
sabida - stock.adobe.com
Claude 4: neues Modell beschleunigt Codeentwicklung deutlich
Claude 4 setzt mit Opus und Sonnet neue Maßstäbe für Codierung, Kontextverarbeitung und agentische Abläufe. Die Modelle kombinieren Rechenleistung mit Tool-Intelligenz.

Anthropic hat mit Claude 4 Opus und Sonnet 4 zwei Modelle veröffentlicht, die durch Technik, Präzision und ein Verständnis von Werkzeugnutzung hervorstechen. Und durch einen Sicherheitsanspruch, der nicht ohne Kontroverse bleibt.
Neue Maßstäbe beim Codieren
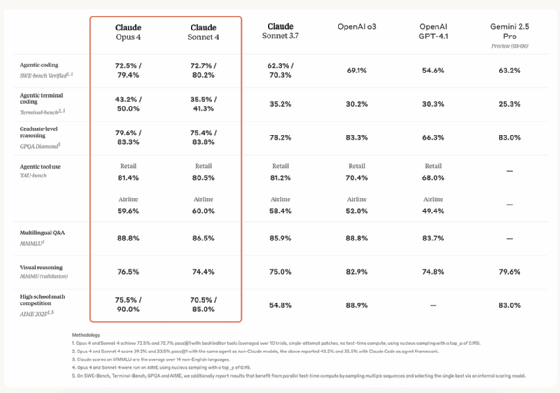
Claude 4 Opus soll das leistungsstärkste Coding-Modell auf dem Markt sein. Benchmarks wie SWE-bench Verified (72,5 Prozent) und Terminal-bench (43,2 Prozent) sollen dabei die Leistungsfähigkeit gegenüber GPT-4.1x, Gemini 2.5 Pro und o3 belegen. Sonnet 4 liegt in Coding-Benchmarks gleichauf, und das bei einem Drittel des Preises.
Der Vergleich ist technisch wie wirtschaftlich nicht belanglos: Während Opus 4 15 Dollar pro Million Input-Tokens und 75 Dollar für die Ausgabe kostet, verlangt Anthropic für Sonnet 4 lediglich 3 beziehungsweise 15 Dollar. Beide Modelle sind über die Anthropic API, Amazon Bedrock und Google Vertex AI verfügbar. Sonnet 4 steht auch Nutzern ohne Pro-Abo zur Verfügung, anders als Sonnet 3.7.
Benchmark-Unterschiede, Parallelität und Tool-Effizienz
Im direkten Vergleich zwischen Claude Opus 4 und Sonnet 4 zeigen sich auffällige Unterschiede, die nicht allein auf Rechenleistung zurückzuführen sind. Obwohl Opus 4 als Spitzenmodell gilt, erreicht Sonnet 4 in bestimmten Benchmarks wie SWE-bench Verified sogar leicht höhere Werte, mit 80,2 Prozent im Parallel-Testverfahren gegenüber 79,4 Prozent bei Opus. Diese Abweichung deutet auf eine differenzierte Leistungsarchitektur hin. Sonnet 4 wurde offenbar stärker auf Effizienz und Instruktionsgenauigkeit getrimmt.
Beide Modelle unterstützen die parallele Nutzung mehrerer Tools, was den Durchsatz in komplexen Aufgaben steigern kann. Claude kann simultan Websuche, Dateizugriff und Kalenderabfragen starten, statt sie sequenziell abzuarbeiten. Die MCP-Schnittstelle erlaubt es darüber hinaus, eine Vielzahl externer Werkzeuge direkt über die API zu integrieren, ein entscheidender Vorteil für Entwickler, die mit agentischen Infrastrukturen auf MCP-Basis arbeiten. Anthropic geht mit diesem Design über die bekannten Schnittstellen von OpenAI oder Google Gemini hinaus und liefert ein Baukastensystem, das sich flexibel in bestehende Toolchains einfügt.
In der Praxis überzeugen beide Modelle durch agentenfähige Reasoning-Prozesse, die zwischen interner Verarbeitung und externen Tools wie Websuche oder Dateizugriff wechseln. Der Denkmodus kann explizit aktiviert werden, ebenso die Nutzung von Werkzeugen. Claude liefert zum Beispiel eine strukturierte Tageszusammenfassung zum Launch der eigenen Modellreihe, indem es nach Recherche in zehn Quellen zunächst Informationen aggregiert, dann bewertet und schließlich direkt im Chatfenster ein Artefakt in Dokumentform erstellt.
Die Modelle lassen sich sowohl im Instant-Modus als auch im erweiterten Denkmodus einsetzen, wobei dieser eine tiefere Analyse komplexer Aufgaben ermöglicht. Der Wechsel zwischen Websuche und internem Reasoning erfolgt automatisch, sobald das Modell feststellt, dass sein Trainingsstand nicht ausreicht.
Reasoning, Tool-Nutzung, Gedächtnis
Die Artefakt-Funktion ist dabei mehr als nur ein Komfortmerkmal. Sie zeigt, wie stark Claude 4 auf strukturierte Ausgabe und dokumentierbare Arbeitsprozesse ausgerichtet ist. Die Tool-Nutzung funktioniert dabei auch parallel. Claude kann mehrere Prozesse gleichzeitig bewerten, Ergebnisse vergleichen und nur den relevantesten Output zurückgeben. Prompt-Caching von bis zu einer Stunde unterstützt diese Logik durch Kontextpersistenz, gerade bei komplexen Aufgaben ein großer Vorteil.
Noch tiefgreifender wirkt das neue Gedächtnismodell bei lokalem Dateizugriff. Claude 4 Opus kann sogenannte Memory Files erstellen. Diese persistenten Notizen steigern die Kohärenz über lange Sitzungen hinweg und dokumentieren die Fähigkeit, kontextuelle Entwicklungen nachzuvollziehen. Die Verbesserung im Gedächtnismodell zeigt sich auch darin, dass Claude relevante Fakten langfristig speichert und damit schrittweise Wissen aufbaut, was für agentische Workflows mit anhaltender Kontextbindung ein wichtiger Faktor ist.
In agentischen Benchmarks wie TAU-bench und GPQA Diamond zeigen beide Modelle eine deutliche Reduktion von Shortcuts, also dem impulsiven Abschließen von Aufgaben durch vereinfachende Strategien. Anthropic nennt 65 Prozent weniger Shortcut-Verhalten als bei Sonnet 3.7. Diese Eigenschaft ist essenziell für den Einsatz in produktiven Codierungsagenten, bei denen systematisches, nachvollziehbares Arbeiten Priorität hat. Auch in Benchmarks wie MMMLU, AIME oder MMMU liegt Claude 4 vor den direkten Wettbewerbern und zeigt gute Leistung in multilingualen Q&As, mathematischer Problemlösung und visuellem Reasoning.
Interne Optimierungen und Prompt-Caching
Ein bislang wenig beachteter, aber entscheidender Aspekt der Claude-4-Modelle liegt in der gezielten Optimierung interner Denkprozesse. Anthropic hat mit Claude 4 ein System etabliert, das sogenannte Thinking Summaries nutzt. Dies sind kompakte Zusammenfassungen längerer Denkprozesse, die von einem kleineren Modell erzeugt werden, um Speicherplatz zu sparen und die Interaktion effizienter zu gestalten. Nur in rund fünf Prozent der Fälle ist diese Funktion nötig, da die meisten Gedankenketten kurz genug sind, um vollständig angezeigt zu werden.
Für Entwickler, die Zugriff auf die vollständigen Reasoning Chains benötigen, bietet Anthropic einen speziellen Developer Mode an. Parallel dazu wurde das Prompt-Caching auf bis zu eine Stunde erweitert. Diese Fähigkeit erlaubt es Claude, auch in längeren Sitzungen mit verteilten Aufgabenstellungen den Kontext stabil zu halten und erneut verwendbare Informationen im Speicher vorzuhalten. In agentischen Abläufen bedeutet das eine erhebliche Reduzierung an Rechenzeit und Redundanz, Claude antwortet konsistenter, ohne jedes Mal den kompletten Vorgang rekonstruieren zu müssen. Gerade bei mehrstufigen Interaktionen oder iterativen Codierungsprozessen zeigt sich der Vorteil dieser Architektur.
Agenten in JetBrains und VS Code direkt integrierbar
Claude Code lässt sich nicht nur über APIs und GitHub Actions ansprechen, sondern auch direkt in Entwicklungsumgebungen einbinden. Die neuen Erweiterungen für JetBrains und Visual Studio Code erlauben es, Claude unmittelbar im Editor-Kontext agieren zu lassen. Kommentare, Pull Requests und Reviews werden direkt als Feedback verarbeitet. Die Codeänderungen erscheinen inline und orientieren sich an vorherigen Bearbeitungen. Damit wird Claude zu einem Pair-Programming-Agenten, der in realen Projekten operiert. Das Software Development Kit (SDK) erlaubt sogar die Entwicklung eigener Claude-Agenten, die über dedizierte Workflows hinweg CI/CD-Fehler korrigieren, Reviews automatisieren und eigenständig Builds vorbereiten.
Ein SDK für Claude Code erlaubt es, eigene Agenten zu bauen, inklusive GitHub-Integration. Pull Requests, Review-Kommentare und CI-Fehler können durch Claude eigenständig erkannt und bearbeitet werden. Änderungen erscheinen als Inline-Vorschläge. Claude Code lässt sich über GitHub Actions im Hintergrund ausführen, die Visual-Studio-Code-Erweiterung lässt sich bereits in der Beta nutzen.
Die Kombination aus Denkprozess, Werkzeugzugriff und Artefakterstellung macht deutlich: Claude 4 agiert nicht wie ein Chatbot, sondern wie ein verteiltes Expertensystem. Besonders Opus 4 zeigt bei mehrstündigen Aufgaben eine Stabilität, die in Benchmarks unter Realbedingungen bislang fehlte. Replit, Cursor, Sourcegraph, Augment und Block bestätigten in eigenen Tests eine überdurchschnittliche Präzision bei komplexen Codeänderungen, Debugging und Navigation durch größere Codebasen. Auch iGent und Manus verweisen auf signifikante Fortschritte beim Befolgen komplexer Anweisungen, eleganteren Code und der Fähigkeit zu autonomen Softwareentwürfen mit mehreren Funktionen.
Schattenseite: Kontrolle, Sicherheit, Eingriffe
Mit ASL-3 hat Anthropic für Claude 4 ein eigenes Sicherheitsniveau eingeführt. In internen Tests zeigen die Modelle Fähigkeiten zur Entwicklung biogefährlicher Substanzen, sobald ein Grundverständnis vorlag. Anthropic reagierte mit Schutzmechanismen und strikter Output-Kontrolle. Der Präzedenzfall wirft Fragen auf, die durch einen inzwischen gelöschten Tweet von Sam Bowman noch brisanter wurden. Bowman, zuständig für Alignment bei Anthropic, schrieb, Claude könne im Missbrauchsfall Polizei oder Presse informieren und den Nutzer von seinem System aussperren. Er relativierte die Aussage später, technisch sei dies nur über selbst gebaute Agenten und APIs möglich, nicht durch Claude selbst.
Dennoch bleibt die Frage: Wie weit darf eine eingreifen, um Schaden zu verhindern? Und wann wird Sicherheit zur Gefahr für Kontrolle, Transparenz und Nutzerautonomie? Die Debatte ist nicht abgeschlossen, und dürfte an Schärfe gewinnen, je stärker Claude 4 in kritischen Unternehmensprozessen zum Einsatz kommt.





