Machine Learning in Datenanalysen kann Storage-Probleme lösen
Einige Hersteller wie Dell EMC und HPE beginnen, ML in ihren Storage-Systemen einzusetzen, um Probleme der Big-Data-Analyse besser zu lösen als bisher möglich.
Zuletzt aktualisiert: 03 Sept. 2019
Große Unternehmen in vielen Branchen entdecken neuen geschäftlichen Wert in bereits existierenden Daten. Sie verwenden heute bereits regelmäßig maschinelles Lernen (ML), um bislang versteckte Erkenntnisse zu gewinnen. Trotz all dieser Vorteile stellt ML-basierte Datenanalyse insbesondere die Storage-Infrastruktur vor einige Herausforderungen.
Weil in den Daten verborgene Werte stecken, könnte es sein, dass Organisationen davor zurückschrecken, veraltete Daten zu löschen. Dadurch wird Storage schneller verbraucht, was die Kapazitätsplanung erschwert. Außerdem belasten die aktuellen analytischen Prozesse die darunterliegende Storage-Infrastruktur zusätzlich.
Ironischerweise haben nun einige Hersteller damit begonnen, KI als Werkzeug zur Lösung von Problemen zu verwenden, die durch Big Data Analytics erzeugt werden. So, wie es derzeit aussieht, basieren ihre Mechanismen für analytisches ML nicht nur auf einer, sondern mehreren sehr unterschiedlichen Technologien.
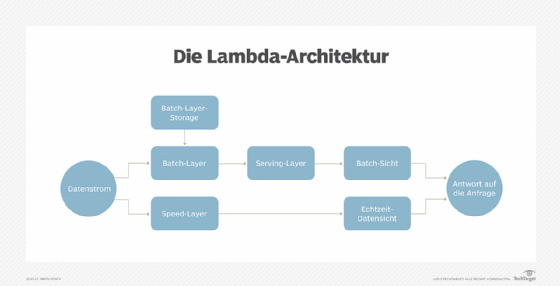
Die Lambda-Architektur
Beim Einsatz von KI beispielsweise für die Erstellung von Workflow-Profilen und Kapazitätsplanung ist es wichtig, Zugriff auf aktuelle Daten über den Storage-Einsatz und die Gesundheit der Storage-Systeme zu haben. Zudem ist es nicht immer optimal, sich ausschließlich auf Echtzeitdaten zu verlassen.
Das Problem bei der Nutzung von Echtzeit-Streaming-Daten besteht darin, dass die Daten in Rohform vorliegen und in keiner Weise kuratiert wurden. Doch der Datenstrom kann Löcher oder andere Fehler aufweisen. Die Tatsache, dass Daten in Echtzeit eingesetzt werden, begrenzt stark die Verarbeitungsleistung.
Der Einsatz relativ aktueller Daten, die allerdings keine Echtzeitdaten sind, bringt beim Einsatz von ML-getriebener Datenanalyse oft mehr Erkenntnisse. Aber diese Daten sind eben nicht ganz so frisch wie die, die gerade augenblicklich in das System einlaufen.
Die Lambda-Architektur löst dieses Problem, indem Daten gleichzeitig auf zwei unterschiedlichen Schichten ins System gestreamt werden: auf der Batch-Ebene und dem Speed-Layer. Der Batch-Layer speichert die Daten einfach nur. Weil mit den Daten nicht in Echtzeit gearbeitet wird, können Batch-Regeln zur Verbesserung der Datenqualität verwendet werden. In einigen Modellen kann die Batch-Ebene auch einer dritten Ebene Daten bereitstellen, dem Serving-Layer. Er erzeugt Batch-Sichten, die Anfragen beantworten.
Daneben werden einlaufende Daten in den Speed-Layer gestreamt, der Echtzeit-Datensichten erzeugt.
Wenn eine Anfrage an eine Lambda-Architektur gestellt wird, erhalten Organisationen die Resultate, indem sie die Analysen aus der Batch- und der Echtzeit- oder Speed-Schicht zusammenführen. Dadurch kann die Lambda-Architektur ein umfassenderes oder sogar vollständiges Bild der Daten erzeugen, was anders nicht möglich wäre.
Abbildung 1: Die Lambda-Architektur im Überblick
Damit die Lambda-Architektur funktioniert, braucht sie eine sehr geringe Latenz und muss ausreichend skalierbar sein, um den eingehenden Datenstrom handhaben zu können. Daher ist die Lambda-Architektur auf Skalierbarkeit über mehrere Knoten hinweg konzipiert. Dazu können beispielsweise auch hyperkonvergente Knoten gehören. Die Scale-Out-Architektur ermöglicht zudem Toleranz gegenüber Hardwarefehlern.
Kundenspezifische FPGAs (Field Programmable Logic Array, feldprogrammierbare Logikbausteine) gibt es seit den 80er Jahren. Ein FPGA-Design ermöglicht die Erstellung unterschiedlicher komplexer kundenspezifischer Logikschaltungen durch die Konfiguration seiner Elemente. FPGA sind in der Regel kostengünstiger als fest verdrahtete ASIC (Application-specific Integrated Circuit), die ebenfalls kundenspezifisch sind.
FPGAs werden deshalb traditionell eingesetzt, um die Kosten und die Komplexität beim Design von elektronischen Geräten zu senken. Diese basieren nahezu immer auf integrierten Schaltkreisen (ICs). Elektroingenieure, die ein neues Design entwickeln, suchen nach einem passenden IC auf dem Markt oder entwickeln einen kundenspezifischen IC. Durch die vielen Konfigurationsmöglichkeiten eines FPGA wird das unnötig, man braucht also kaum noch kundenspezifische Schaltkreise.
Hardwarehersteller beginnen inzwischen damit, FPGAs in ML und Datenanalyse als Alternative zu CPUs und GPUs zu verwenden. Wie wichtig das Thema inzwischen ist, zeigte sich unter anderem daran, dass Intel 2015 den FPGA-Anbieter Altera für 16,7 Milliarden Dollar aufkaufte. Weitere Anbieter sind beispielsweise Xilinx, Lattice oder Microchip, früher als Atmel bekannt.
Doch auch andere Eigenschaften von FPGAs machen sie zur wichtigen Option beim Maschinenlernen. Es handelt sich vor allem um zwei:
Sie haben eine sehr geringe Latenz. Das liegt vor allem daran, dass ein fertig programmierter FPGA als kundenspezifisches und für einen bestimmten Zweck konstruiertes Bauelement agiert – nicht als allgemein einsetzbares wie eine CPU. Zudem muss auf einem FPGA kein Allzweck-Betriebssystem wie Windows oder Linux laufen. Wegen der geringen Latenz, manchmal beträgt sie nur eine Mikrosekunde, eignen sich FPGAs gut als Hardware für ML-basierte KI-Plattformen.
Sie beherrschen Gleitkomma Berechnungen. Allerdings sind sie auf diesem Gebiet noch nicht so gut wie die schnelleren und genaueren modernen CPU und GPU. Daher sind die FPGAs der aktuellen Generation (noch) keine gute Option für das KI-Training. Allerdings sind sie hervorragend bei der Bearbeitung von Inferenzaufgaben. Daher können Storage-Anbieter FPGAs als Plattform zur Integration von ML-Fähigkeiten in die Storage-Hardware nutzen, so lange die anfänglichen Trainingsdaten auf einer anderen Plattform erzeugt und dann auf das System kopiert werden.
Training versus Inferenz
ML basiert im Prinzip auf den Konzepten Training und Inferenz. Training bedeutet genau dasselbe wie im konventionellen Sprachgebrauch: Es ist der Prozess, bei dem die ML-Plattform lernt, wie sie eine spezielle Aufgabe ausführen soll.
Ein klassisches Beispiel eines Trainingsprozesses ist ein 2012 durchgeführtes Experiment, in dessen Verlauf ein Computeralgorithmus darauf trainiert wurde, eine Katze zu erkennen. Dieses Experiment betonte die rechen- und datenintensive Natur des Lernprozesses. Um dem System beizubringen, Katzen sicher zu erkennen, brauchte man 16.000 Computer, denen insgesamt 10 Millionen Katzenbilder vorgeführt wurden. Als Ergebnis entstand ein Algorithmus, der erkennen konnte, ob ein Bild eine Katze oder etwas anderes (keine Katze) zeigt.
Der zweite wichtige Teil von ML ist Inferenz. Das bedeutet die Aufgabe, die ein ML-Algorithmus löst, nachdem das Training abgeschlossen wurde. Im Fall des eben erwähnten Katzen-Algorithmus beispielsweise findet Inferenz statt, wenn der Algorithmus ein bislang unbekanntes Bild ansieht und korrekt auf Basis seines bisherigen Trainings feststellt, ob darauf eine Katze abgebildet ist oder nicht.
Hinsichtlich der Verarbeitung unterscheidet sich Inferenz stark vom Training. Der Trainingsprozess ist sehr rechenintensiv und erfordert normalerweise die Analyse von Unmengen Daten. Inferenz basiert ausschließlich auf dem während des Trainingsprozesses angesammeltem Wissen. Sie braucht daher sehr viel weniger Zeit und Rechenaufwand als das Training.
Container-Storage
Obwohl Container vor allem als Plattform für geschäftliche Anwendungen bekannt sind, eignen sie sich auch für ML-Aufgaben.
Der Trainingsprozess eines ML-Algorithmus ist rechenintensiv. Ist er aber einmal angelernt, können Unternehmen diesen Algorithmus oft nutzen, ohne besonders viele CPU-Ressourcen dafür einzusetzen. Weil ML-Prozesse meist recht leichtgewichtig sind, laufen sie immer öfter in Containern ab. Ein Beispiel für eine meist containeirisierte ML-Technologie ist TensorFlow.
TensorFlow ist eine Open-Source-Python-Bibliothek von Google. Ihr Ziel ist es, ML zu vereinfachen. Dafür hat Google seinen eigenen kundenspezifischen Schaltkreis, die Tensor Processing Unit (TPU) entwickelt, auf der der Algorithmus läuft. Allerdings hat Google TensorFlow so konzipiert, dass es auf fast jeder Plattform läuft, auch auf Containern.
Einer der überzeugendsten Gründe, TensorFlow zu containerisieren, besteht darin, dass sich so Applikationen skalieren lassen. Organisationen können Graphen über TensorFlow-Cluster verteilen und die Server containerisieren, aus denen diese Cluster bestehen. Graphen sind spezielle ML-Algorithmen, mit denen sich beispielsweise komplexe Optimierungsprobleme lösen lassen.
Was tun die Hersteller?
Eines der ersten Speicherprodukte mit ML-basierter Datenanalyse ist die Dell EMC PowerMax-Familie. Dell EMC bezeichnet PowerMax als das weltweit schnellste Storage-Array, da es bis zu 10 Millionen IOPS leistet und bis zu 150 Gbit/s Bandbreite bietet (laut Hersteller).
Der Trainingsprozess eines ML-Algorithmus ist rechenintensiv. Ist er aber einmal angelernt, können Unternehmen diesen Algorithmus oft nutzen, ohne besonders viele CPU-Ressourcen dafür einzusetzen.
PowerMax-Arrays verdanken ihre Leistung mindestens teilweise ML. Die integrierte ML-Engine verwendet automatisch vorausschauende Analytik, um die Leistung zu erhöhen. Dafür schiebt sie Daten basierend auf der angenommenen Nachfrage nach diesen Daten auf den bestgeeigneten Medientyp – Flash oder Storage Class Memory.
Doch Dell EMC ist nicht der einzige Hersteller, der ML verwendet, um Storage intelligenter zu machen. Auch Hewlett Packard Enterprise (HPE) nutzt ML bei der Datenanalyse, um mehr Intelligenz in hybride Cloud-Storage zu integrieren.
Hybride Cloud-Umgebungen enthalten in der Regel Storage, die sich im eigenen Rechenzentrum der betreffenden Organisation und innerhalb unterschiedlicher Public Clouds befindet. Historisch war es Sache der IT-Abteilung zu prüfen, wie diese Daten verwendet und wo sie gespeichert werden sowie Ineffizienzen zu erkennen. HPEs Intelligent-Storage-Technologie analysiert Workloads auf die sie betreffenden Anforderungen hin und verschiebt die betreffenden Daten daraufhin auf den optimalen Standort. Dabei legt das System Metriken wie Storage-Kosten, Leistung, Nähe zum Ort der Datennutzung und verfügbare Kapazität zugrunde. Intelligent Storage passt sich auch an sich verändernde Bedingungen in Echtzeit an und verschiebt Daten bei Bedarf.
Was ist das Ziel?
Organisationen, die die Fähigkeiten von ML für ihre Storage nutzen wollen, sollten überlegen, was sie erreichen möchten. Wurden diese Bedürfnisse erst identifiziert, können sie nach Produkten suchen, die diese Anforderungen direkt adressieren. Besteht beispielsweise das wichtigste Ziel darin, die Leistung zu optimieren, empfiehlt es sich, nach Produkten zu suchen, die ML aus Basis für ihre Analytik verwenden, um Daten automatisch so anordnen, dass die Latenz minimiert wird und nicht wirklich benötigte I/O-Vorgänge vermieden werden.
Abhängig vom Bedarf muss eine Organisation nicht unbedingt neue Storage-Produkte kaufen, um von ML zu profitieren. Eine Softwarelösung ohne neue Storage-Hardware beispielsweise kann für Anwendungen wie die automatische Kapazitätsplanung durchaus ausreichen.