
Asynchrone Replikation unter Apache Pulsar implementieren
Das Streaming-Tool Apache Pulsar bietet verschiedene Replikationsverfahren an, mit denen Streaming-Umgebungen vor unerwarteten Serviceunterbrechungen geschützt werden können.
In COVID-19-Zeiten ist Streaming in Freizeit und Beruf zum täglichen Standard geworden. Immer öfter wird für Streaming-Aufgaben auch die Cloud-native verteilte Messaging- und Streaming-Plattform Apache Pulsar eingesetzt.
Doch wie sorgt man dafür, dass Streaming-Dienste reibungslos funktionieren? Eine wichtige Maßnahme, die dazu beiträgt, dass keine Daten verloren gehen und Dienstunterbrechungen ausbleiben, ist die asynchrone Replikation.
Asynchrone Geo-Replikationsverfahren in Apache Pulsar
Mit asynchroner Replikation bietet Pulsar seinen Anwendern viel Flexibilität, um ihre Replikationsstrategien nach eigenem Gusto zu gestalten. Das heißt, dass eine Applikation aktiv-aktive und vermaschte (Full-mesh) Replikation nutzen kann, eine Replikation im Aktiv-Standby-Modus und aggregierte Replikation über mehrere Rechenzentren hinweg. Doch wie implementiert man jedes dieser Verfahren in Apache Pulsar?
Multi-aktive Georeplikation
Die asynchrone Georeplikation wird in Pulsar für jeden Kunden separat gesteuert. Deswegen kann dieses Verfahren nur dann zwischen Clustern angeschaltet werden, wenn ein Kunde eingerichtet wurde, der Zugriff auf beide teilnehmenden Cluster hat.
Um die Multi-aktive Georeplikation einzurichten, muss man über die Pulsar-Administratorbefehlszeile spezifizieren, welcher Cluster wohin Zugriff hat, hat wie Listing 1 das zeigt. Das Listing zeigt den Befehl, der einen neuen Kunden einrichtet und ihm erlaubt, ausschließlich auf die Cluster US-East und US-West zuzugreifen.
Listing 1: Cluster-Zugriffsfreigabe für einen Kunden
$ /pulsar/bin/pulsar-admin tenants create customers \ #A --allowed-clusters us-west,us-east \ #B --admin-roles test-admin-role
#A: Einrichtung und Benennung des neuen Kunden
#B: Zugriffsfreigabe für diesen Kunden und die betreffenden zwei Cluster.
Nach der Einrichtung des Kunden wird die Georeplikation auf der Ebene des Namensraums definiert. Dafür erzeugt man zunächst einen Namensraum über die Administrationsbefehlszeile von Pulsar und weist den Namensraum einem oder mehreren Clustern zu. Dazu dient der Befehl set-clusters. Die Befehlssequenz ist in Listing 2 dargestellt.
Listing 2: Zuweisung eines Namensraumes an einen Cluster
$ /pulsar/bin/pulsar-admin namespaces create customers/orders $ /pulsar/bin/pulsar-admin namespaces set-clusters customers/orders \ --clusters us-west,us-east,us-central
Standardmäßig werden alle Messages, die sich auf Themen innerhalb des Namensraumes eines Clusters beziehen, nach der Konfiguration der Replikation zwischen zwei oder mehr Clustern asynchron an alle Cluster in der Liste repliziert. Daher ist das Standardverhalten im Grunde eine voll vermaschte Replikation aller Themen im Namensraum, wobei die Nachrichten in verschiedenen Richtungen publiziert werden.
Sind nur zwei Cluster vorhanden, kann man das Standardverhalten mit dem einer Aktiv-Aktiv-Clusterkonfiguration vergleichen. Darin stehen die Daten auf beiden Clustern, die Clients bedienen, zur Verfügung. Falls einer der Cluster ausfällt, werden alle Clients unterbrechungsfrei auf das verbleibende aktive Cluster umgeleitet.
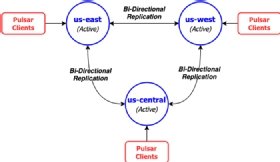
Neben der voll vermaschten Aktiv-Aktiv-Georeplikation gibt es einige andere Replikationsmuster, die einsetzbar sind, beispielsweise Aktiv-Standby. Dieses Replikationsverfahren wird vor allem bei der Disaster Recovery verwendet.
Aktiv-Standby-Georeplikation
Hier wird eine aktuelle Kopie des Clusters an einem anderen geografischen Ort vorgehalten. Bei einem Ausfall kann der Betrieb dann mit sehr geringen Daten- oder Zeitverlusten wieder aufgenommen werden.
Da Pulsar keinerlei Funktionen anbietet, um die einseitige Replikation von Namensräumen durchzuführen, lässt sich dieses Verfahren nur implementieren, indem die Clients auf ein einziges Cluster beschränkt werden. Man bezeichnet ihn als das „aktive“ Cluster.
Auf das Standby-Cluster wird ausschließlich bei Ausfällen umgeleitet. Typischerweise geschieht das mit Hilfe eines Load Balancers oder anderen Mechanismen auf der Netzwerkebene. Sie machen den Übergang für die Clients transparent (siehe Abbildung 2). Pulsar-Clients veröffentlichen Messages an das aktive Cluster, die dann zu Sicherungszwecken auf das Standby-Cluster repliziert werden.
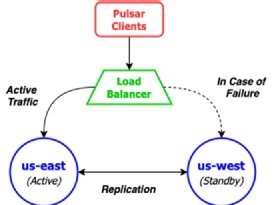
Dabei werden die Pulsar-Daten noch immer bidirektional repliziert. Das bedeutet, dass der US-West-Cluster versuchen wird, die Daten, die er bei einem Ausfall empfängt, an den US-Ost-Cluster zu schicken. Das kann problematisch sein, wenn eine oder mehrere Komponenten des Pulsar-Clusters ausgefallen sind, das Netz des US-Ost-Clusters nicht erreichbar ist oder Ähnliches. Daher sollten man selektiven Replikationscode zu den Pulsar-Produzenten hinzufügen. So lässt sich verhindern, dass der US-West-Cluster versucht, Nachrichten zum US-East-Cluster zu replizieren, der sehr wahrscheinlich ausgefallen ist.
Die Replikations-Selektivität lässt sich begrenzen, indem eine Replikationsliste für eine Nachricht auf der Applikationsebene geschrieben wird. Ein Beispiel dafür zeigt Listing 3. Hier wird eine Nachricht produziert, die nur an den US-West-Cluster repliziert wird. Das ist genau das Verhalten, das im Aktiv-Standby-Szenario erwünscht ist.
Listing 3: Selektive Replikation einzelner Nachrichten
ListrestrictDatacenters = Lists.newArrayList("us-west"); Message message = MessageBuilder.create() … .setReplicationClusters(restrictDatacenters) .build(); producer.send(message);
Manchmal sollen Messages aus mehreren Clustern an einem Ort konsolidiert werden. Ein Beispiel ist die Zusammenführung der Zahlungsdaten aus allen geografischen Regionen für die Sammlung, Weiterverarbeitung und andere Aktionen.
Aggregierende Georeplikation
Angenommen, es existieren drei Cluster, die jeweils aktiv Kunden ihrer Region bedienen. Daneben gibt es ein viertes Pulsar-Cluster mit der Bezeichnung „Intern“, das komplett vom Web abgeschottet ist und auf das nur interne Mitarbeiter zugreifen können.
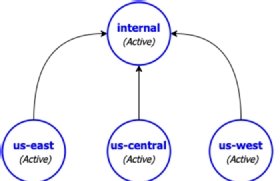
Dort werden die Daten aller Pulsar-Cluster gesammelt (aggregate), die Kunden bedienen (siehe Abbildung 3). Um die aggregierende Georeplikation zwischen diesen vier Clustern einzurichten, braucht man die Befehle in Listing 4. Sie erzeugen zunächst einen Kunden „E-Payments“ auf dem zentralen Server und erlauben dann allen Clustern den Zugriff darauf.
Als nächstes wird ein Namensraum für jeden der Kundendienst-Cluster erzeugt, zum Beispiel E-payments/us-east-payments. Nicht möglich ist es, eine Bezeichnung wie E-payments/payments zu benutzen. Das würde zur voll vermaschten Replikation führen, da dieser Namensraum dann jedem Cluster gehören würde. Daher müssen sich die Namensräume klar auf ein spezifisches Cluster beziehen, damit alles funktioniert.
Listing 4: Aggregierende Georeplikation
/pulsar/bin/pulsar-admin tenants create E-payments \ #A --allowed-clusters us-west,us-east,us-central,internal /pulsar/bin/pulsar-admin namespaces create E-payments/us-east-payments #B /pulsar/bin/pulsar-admin namespaces create E-payments/us-west-payments /pulsar/bin/pulsar-admin namespaces create E-payments/us-central-payments /pulsar/bin/pulsar-admin namespaces set-clusters \ #C E-payments/us-east-payments --clusters us-east,internal /pulsar/bin/pulsar-admin namespaces set-clusters \ #D E-payments/us-west-payments --clusters us-west,internal /pulsar/bin/pulsar-admin namespaces set-clusters \ #E E-payments/us-central-payments --clusters us-central,internal
Angenommen, man möchte dieses Verfahren implementieren und auf allen Kunden-Clustern eine identische Kopie einer Applikation laufen lassen. Dann muss der Name auf der obersten Hierarchieebene so konfigurierbar sein, dass die Applikation, die beispielsweise auf US-East läuft, weiß, dass sie entsprechende Nachrichten in den US-East-Namensraum hinein publizieren darf. Sonst funktioniert die Replikation nicht.
Über den Autor:
David Kjerrumgaard ist Direktor Solution Architecture bei Streamlia und arbeitet an den Projekten Apache Pulsar und Apache NiFi als Contributor mit.
Die Autoren sind für den Inhalt und die Richtigkeit ihrer Beiträge selbst verantwortlich. Die dargelegten Meinungen geben die Ansichten der Autoren wieder.
Erfahren Sie mehr über Backup-Lösungen und Tools
-
![]()
AWS Summit Hamburg 2026: Sovereign Cloud nimmt Fahrt auf
Von: Florian Fröhlich
-
![]()
Netzwerkverschlüsselung mit MACsec zwischen Switch/Switch
Von: Benjamin Pfister
-
![]()
Netzwerkverschlüsselung mit MACsec zwischen Switch und Endgerät
Von: Benjamin Pfister
-
![]()
Netzwerke mit VXLAN und EVPN: Overlay- und EVPN-Konfiguration
Von: Benjamin Pfister


