bestimmte Prozesse beenden oder neu starten.
Der top-Befehl zeigt die aktuelle Betriebszeit, die Systemauslastung, die Anzahl der Prozesse, die Speichernutzung und die Verteilung der CPU-Leistung an. Sie können auch zusätzliche Informationen über jeden Prozess erhalten, einschließlich des Benutzers und aller aktiven Befehle.
2. vmstat
Mit dem Befehl vmstat erhalten Sie eine Momentaufnahme der aktuellen CPU-, I/O-, Prozess- und Speichernutzung. Er wird dynamisch aktualisiert und sieht wie folgt aus:
$ vmstat 10
Diese Version bedeutet, dass Sie alle 10 Sekunden eine Aktualisierung erhalten. Der Befehl vmstat schreibt die Ergebnisse der Überprüfung so lange, bis Sie den Befehl mit Strg+C beenden oder beim Schreiben des Befehls ein Stopp-Limit angeben. Diese kontinuierliche Ausgabe wird manchmal in Dateien geleitet, um die Leistung zu überwachen, aber es gibt zusätzliche Befehle, die große Datenmengen effektiver erfassen können.
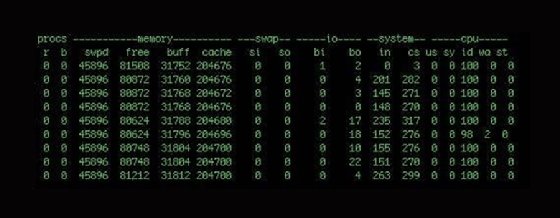
Die ersten beiden Spalten zeigen Prozesse an: Die r-Spalte enthält die Prozesse, die auf ihre Ausführung warten, und die b-Spalte enthält alle Prozesse, die sich im ununterbrochenen Ruhezustand befinden. Wenn Sie hier eine Reihe von Prozessen haben, die warten, bedeutet das, dass Sie wahrscheinlich irgendwo einen Leistungsengpass haben.
Die nächsten vier Spalten zeigen den Speicher: virtueller, freier, Puffer- und Cache-Memory. Die dritte Rubrik, Swap, zeigt die Menge an Memory, die auf und von der Festplatte ausgelagert wird. Die vierte Rubrik ist I/O und enthält Angaben zu empfangenen und gesendeten Blöcken an Blockgeräten.
Die Spalten unter der Überschrift System enthalten die Anzahl der Interrupts und Kontextwechsel pro Sekunde. Die letzten fünf Spalten zeigen System- und CPU-bezogene Informationen an. Die CPU-Spalten zeigen den Prozentsatz der CPU-Zeit an. Die Spalteneinträge sind:
- us: Zeit für die Ausführung von Benutzeraufgaben und Code
- sy: Zeit für die Ausführung von Kernel- oder Systemcode
- id: Leerlaufzeit
- wa: Zeit für das Warten auf I/O
- st: Zeit, die von einer VM gestohlen wurde
Der Linux-Performance-Befehl vmstat hilft Ihnen, CPU-Nutzungsmuster zu erkennen. Denken Sie daran, dass jeder Eintrag in Abhängigkeit von der Verzögerung generiert wird und dass die kurzfristige CPU-Überwachung möglicherweise nicht die beste Informationsquelle für tatsächliche CPU-Probleme ist. Um einen effektiven Einblick in die CPU-Leistung zu erhalten, müssen Sie langfristige Trends sehen.
3. iostat
Der Befehl iostat liefert drei Berichte: CPU-Auslastung, Geräteauslastung und Netzwerk-Dateisystemauslastung.
Wenn Sie den Befehl ohne Anpassungen ausführen, zeigt er alle drei Berichte an; Sie können die einzelnen Berichte mit -c, -d beziehungsweise -h angeben.
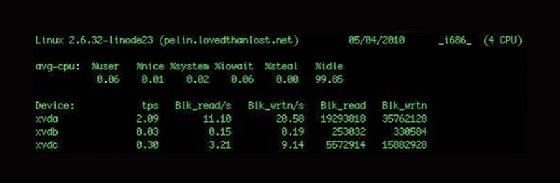
Das obige Beispiel enthält zwei Berichte: CPU- und Geräteauslastung. Der erste Bericht schlüsselt die durchschnittliche CPU-Auslastung nach Kategorien in Prozent auf. Er enthält auch Benutzer- und Systemprozesse sowie I/O-Wartezeiten und Leerlaufzeiten.
Der zweite Bericht zeigt jedes an den Host angeschlossene Gerät an und liefert Informationen über Übertragungen pro Sekunde und Blocklese- und -schreibvorgänge und ermöglicht es Ihnen, Geräte mit Leistungsproblemen zu identifizieren. Mit den Schaltern -k beziehungsweise -m können Sie die Statistiken nicht in Blöcken, sondern in Kilobytes und Megabytes anzeigen.
Der Befehl iostat kann auch die Auslastung des Netzwerk-Dateisystems anzeigen. Obwohl er nicht abgebildet ist, zeigt er ähnliche Informationen wie der Bericht über die Geräteauslastung an, mit Daten über im Netzwerk eingebundene Dateisysteme anstelle von direkt angeschlossenen Geräten.
4. free
Wenn Sie eine Speicherstatistik wünschen, zeigt free Statistiken für den Hauptspeicher und den Swap-Speicher an.
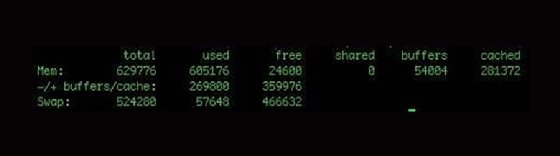
Mit der Eingabe -t können Sie die Gesamtspeichermenge anzeigen. Um die Einheit von den standardmäßigen Kilobytes zu ändern, verwenden Sie -b für Bytes und -m für Megabytes.
Mit -s können Sie free mit einer in Sekunden angegebenen Verzögerung kontinuierlich ausführen:
$ free -s 5
Damit wird die Ausgabe des free-Befehls alle fünf Sekunden aktualisiert.
5. sar
Der Systemaktivitätsbericht (system activity report, sar) ist ein Befehlszeilenwerkzeug zum Sammeln, Anzeigen und Aufzeichnen von Leistungsdaten. Es verfügt über eine Vielzahl von Eingaben zur Anpassung und kann Daten über längere Zeiträume sammeln und anzeigen als andere Leistungsbefehle. Sie können sar ohne Optionen ausführen und erhalten die folgende Ausgabe:
$ sar
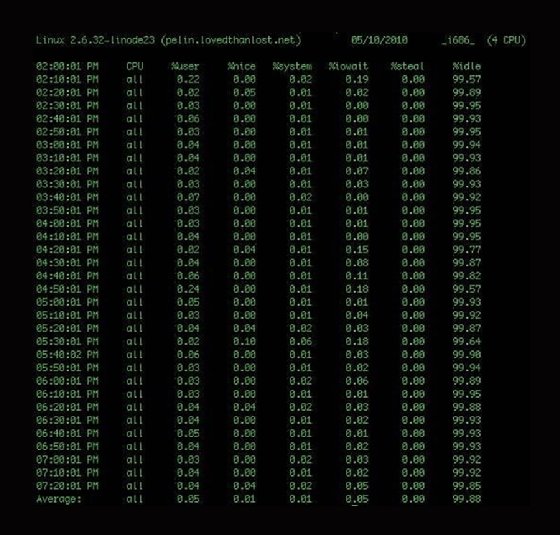
Die einfache sar-Ausgabe enthält CPU-Statistiken für alle 10 Minuten und einen endgültigen Durchschnitt. Dieser Durchschnitt stammt aus einer täglichen Statistikdatei, die das System alle 24 Stunden sammelt und ausgibt. Die Dateien werden im Verzeichnis /var/log/sa/ gespeichert und tragen den Namen saxx, wobei xx für das Erfassungsdatum steht.
Der Befehl sar sammelt auch Statistiken über Memory, Geräte, Netzwerk und Blöcke.
Um festzulegen, welche Daten angezeigt werden sollen, verwenden Sie -b, um Blockgerätestatistiken anzuzeigen, und -n, um Netzwerkdaten anzuzeigen, und letztlich -r, um die Memory-Nutzung anzuzeigen. Sie können auch -A eingeben, um alle gesammelten Daten anzuzeigen.
Sie können sar ausführen und die Daten in eine andere Datei ausgeben, um eine umfangreichere Datensammlung zu erhalten. Dazu fügen Sie -o und den Dateinamen, das Zeitintervall zwischen den Erfassungen und die Anzahl der aufzuzeichnenden Intervalle hinzu. Wenn Sie die Anzahl weglassen, sammelt sar kontinuierlich Daten:
$ sar -A -o /var/log/sar/sar.log 600 >/dev/null 2>&1 &
Hier sammeln Sie alle Daten (-A), protokollieren sie in der Datei /var/log/sar/sar.log, aktualisieren die IT alle fünf Minuten und beenden den Prozess dann im Hintergrund. Wenn Sie diese Daten wieder anzeigen lassen wollen, fügen Sie -f wie folgt hinzu:
$ sar -A -f /var/log/sar/sar.log
Damit werden alle Daten angezeigt, die während der Ausführung des sar-Jobs gesammelt wurden. Sie können sar-Daten auch mit Tools wie ksar auswerten und grafisch darstellen.
Mit dem sar-Tool stehen viele Daten zur Verfügung, und es kann eine leistungsstarke Methode zur Überprüfung der Leistung Ihres Hosts sein. Weitere Einzelheiten finden Sie in der sar-Manualseite.
Zusätzlich zu diesen fünf Befehlen sollten Sie sich Tools wie Munin und collectd ansehen. Diese Ressourcen sammeln Leistungs-, Anwendungs- und Servicedaten, und Sie können Plug-ins angeben. Bei beiden Tools können Sie eine grafische Datenausgabe auswählen und erhalten eine visuelle Darstellung anstelle einer textbasierten Ausgabe.





