
Sergey Nivens - stock.adobe.com
Kubernetes Pods für Microservices skalieren: eine Anleitung
Kubernetes bietet verschiedene Mechanismen für die automatisierte Pod-Skalierung, um eine dynamische Infrastruktur für Microservices zu schaffen. Wir zeigen, wie das funktioniert.

Das Planen der Clusterkapazitäten in Kubernetes hilft dabei, eine über- oder unterprovisionierte Infrastruktur zu vermeiden. IT-Administratoren benötigen eine zuverlässige und kostengünstige Möglichkeit, ihre Cluster und Pods in Situationen mit erhöhter Auslastung anzupassen und die Infrastruktur automatisch zu skalieren, damit sie die Ressourcenanforderungen erfüllen kann.
Kubernetes unterstützt drei verschiedene Arten der automatischen Skalierung:
- Vertikaler Pod Autoscaler (VPA). Erhöht oder verringert die Ressourcenlimits für den Pod.
- Horizontaler Pod Autoscaler (HPA). Erhöht oder verringert die Anzahl der Pod-Instanzen.
- Cluster Autoscaler (CA). Erhöht oder verringert die Knoten im Knotenpool basierend auf der Pod-Planung.
Diese Anleitung beschränkt sich auf die Optionen Horizontal und Vertikal, da wir auf Pod-Ebene und nicht auf Knotenebene arbeiten werden.
Richten Sie einen Microservice in einem Kubernetes-Cluster ein
Erstellen Sie zunächst eine REST-API, die Sie als Microservice in Containern auf Kubernetes hosten werden. Um den Lerneffekt zu verstärken, generieren wir zunächst gemeinsam die REST-API, die wie im nachfolgenden Code in Go geschrieben ist und einen Microservice auf Kubernetes startet. Speichern Sie den untenstehenden Inhalt in einer Datei mit dem Namen deploy.yml.
apiVersion: apps/v1
kind: Deployment
metadata:
name: microsvc
spec:
selector:
matchLabels:
run: microsvc
replicas: 1
template:
metadata:
labels:
run: microsvc
spec:
containers:
- name: microsvc
image: "prateeksingh1590/microsvc:1.1"
ports:
- containerPort: 8080
resources:
requests:
memory: "64Mi"
cpu: "125m"
limits:
memory: "128Mi"
cpu: "250m"
---
apiVersion: v1
kind: Service
metadata:
name: microsvc
labels:
run: microsvc
spec:
ports:
- port: 8080
selector:
run: microsvc
Führen Sie nun den folgenden Befehl aus, um den Microservice im Kubernetes Cluster bereitzustellen:
kubectl apply -f. \ deploy.yml
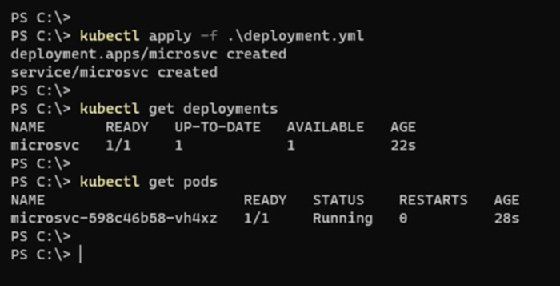
Nach Abschluss des Vorgangs startet der neue Pod im Cluster (siehe Abbildung 1).
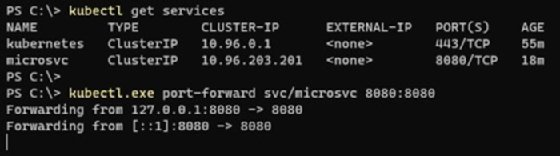
Um im Betrieb auf den Microservice zuzugreifen, leiten Sie den Service-Port an den lokalen Host weiter, wie im folgenden Beispiel und in Abbildung 2 gezeigt.
kubectl get services
kubectl port-forward svc/microsvc 8080:8080
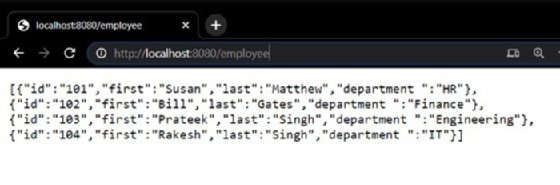
Wenn ich versuche, über meinen Browser auf die REST API in Go zuzugreifen, gibt die Konsole die Ergebnisse wie in Abbildung 3 aus.
Da nun die Anwendung als Microservice in einem Kubernetes-Cluster läuft, richten wir eine automatische horizontale Skalierung ein, um auf einen plötzlichen Anstieg oder Rückgang des Ressourcenbedarfs zu reagieren.
Horizontaler Pod Autoscaler
HPA ändert die Anzahl der Pods basierend auf einer benutzerdefinierten Metrik oder der Ressourcenmetrik eines Pods. Kubernetes-Administratoren können auch Schwellenwerte festlegen, welche bestimmen, wann Kubernetes die Zahl der Pod-Replikate in einem Bereitstellungs-Controller automatisch anpasst.
Wenn beispielsweise die CPU-Auslastung einen bestimmten Prozentsatz über einen festgelegten Zeitpunkt hinweg erreicht, erhöht HPA die Anzahl der Pods, um die neue Last zu bewältigen und ein reibungsloses Funktionieren der Anwendung aufrechtzuerhalten.
Verwenden Sie den folgenden Befehl, um die Skalierung abhängig von der CPU-Auslastung zu steuern.
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=4
In diesem Beispiel werden die Pods auf maximal vier Replikate erhöht, wenn der Microservice läuft und über einen längeren Zeitraum eine CPU-Auslastung von mehr als 50 Prozent besteht.
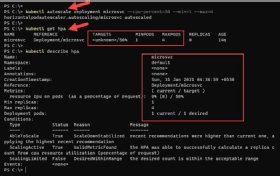
Um den HPA-Status zu überprüfen, führen Sie den Befehl kubectl get hpa aus, der die aktuelle und angestrebte CPU-Auslastung angibt. Anfangs kann es passieren, dass der Wert als unbekannt angezeigt wird, aber schon nach kurzer Zeit gibt die Konsole den Grad der Auslastung in Prozent an.
Verwenden Sie für einen detaillierten HPA-Status den Befehl description, um mehr Informationen, wie Metriken, Ereignisse und Bedingungen zu finden.
kubectl describe hpa
Testen der automatischen Skalierung
Um zu überprüfen, ob die Skalierung bei höherer Auslastung ausgelöst wird, verwenden wir ein BusyBox Image in einem Container. Es führt ein Shell-Skript aus, um den im vorherigen Abschnitt erstellten REST-Endpunkt unendlich aufzurufen. BusyBox ist ein leichtes Image vieler gängiger Unix-Dienstprogramme – wie wget – mit deren Ausführung wir den Pod, auf dem der Microservice läuft, kontrolliert belasten.
Speichern Sie die folgende YAML-Konfiguration in einer Datei mit dem Namen infinite-calls.yaml. Am Ende des Codes ruft der Befehl wget die REST-API in einer Endlosschleife auf.
apiVersion: apps / v1
Art: Bereitstellung
Metadaten:
Name: Unendliche Anrufe
Etiketten:
App: Unendliche Anrufe
spec:
Repliken: 1
Wähler:
matchLabels:
App: Unendliche Anrufe
Vorlage:
Metadaten:
Name: Unendliche Anrufe
Etiketten:
App: Unendliche Anrufe
spec:
Behälter:
- Name: Unendliche Anrufe
Bild: Busybox
Befehl:
- / bin / sh
- -c
- "während wahr; wget -q -O- http: // microsvc: 8080 / employee; erledigt"
Stellen Sie diese YAML-Konfiguration mit dem Befehl Kubectl apply -f infinite-calls.yml bereit.
Sobald der Container aktiv ist, starten Sie mit dem Befehl kubectl exec -it <CONTAINER_NAME> eine / bin / sh-Shell auf dem Container, um herauszufinden, ob ein Prozess läuft. Nun führen Sie unendlich lange Webanfragen aus. Diese unendlichen Aufrufe führen zu einer Belastung der Anwendung und zu stärkerer Prozessorauslastung in dem Container, auf dem sich diese Webanwendung befindet.
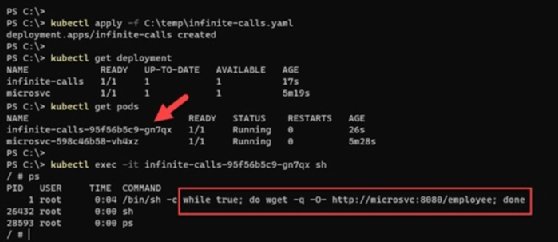
Nach einigen Minuten mit erhöhter Last beginnt HPA, den Anstieg der CPU-Auslastung zu registrieren und skaliert automatisch. Er erstellt die maximal erlaubte Zahl an Pods – in unserem Beispiel vier – um die CPU-Auslastung unter 50 Prozent zu halten.
kubectl get hpa -w

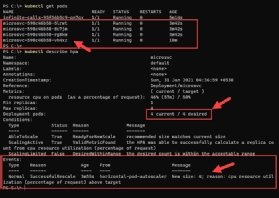
Führen Sie den folgenden Befehl aus, um Ereignisse und Aktivitäten von HPA detailliert anzuzeigen. Beachten Sie dazu den hervorgehobenen Abschnitt in Abbildung 7 für die Ereignisse und Auslöser der automatischen Skalierung.
Kubectl describe hpa
Vertikaler Pod Autoscaler
VPA erhöht und verringert die CPU- und Speicherressourcenanforderungen von Containern, um die zugewiesenen Ressourcen und die tatsächliche Nutzung besser aneinander anzupassen. Containerressourcenlimits basieren auf Live-Metriken auf einem Metrikserver und nicht auf manuell festgelegten Richtwerten.
Mit anderen Worten: VPA nimmt Benutzern das manuelle Einrichten von Ressourcenlimits und -anfragen für die Container in ihren Pods ab.
VPA kann nur die Pods einschließen, die ein Replikations-Controller verwaltet und erfordert den Kubernetes-Metrikserver.
Ein VPA besteht aus drei Hauptkomponenten:
- Empfehlungen. Überwacht die Ressourcennutzung und berechnet Zielwerte. Im Empfehlungsmodus aktualisiert VPA die vorgeschlagenen Werte, beendet jedoch Pods nicht selbstständig.
- Updater. Fährt die Pods herunter, für die neue Ressourcenlimits festgelegt wurden. Da Kubernetes die Ressourcenlimits eines laufenden Pods nicht ändern kann, fährt VPA die Pods mit veralteten Limits herunter und ersetzt sie durch Pods mit aktuellen Ressourcenanforderungen und Grenzwerten.
- Zulassungs-Controller. Moderiert Anfragen für das Erstellen von Pods. Ist dem Pod eine aktive VPA-Konfiguration zugewiesen, schreibt der Controller Anfragen um, indem er die Pod-Spezifikation an seine Ressourcenempfehlungen angleicht.
Weitere Informationen zur Konfiguration von VPA und Beispiel-YAML-Dateien für das Einrichten lokaler Kubernetes-Cluster mit vertikaler Automatisierung, finden Sie hier.
Konflikte, Vorbehalte und Herausforderungen bei der automatischen Skalierung
Die automatische Skalierung von Kubernetes hat zahlreiche Vorteile: Sie macht die Infrastruktur in Produktionsumgebungen dynamischer und verbessert die Ressourcenauslastung, was wiederum Overhead reduziert.
Der Nutzen von HPA und VPA liegt auf der Hand, und viele Anwender könnten versucht sein, sie gemeinsam zu verwenden. Das kann jedoch zu Konflikten führen. Beispielsweise nutzen HPA und VPA Schwellenwerte zum Bewerten der CPU-Nutzung. Während VPA versucht, die Ressource zu beenden und eine neue mit aktualisierten Schwellenwerten zu erstellen, möchte HPA neue Pods mit alten Spezifikationen erstellen. Das kann zu falschen Ressourcenzuweisungen und Konflikten führen.
Um eine solche Situation zu vermeiden und HPA und VPA weiterhin parallel zu verwenden, sollten Sie also sicherstellen, dass die beiden Automatisierungsmechanismen jeweils unterschiedliche Metriken als Grundlage für die Skalierung nutzen.






