
Getty Images
Einstieg in Training und Inferenz in SAP AI Core
SAP AI Core bringt Modelle aus der Entwicklung in den produktiven Einsatz. Datenaufbereitung, Training und Inferenz bilden dabei einen kontrollierten Ablauf.

SAP AI Core übernimmt innerhalb der SAP Business Technology Platform (BTP) die operative Ausführung von Machine-Learning-Workloads und bildet die technische Grundlage für Training, Inferenz und Serving von Modellen.
Der Dienst fungiert als Laufzeitumgebung, in der Machine-Learning-Code (ML) ausgeführt, skaliert und in produktive Prozesse überführt wird. Die eigentliche Modelllogik wird in Python oder anderen Frameworks umgesetzt, anschließend containerisiert und in standardisierte Workflows eingebettet, die reproduzierbar und automatisierbar laufen.
Datenintegration und Vorbereitung als Ausgangspunkt
Die Trainingsphase beginnt in der Datenintegration. In SAP-Umgebungen liegen Daten verteilt über S/4HANA und andere Systeme, teilweise auch extern angebunden. Diese Daten müssen konsolidiert, gefiltert und transformiert werden. SAP Datasphere übernimmt Integration, Transformation und Governance, sodass strukturierte und unstrukturierte Daten für maschinelles Lernen geeignet vorliegen.
Die Verarbeitung umfasst typische Schritte wie Normalisierung numerischer Werte, Kodierung kategorialer Merkmale und Entfernung irrelevanter Attribute. Parallel greifen Sicherheitsmechanismen, die Datenzugriffe einschränken und regulatorische Anforderungen absichern. Für strukturierte Daten kann ein alternativer Ansatz genutzt werden, bei dem Machine Learning direkt auf SAP HANA ausgeführt wird. In diesem Fall verbleiben Daten und Algorithmen in der Datenbank, wodurch Latenz und Datenbewegung reduziert werden.
Training als containerisierte Pipeline
Das eigentliche Training läuft in SAP AI Core als containerisierte Pipeline. Der ML-Code wird in ein Docker-Image verpackt, das alle Abhängigkeiten enthält. Dieses Image wird über eine Workflow-Definition gesteuert, die in Form eines YAML-Dokuments vorliegt. Diese Definition beschreibt die Ausführung sowie die Datenflüsse, Parameter und Artefakte. Die Ausführung erfolgt über Argo-Workflows. Jede Pipeline besteht aus einzelnen Schritten, die als gerichteter Graph organisiert sind. Input-Artefakte, zum Beispiel Trainingsdaten, werden aus einem Object Store geladen und in den Container eingebracht. Der Trainingsprozess verarbeitet diese Daten und erzeugt ein Modell, das als Output-Artefakt wieder in den Object Store geschrieben wird.
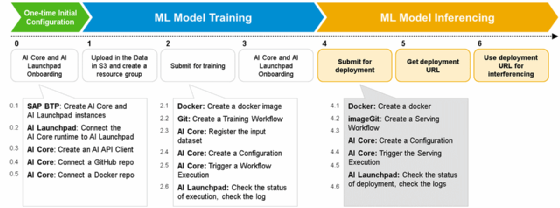
Ein zentrales Element ist die Parametrisierung. Workflow Templates enthalten Platzhalter, die vor der Ausführung gefüllt werden. Parameter wie Modellkonfiguration, Trainingsvarianten oder Hyperparameter lassen sich dadurch dynamisch steuern. Mehrere Trainingsläufe mit unterschiedlichen Parametern können parallel ausgeführt werden, wodurch sich Varianten vergleichen lassen. Die Pipeline wird zunächst als Template registriert. Erst eine konkrete Ausführung erzeugt eine Instanz dieses Templates. Diese Trennung ermöglicht Wiederverwendung, Versionierung und kontrollierte Ausführung.
Pipeline-Orchestrierung, Artefaktflüsse und technische Abhängigkeiten
Ein oft unterschätzter Teil der Architektur liegt in der konkreten Ausführung der Pipelines selbst. SAP AI Core behandelt jede Trainings- oder Inferenzpipeline als Folge einzelner Schritte, die über definierte Artefaktflüsse miteinander verbunden sind. Daten werden gezielt als Input- und Output-Artefakte zwischen Containern transportiert. Ein Trainingslauf beginnt normalerweise mit dem Einlesen eines Datensatzes aus einem Object Store, der in ein fest definiertes Verzeichnis innerhalb des Containers geschrieben wird. Nach der Verarbeitung legt der Container das trainierte Modell wieder in einem festgelegten Pfad ab, von wo aus es automatisiert zurück in den Object Store übertragen wird.
Diese klaren Übergabepunkte sind entscheidend für Reproduzierbarkeit. Jeder Pipeline-Schritt kann unabhängig geprüft und erneut ausgeführt werden, solange die Artefakte verfügbar sind. Gleichzeitig ermöglicht diese Struktur eine Trennung von Verarbeitungsschritten. Datenvorbereitung, Training und Nachverarbeitung lassen sich als separate Container definieren, die in einer festgelegten Reihenfolge oder parallel ausgeführt werden. Die zugrunde liegende Orchestrierung nutzt dafür eine gerichtete Ablaufstruktur, in der Abhängigkeiten explizit definiert sind. Wenn ein Schritt erfolgreich abgeschlossen ist, wird der nächste gestartet.
Ein weiterer technischer Aspekt betrifft die Ausführungsumgebung selbst. Jede Pipeline wird auf einem Cluster ausgeführt, in dem Container dynamisch auf verfügbare Knoten verteilt werden. Die Startzeit einzelner Schritte hängt daher von der aktuellen Auslastung und den verfügbaren Ressourcen ab. Gerade bei mehrstufigen Pipelines mit vielen Abhängigkeiten kann sich diese Initialisierungszeit bemerkbar machen, weshalb solche Workflows nicht für latenzkritische Szenarien gedacht sind. Dafür liegt ihre Stärke in der stabilen Verarbeitung komplexer Abläufe, bei denen mehrere Datenquellen, Modelle und Verarbeitungsschritte zusammengeführt werden.
Diese Kombination aus Artefaktmanagement, klar definierten Abhängigkeiten und containerbasierter Ausführung sorgt dafür, dass auch umfangreiche Trainings- und Batch-Inferenzprozesse kontrolliert und nachvollziehbar ablaufen. Gleichzeitig bleibt die Struktur flexibel genug, um neue Schritte oder Varianten ohne grundlegende Änderungen an der Pipeline zu integrieren.
Integration von Datenbanken und externen Systemen
Ein Beispiel zeigt die Integration mit SAP HANA Cloud. Ein Skript kann sich über Credentials, die als Secret in AI Core hinterlegt sind, mit der Datenbank verbinden. Der Code greift auf vorbereitete Views zu, führt dort Machine-Learning-Algorithmen aus und speichert das Modell direkt in der Datenbank. Die Berechnung erfolgt im Datenbanksystem selbst, wodurch keine Daten verschoben werden müssen.
Diese Architektur erlaubt es, Datenquellen flexibel zu wählen. Neben SAP-Systemen lassen sich externe Object Stores oder Cloud-Dienste anbinden. Trainingsdaten können aus S3 Buckets geladen werden, Modelle werden dort versioniert gespeichert. Voraussetzung ist die Definition eines Standard-Object-Stores, da ohne diesen kein Training ausgeführt wird.
MLOps und Lebenszyklussteuerung
SAP AI Core integriert MLOps-Funktionalität direkt in die Plattform. Code und Workflow-Definitionen liegen in Git-Repositories und werden über eine GitOps-Logik synchronisiert. Änderungen im Repository führen zu neuen Pipelineversionen, die automatisch erkannt und ausgeführt werden können.
Trainingsläufe erzeugen Metriken, die im SAP AI Launchpad sichtbar sind. Genauigkeit, Fehlerquoten oder Regressionswerte dienen als Grundlage für Entscheidungen über Modellfreigaben. Mehrere Modellversionen können parallel existieren, wodurch ein Vergleich möglich wird.
Ein Aspekt ist Automatisierung. Trainingspipelines lassen sich zeitgesteuert ausführen. Neue Daten fließen in das Modell ein, ohne dass manuelle Eingriffe erforderlich sind. Diese kontinuierliche Aktualisierung ist notwendig, da sich Datenmuster im Betrieb verändern und Modelle sonst an Aussagekraft verlieren.
Deployment und Serving als API
Nach dem Training wird das Modell in eine produktive Laufzeit überführt. SAP AI Core stellt dafür ServingTemplates bereit, die definieren, wie ein Modell als Service betrieben wird. Diese Templates beschreiben Container, Ressourcen und Skalierungsparameter. Der eigentliche Serving-Prozess basiert auf einer Webanwendung, die als Container läuft. Diese Anwendung stellt einen HTTP-Endpunkt bereit. Eingehende Anfragen enthalten Daten, die vom Modell verarbeitet werden. Die Anwendung lädt das Modell aus dem Object Store oder einer Datenbank, führt die Vorhersage aus und gibt das Ergebnis zurück.
Ein typischer Ablauf beginnt mit einem POST-Request an einen definierten Endpunkt. Die Anwendung extrahiert die Eingabedaten, transformiert sie in das benötigte Format und führt die Modellberechnung durch. Die Antwort wird strukturiert zurückgegeben und kann direkt in Anwendungen integriert werden. Die Skalierung erfolgt über Kubernetes. Steigt die Anzahl der Anfragen, werden zusätzliche Instanzen des Model-Servers gestartet. Sinkt die Last, werden Ressourcen reduziert. Eine spezielle Funktion erlaubt das vollständige Herunterfahren ungenutzter Instanzen, wodurch Kosten nur bei tatsächlicher Nutzung entstehen.
Inferenz und Laufzeitverhalten
Inferenz beschreibt die produktive Nutzung eines Modells zur Verarbeitung neuer Daten. SAP AI Core unterstützt sowohl Echtzeit- als auch Batch-Inferenz. Echtzeit-Inferenz verarbeitet einzelne Anfragen unmittelbar über API-Endpunkte. Batch-Inferenz verarbeitet größere Datenmengen in geplanten Intervallen.
Ein konkretes Szenario zeigt die Echtzeitverarbeitung mit SAP HANA: Eine Anfrage trifft am API-Endpunkt ein, wird in eine temporäre Tabelle geschrieben und anschließend durch das Modell verarbeitet. Nach der Berechnung wird das Ergebnis zurückgegeben und die temporäre Struktur entfernt. Die Verbindung zur Datenbank bleibt bestehen und wird für weitere Anfragen wiederverwendet.
Der Zugriff erfolgt über standardisierte API-Aufrufe. Anwendungen senden HTTP-Requests an den Deployment-Endpunkt. Authentifizierung erfolgt über Tokens, die aus Service-Keys generiert werden. Der Zugriff lässt sich über verschiedene Clients realisieren, darunter Software Development Kits (SDK), Postman oder eigene Anwendungen.
Training und Inferenz benötigen unterschiedliche Ressourcenprofile. SAP AI Core stellt dafür Resource Plans bereit. Kleine Modelle laufen auf CPU-basierten Instanzen, komplexe Modelle nutzen GPU-Ressourcen. Diese Auswahl beeinflusst Trainingsdauer, Inferenzlatenz und Kostenstruktur. Für rechenintensive Szenarien bietet sich eine hybride Architektur an. Modelle werden extern auf GPU-optimierten Plattformen trainiert und anschließend in SAP AI Core bereitgestellt. Dadurch lassen sich Trainingszeiten reduzieren, ohne die Integration in SAP-Prozesse zu verlieren.
Integration in Geschäftsprozesse
Die eigentliche Wirkung entfaltet sich durch Integration. SAP AI Core stellt eine standardisierte API bereit, über die Anwendungen Modelle konsumieren. S/4HANA sendet Daten an Modelle und erhält Vorhersagen, die direkt in Prozesse einfließen. So gehen auch andere SAP-Dienste vor.
Neben synchronen API-Aufrufen gibt es noch ereignisgesteuerte Szenarien. Modelle werden durch Geschäftsereignisse ausgelöst und liefern Ergebnisse, die automatisch weiterverarbeitet werden. Diese Integration ermöglicht die Automatisierung komplexer Prozesse, ohne dass separate Systeme erforderlich sind.
Betrieb, Monitoring und kontinuierliche Anpassung
Nach dem Deployment beginnt der eigentliche Betrieb. Modelle werden kontinuierlich überwacht, um Abweichungen zu erkennen. Genauigkeit, Antwortzeit und Fehlerquote werden mit weiteren Kennzahlen erfasst und analysiert. Sinkt die Qualität, wird ein Retraining ausgelöst. Versionierung spielt dabei eine zentrale Rolle. Neue Modelle werden zunächst getestet und erst danach produktiv geschaltet. Bei Problemen kann jederzeit auf eine vorherige Version zurückgegriffen werden.
Kostenkontrolle erfolgt über Monitoring der Ressourcennutzung. Echtzeitmodelle benötigen stabile Laufzeiten, Batch-Prozesse lassen sich zeitlich optimieren. Die Kombination aus Skalierung und Ressourcenkontrolle ermöglicht einen wirtschaftlichen Betrieb auch bei hoher Last.
Sicherheit, Zugriffskontrolle und isolierte Ausführung von KI-Workloads
Ein zentraler Aspekt im produktiven Einsatz von SAP AI Core liegt in der kontrollierten Ausführung von Workloads innerhalb isolierter Umgebungen. Jede Pipeline und jeder Serving-Dienst läuft in einem klar abgegrenzten Kontext, der über Resource Groups strukturiert wird. Diese logische Trennung sorgt dafür, dass Modelle, Daten und Ausführungen voneinander isoliert bleiben und sich unterschiedliche Projekte oder Mandanten nicht gegenseitig beeinflussen. Innerhalb dieser Struktur greifen rollenbasierte Zugriffskonzepte, die festlegen, welche Benutzer Trainings starten, Deployments ändern oder Inferenz-Endpunkte aufrufen dürfen.
Zugriffe auf externe Systeme erfolgen über hinterlegte Secrets, die zur Laufzeit in Container injiziert werden. Dazu gehören Datenbankzugänge, API-Schlüssel oder Object Store Credentials. Diese Trennung zwischen Code und Zugangsdaten reduziert das Risiko von Leaks und erleichtert die Verwaltung sensibler Informationen. Gleichzeitig lässt sich steuern, welche Pipeline Zugriff auf welche Ressourcen erhält, wodurch eine granulare Sicherheitsarchitektur entsteht.
Ein Punkt betrifft die Netzwerkkommunikation. In produktiven Szenarien sind Inferenz-Endpunkte nicht direkt aus Frontend-Anwendungen erreichbar. Zwischen Client und Modell-Serving liegt eine zusätzliche Anwendungsschicht, die Anfragen validiert, transformiert und autorisiert weiterleitet. Diese Architektur verhindert direkte Zugriffe auf interne Endpunkte und reduziert typische Risiken sowie CORS-Probleme oder unkontrollierte API-Nutzung.
Auch die Nachvollziehbarkeit von Entscheidungen spielt eine Rolle. Jede Ausführung einer Pipeline und jede Inferenz-Anfrage lässt sich über Logs und Metadaten rekonstruieren. Diese Transparenz ist Voraussetzung für Audits und regulatorische Anforderungen, da sich jederzeit nachvollziehen lässt, welches Modell in welcher Version mit welchen Parametern eingesetzt wurde.
Fazit
Training, Inferenz und Modell-Serving bilden in SAP AI Core eine durchgängige Kette. Daten werden integriert, Modelle in reproduzierbaren Pipelines trainiert, als Container bereitgestellt und über APIs konsumiert. Argo-Workflows steuern die Abläufe, Kubernetes übernimmt Skalierung, KServe stellt die Endpunkte bereit.
Die Plattform verbindet offene Technologien mit SAP-Integration und ermöglicht es, individuelle Modelle in bestehende Geschäftsprozesse einzubetten. Dadurch lassen sich datengetriebene Entscheidungen direkt im operativen System umsetzen, ohne separate Infrastrukturen oder komplexe Integrationsschichten.






