
sdecoret - stock.adobe.com
Fünf Gründe, warum künstliche Intelligenz Kontext braucht
Das Potential von KI ist noch lange nicht ausgeschöpft. Allerdings sind technische und ethische Standards notwendig. Graphtechnologie liefert dazu den nötigen Datenkontext.
Künstliche Intelligenz (KI) kommt heute dort zum Einsatz, wo klar definierte Aufgaben zu bewältigen sind. Bei komplexeren Aufgaben, die ein Abwägen zwischen mehreren Möglichkeiten erfordern, haben KI-Lösungen noch zu kämpfen. Soll KI in Zukunft Entscheidungen selbstständig treffen und situationsbezogen handeln, müssen die Systeme auf einen umfassenden Kontext an Daten zurückgreifen können. Ähnlich dem Menschen, der bei Entscheidungen bewusst oder unbewusst auf seine Erfahrung und sein Wissen setzt.
Risiken zusammenhangsloser KI
Fehlt der Kontext ist künstliche Intelligenz auf strikte Regeln angewiesen und bleibt auf spezifische Anwendungen beschränkt. Doch nicht nur das. Die Praxis hat gezeigt, dass der Einsatz von KI kontraproduktiv und sogar gefährlich sein kann, wenn der Entscheidungsweg von Maschinen nicht mehr nachvollziehbar ist oder die Algorithmen mit falschen Daten arbeiten.
Der Microsoft Twitter-Bot Tay beispielsweise sollte in der Interaktion mit realen Nutzern der Social-Media-Plattform lernen, wie man twittert. Das Ergebnis waren Tweets, gespickt mit Hasssprache und rassistischen Beleidigungen. Das KI-gestützte Recruiting-Tool von Amazon musste abgeschaltet werden, nachdem es sich gegenüber weiblichen Bewerbern voreingenommen zeigte. In beiden Fällen wurden die Machine-Learning-Modelle auf Basis von Daten trainiert, denen ein ausgewogener Kontext fehlte. Das Modell von Tay griff vor allem laute und schockierende Tweets auf und fasste diese als Norm auf. Das HR-Tool von Amazon verstärkte und kodifizierte diskriminierende Praktiken, die sich in dem vorhandenen, sehr kleinen Datensatz abzeichneten.
Die Frage lautet nicht nur, wie sich solche Fehler verhindern, sondern auch, wie sie sich überhaupt erkennen lassen. Woran lässt sich feststellen, ob eine KI-Lösung suboptimale, falsche oder sogar schlechte Entscheidungen trifft? Wird so lange abgewartet, bis etwas passiert? Um zu verstehen, ob und wann ein KI-Projekt aus dem Ruder läuft, ist ein größerer Bezugsrahmen erforderlich, der transparent darlegt, wie Millionen von Datenpunkten miteinander verknüpft sind und wie die Zusammenhänge abgefragt werden.
Der Datenkontext ist entscheidend, damit KI-Systeme nicht nur effektiv arbeiten, sondern dabei auch ethische Grundsätze in ihren Analysen folgen. Wie sich solche Standards umsetzen lassen, zeigen folgende Beispiele.
Höhere Genauigkeit durch Graphalgorithmen
Eine der größten Herausforderungen beim Training von Machine-Learning-Modellen ist das Sammeln ausreichender und relevanter Daten. Vor allem die Beziehungen zwischen den Daten bleiben bei vielen KI-Lösungen noch immer außen vor. Doch genau in den vielfältigen und komplexen Beziehungen entfaltet sich ein relevanter Datenkontext.
Zur Abbildung und Abfrage vernetzter Daten kommt daher verstärkt Graphtechnologie zum Einsatz. Graphdatenbanken sind so konzipiert, dass sie den Beziehungen zwischen den Daten denselben Stellenwert einräumen wie den Daten selbst. Die Daten und Beziehungen werden dabei nicht in ein vordefiniertes Modell eingezwängt, sondern realitätsnah abgebildet – in Knoten und Kanten, die zeigen, wie jede einzelne Entität mit anderen in Verbindung steht (siehe Abbildung 1).
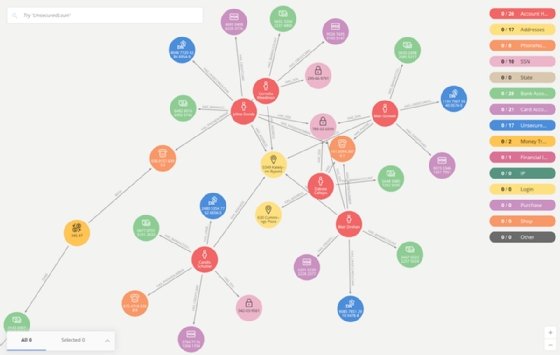
Graphalgorithmen wiederum sind speziell darauf ausgerichtet, die Topologie dieses Datenmodells abzufragen: Sie decken Gemeinsamkeiten und Gruppen auf (Community Detection), erkennen einflussreiche Entitäten (PageRank) oder finden die kürzeste Verbindung zwischen Datenpunkten (Shortest Path). Die Algorithmen identifizieren zudem prädiktive Parameter, sogenannte Graph Features, die als Knoten-Kanten-Modell dem Graphen hinzugefügt werden und bei allen weiteren Abfragen in die Analyse einfließen. Die zusätzlichen Regeln und Suchkriterien verbessern kontinuierlich die Genauigkeit – ohne das zwangsläufig neue Daten hinzugefügt werden müssen.
Situative Flexibilität – Lernen aus Interaktionen
KI-basierte Systeme müssen flexibel auf unterschiedliche Situationen reagieren können. Die Interaktion mit den Anwendern spielt hier eine wesentliche Rolle und muss beim Design und bei der Implementierung von autonomen Systemen immer mitgedacht werden. Eine Verkaufskraft im Einzelhandel spricht mit einem siebenjährigen Kind anders als mit dessen Eltern. Ähnlich muss auch ein Chatbot im Online-Shop auf unterschiedliche Bedürfnisse eingehen können. Kontextinformationen helfen KI-Lösungen, sich in Situationen zurechtzufinden, für die sie nicht trainiert wurden. Dazu gehören auch Lösungswege, die sich in der Vergangenheit als richtig erwiesen haben und als Lessons Learned herangezogen werden können.
Zuverlässigkeit dank Data Lineage
Um die Verlässlichkeit von KI-Lösungen zu überprüfen und zu bewerten, muss klar sein, mit welchen Daten die Machine-Learning-Modelle trainiert wurden und warum. Bei den Datenlawinen, die sich heute ihren Weg durch Unternehmen bahnen, gleicht die Herkunftsbestimmung und Rückverfolgung jedoch einer Herkulesaufgabe. Unternehmen wie Facebook verfügen über gigantische Datenmengen. Umso schwieriger ist es nachzuvollziehen, auf welche Informationen die Algorithmen zurückgreifen, wenn sie Freundschaftsempfehlungen ausspucken oder die Posts für den News-Feed auswählen.
Graphen bieten hier durch ihr Datenmodell mehr Transparenz als andere Datenbanksysteme. Die Abbildung von Datenbeziehungen macht es möglich, Änderungen nachzuvollziehen und einzusehen, welche Algorithmen welche Daten heranziehen. Aus diesem Grund wird Graphtechnologie oft im Rahmen der Data Lineage eingesetzt. Zum Beispiel um personenbezogene Daten über alle Systeme hinweg nachzuverfolgen und EU-DSGVO-Datenschutzbestimmungen zu erfüllen.
Die freie Sicht auf komplexe Datenbeziehungen bietet zudem einen gewissen Schutz vor Manipulationen. In der Betrugsaufdeckung ist bekannt, dass Kriminelle Daten gezielt verändern, hinzufügen oder entfernen, um Algorithmen auszutricksen, Ergebnisse zu verfälschen und illegale Machenschaften zu verschleiern. Fehlt das Vertrauen in die Qualität der Daten ist es jedoch auch um die Zuverlässigkeit der KI-Lösungen nicht gut bestellt.
Mehr Datenschutz, weniger Diskriminierung
Je größer und vielfältiger der Datenkontext, desto geringer ist das Risiko, mögliche Verzerrungen innerhalb bestehender Datensätze unreflektiert in die KI-Analyse zu übernehmen. Bei einer Simulationsanalyse eines prädiktiven Fahndungstools für die Polizei fanden Datenanalysten heraus, dass das Machine-Learning-Modell die offensichtlichen Stereotypen und Vorurteile in den historischen Daten nicht korrigiert, sondern diese verstärkte.

„Die Verknüpfung von heterogenen Daten im Graphen schafft den Kontext, der für die Einhaltung von Ethikleitlinien notwendig ist.“
Amy E. Hodler, Neo4j
Kontextbasierte KI-Lösungen könnten sich auch positiv auf den Datenschutz auswirken. Statt personenbezogene Daten zu sammeln und auszuwerten, können die Systeme allein aus bestehenden Datenbeziehungen wertvolle Informationen extrahieren. Studien haben gezeigt, dass wenige bis gar keine persönlichen Informationen nötig sind, um ein Verhalten vorherzusagen. Es genügt völlig, das soziale Netzwerk einer Person zu kennen und die gegenseitigen Interaktionen zu analysieren. Dies deckt sich mit der Ankündigung von Google, das individuelle Tracking von Nutzern abzuschaffen. Zukünftig sollen Anwender als Gruppen zusammengefasst und Werbeanzeigen basierend auf Federated Learning of Cohorts (FLoC) an die Internet-User ausgestrahlt werden.
Transparenz schafft Vertrauen
KI darf keine Black Box sein. Das Vertrauen in Predictive Analytics und Empfehlungen steht und fällt mit dem Verständnis darüber, wie das System arbeitet. Analysen müssen für Data Scientists interpretierbar und für den Anwender erklärbar bleiben. Andernfalls werden Ergebnisse als kontraintuitiv abgelehnt. Eine wichtige Rolle kommt hier der Visualisierung der Daten zu. Anschaulichkeit und eine einfache wie realitätsnahe Abbildung können die Benutzerfreundlichkeit von KI-Lösungen deutlich steigern und viel zur Akzeptanz beitragen.
Deutlich wird dies unter anderem bei Empfehlungsmaschinen, zum Beispiel auf Streaming Plattformen wie Spotify oder Netflix. Die Systeme lernen nicht mehr nur auf Basis einzelner Daten (zum Beispiel ausgewählter Song oder Film), sondern auch über den Weg, den ein Kunde auf der Suche einschlägt – von Lied zu Künstler zu Album zu Genre. Im Graphen sind diese Beziehungen offensichtlich und können von den Algorithmen in jede beliebige Richtung in Echtzeit abgefragt werden. Dabei wird die Wahrscheinlichkeit verschiedener Pfade mit zusätzlichem Kontext angereichert, um KI-gestützte Empfehlungen und automatisierte Playlisten zielgenauer zu erstellen.
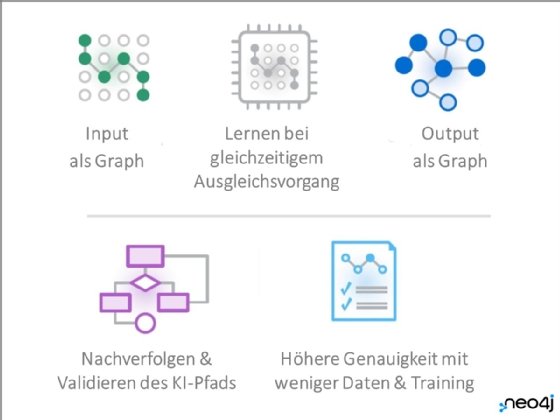
Graph Native Learning
Die Verknüpfung von heterogenen Daten im Graphen schafft den Kontext, der für die Einhaltung von Ethikleitlinien notwendig ist. Je größer der Kontext und je dynamischer das Backend, desto weiter öffnet sich auch das Einsatzgebiet für KI. Graph Native Learning ermöglicht es, auf Basis vernetzter Daten Machine-Learning-Modelle zu erstellen und die Ergebnisse im gleichen intuitiven Modell des Graphen auszugeben. Jeder Lernschritt wird damit nachvollziehbar und kann von Data Scientists und KI-Experten validiert werden, ehe er in ein neues Klassifizierungsmodell überführt wird. Eine wichtige Sicherheitsvorkehrung, um das Misstrauen gegenüber KI und die Risiken von KI proaktiv anzugehen.
Über den Autor:
Amy E. Hodler ist Director Graph Analytics & AI Programs bei Neo4j.
Die Autoren sind für den Inhalt und die Richtigkeit ihrer Beiträge selbst verantwortlich. Die dargelegten Meinungen geben die Ansichten der Autoren wieder.






