
sarayut_sy - stock.adobe.com
Wie man Dark Data mit Machine Learning und KI auswertet
Maschinelles Lernen und KI können unstrukturierte und ungenutzte Daten in wertvolle Informationen verwandeln. Wie sich Dark Data auswerten lässt.

Um in modernen digitalen Umgebungen wettbewerbsfähig zu sein, sind Machine Learning, Deep Learning und künstliche Intelligenz (KI) mittlerweile unumgänglich. Durch den Einsatz von maschinellem Lernen und KI können Unternehmen ungenutzte und unstrukturierte Daten – Dark Data – nutzen, um wettbewerbsfähige Geschäftserkenntnisse zu gewinnen.
Dark Data besteht aus Millionen von unstrukturierten Datenpunkten, die in Unternehmen anfallen und in Multiformat-Data-Lakes gespeichert werden. Bis vor kurzem gab es nur wenige Tools, um diese riesigen Datenmengen zu verarbeiten, aber das ändert sich mittlerweile.
Dark Data definieren
Dark Data wird in jeder Branche anders definiert. Es handelt sich dabei in erster Linie um unstrukturierte, nicht klassifizierte und ungenutzte Informationen. Klassisches Dark Data wird zwar erfasst und gespeichert, aber nie analysiert. Es umfasst alles von Protokolldateien, Unternehmensdokumenten und E-Mails bis hin zu sozialen Medien, Webseiten, Tabellen, Zahlen und Bildern. Unternehmen setzen zunehmend ausgefeilte Technologien zur Verarbeitung dieser Daten ein, um Geschäftserkenntnisse zu gewinnen und die Systemautomatisierung mit Deep-Learning-Algorithmen voranzutreiben.
Unternehmen verwenden drei Komponenten, aus denen sich maschinelles Lernen zusammensetzt: Modelle, Trainingsdaten und Hardware. Modelle sind durch die Verfügbarkeit von Frameworks wie TensorFlow, PyTorch und Keras zu einem Massenprodukt geworden. Entwickler können die neuesten Modelle für die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) einfach installieren, sie einsetzen und erste Ergebnisse erzielen.
Selbst mit standardisierten Modellen und Hardware müssen Techniker aber immer noch die Trainingsdaten liefern – und Ingenieure müssen sie strukturieren. Die Informationen sind dabei häufig ungenau, doch das Auffinden der Verbindungen zwischen nicht zusammenhängenden Informationen ist der Schlüssel zum Ausschöpfen des Potenzials von Dark Data.
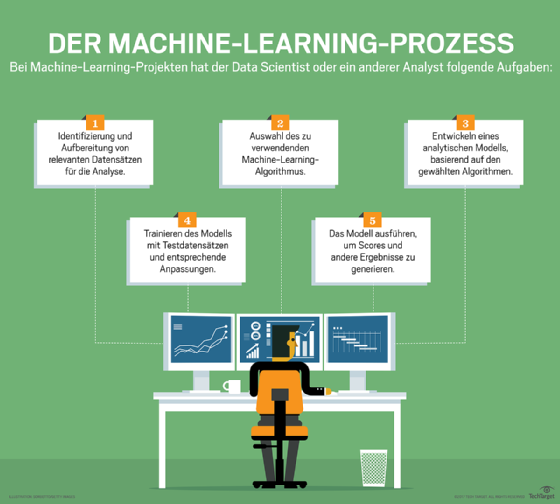
Die manuellen Prozesse zur Klassifizierung und Verwaltung von Data Data sind ineffizient und verschlingen wertvolle Zeit und Ressourcen. Tools zur Analyse dieser Daten, wie zum Beispiel DeepDive, Snorkel und DarkVision, rationalisieren die Kategorisierung und helfen Computern, von Menschen erstellte Dokumente zu verstehen.
Ansätze zur Auswertung von Dark Data
Maschinelles Lernen beruht auf der Anwendung von künstlicher Intelligenz (KI), um das Lernen zu beschleunigen und Systeme in die Lage zu versetzen, Entscheidungen zu treffen und bestimmte Aktionen automatisch durchzuführen. Dieser Erfassungsprozess nutzt die Erkennung von Datenmustern und spezifische Lernmethoden wie überwachtes, unüberwachtes und bestärkendes Lernen.
Indem sie sich auf Entscheidungsregeln und menschliches Eingreifen zur Lösung von Ausnahmen verlassen, verinnerlichen Machine-Learning-Systeme Reaktionen und nutzen Wiederholungen, um auf neue Ereignisse richtig zu reagieren. Durch die Kombination von Musteranalyse und Deep Learning erwerben Maschinen schrittweise höhere Fähigkeiten, um bei immer komplexeren Entscheidungen die richtigen Antworten zu geben.
Um Initiativen zum maschinellen Lernen erfolgreich durchzuführen, müssen Unternehmen Prioritäten setzen und in die Analyse von Dark Data investieren. Anschließend ist es Sache der einzelnen Unternehmen, Handlungsstrategien zu entwickeln und ihre unstrukturierten Daten für die Verarbeitung vorzubereiten.
Zunächst stellen die Techniker sicher, dass die gesuchten Daten vertrauenswürdig sind und nützliche Erkenntnisse liefern können. So sind beispielsweise nicht konforme oder ungenaue Daten für ein Unternehmen, das strengen gesetzlichen Vorschriften unterliegt, nicht von Nutzen, selbst wenn sie vorhanden sind. Neben automatisierten Prozessen zur Prüfung von Dark Data sollten Techniker auch Metadatenkennzeichnungen vornehmen, um künftige Machine-Learning-Projekte zu unterstützen und eine geordnete Struktur für die Zukunft zu schaffen. Ziel ist es, die Umwandlung von unstrukturierten Daten in verständliche, lesbare Assets zu automatisieren.
Cloud-Dienste sammeln und speichern umfassende Informationen, was den Zugang zu Dark Data vereinfacht. Die Services sind entscheidend für die Erfassung von Echtzeitdaten und für die Wartung von Edge-Rechenzentren, dezentralen Anlagen und IoT-Endpunkten.

Techniker können auch NoSQL-Datenspeicher verwenden, um ein Schema auf die Informationen anzuwenden. NoSQL gewährleistet eine größere analytische Flexibilität, sobald Unternehmen gelernt haben, wie sie Dark Data klassifizieren können. Dann brauchen Geschäfts- und IT-Führungskräfte eine klare, einheitliche Vision, wie die Ergebnisse zu nutzen sind.
NLP ist ein weiteres wertvolles Tool, das dabei unterstützt, Dark Data sinnvoll zu nutzen und die Vorbereitung für maschinelles Lernen zu beschleunigen. NLP visualisiert syntaktische Verbindungen zwischen Sprachblöcken und ermöglicht Maschinen die schnelle Verarbeitung und Analyse von Terabytes an Informationen. In Kombination mit KI zur Beschleunigung der Datenaufbereitung hilft NLP, die riesige Menge an Dokumenten und Aufzeichnungen zu verstehen, die generiert werden.
Inhärente Gefahren durch Dark Data
Da Modelle für maschinelles Lernen auf riesige Data Lakes zugreifen, um Informationen aufzunehmen und zu verarbeiten, werden sie zu potenziellen Vektoren für Datenlecks oder zu Zielen für Angriffe. Sicherheitsmängel bei Datenzugriffsmodellen ermöglichen es Angreifern, Einblicke in betriebliche Abläufe zu gewinnen oder auf Dokumentenstrukturen innerhalb von Unternehmen zu schließen.
Wenn ein Unternehmen nicht über ein angemessenes Dateninventar oder Wissen über den Speicherinhalt verfügt, riskiert es Audits, Geldstrafen oder Markenschäden, wenn es die Daten verwendet.
Informationsintegrität ist von entscheidender Bedeutung. Unternehmen, die ihre Daten nicht auf eine etablierte, glaubwürdige Quelle zurückführen können, sollten diese Inhalte nicht zur Gewinnung von Erkenntnissen verwenden. Außerdem müssen Geschäfts- und IT-Verantwortliche den Zugriff auf bestimmte Daten einschränken, Nutzungsrichtlinien verschärfen und Verschlüsselungs- und Sicherheitsmaßnahmen einführen.
Kognitive Technologien und die Weiterentwicklung von Analysetechniken erschließen Dark Data für eine großangelegte, kostengünstige und automatisierte Analyse. Diese Techniken minimieren die Anzahl der Ressourcen, die für die Arbeit mit Dark Data benötigt werden. Und mit den richtigen Strategien können Geschäfts- und IT-Verantwortliche die Datenaufbereitung beschleunigen und den Wert beziehungsweise die Verwendung der Informationen in der Zukunft definieren.







