Wie BMW und Equinox Media auf Serverless Computing setzen
In den beiden Anwendungsbeispielen von BMW und Equinox Media sehen wir uns an, wie diese AWS- und Serverless-Architekturen zum Verarbeiten und Analysieren von Daten verwenden.

Serverless Computing erfreut sich immer größerer Beliebtheit, da IT-Teams versuchen, agilere Anwendungen zu erstellen. Entwickler nutzen es, um sich mehr auf den Code und weniger auf die Software und Hardware zu konzentrieren, und sie betrachten Serverless als ein Muss für Skalierbarkeit und Kosteneinsparungen.
AWS verfügt über ein robustes Serverless-Portfolio mit Tools wie AWS Lambda, AWS Fargate und AWS Step Functions. In den beiden folgenden Serverless-Beispielen sehen wir uns an, wie BMW und Equinox Media AWS – und Serverless-Architekturmuster – zum Verarbeiten und Analysieren von Daten verwenden.
Serverlose Infrastruktur und Analytik bei Equinox Media
Wie in der 2020 AWS re:Invent Session Serverless analytics at Equinox Media: Handling growth during disruption vorgestellt wurde, nutzt Equinox eine Data-Lake-Strategie und Serverless-Ressourcen, um die Fitnessplattform VARIS und ein SoulCycle-Fahrrad für den Heimgebrauch einzuführen.
„Equinox baute diese Technologien von Grund auf neu, daher war es sinnvoll, serverlose Cloud-Technologien zu verwenden“, sagt Elliott Cordo, der zum Zeitpunkt des Vortrags VP of Technology Insights bei Equinox Media war. Das Unternehmen entschied sich für Amazon Kinesis für das Daten-Streaming in Echtzeit, AWS Lambda für die ereignisgesteuerte Architektur, AWS Glue zum Laden der Daten, Amazon DynamoDB zum Speichern der Daten und Amazon Athena zum Analysieren der Daten.
„Equinox hat sich aufgrund der Skalierbarkeit und der Kosten für Serverless entschieden. Bei unbekannten Nutzungsmustern ist Serverless kostengünstiger, da Sie keine Infrastruktur bereitstellen müssen, die Sie möglicherweise nicht nutzen“, sagt Cordo. In Bezug auf die Datenanalyse war Serverless Computing die beste Lösung, da VARIS auf Empfehlungen durch maschinelles Lernen angewiesen ist, um das Benutzererlebnis zu verbessern. Die serverlose Datenanalyse speist kontinuierlich die Empfehlungs-APIs der Plattform.
Sehen wir uns einige der AWS Serverless-Architekturmuster an, die in diesem Beispiel zum Einsatz kommen.
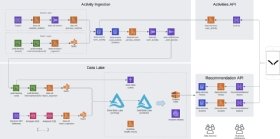
Die Architektur umfasst vier miteinander verbundene Elemente: Activities Ingestion, Data Lake, Activities API und Recommendation API. Diese Elemente sind sowohl untereinander als auch mit den Benutzergeräten verbunden. Cordo nennt es eine Data-Lake-First-Strategie: „Der Data Lake ist die einzige ‚Version of Truth‘ und ist so aufgebaut, dass er sowohl Rohdaten als auch verarbeitete Daten aufnehmen und mehrere Verarbeitungs-Engines unterbringen kann.“
In Abbildung 1 werden die Daten auf zwei Arten aufgenommen:
Speed Layer. Diese Schicht dient der skalierbaren, ereignisbasierten ETL-Speicherung (Extract, Transform, Load). Amazon API Gateway nimmt die Daten auf und eine Lambda-API validiert sie. Die Daten werden dann durch den ETL-Stream bewegt und gelangen in die DynamoDB-Aktivitätsschicht, wo sie durch Kinesis Data Firehose verarbeitet werden und schließlich in den Data Lake gelangen.
Batch Layer. Diese Schicht verarbeitet Flat- und JSON-Dateien. Equinox hat ein Queuing-System namens Queubrew eingerichtet, um die Daten zu verarbeiten. Queubrew verwendet API Gateway, Lambda und eine PostgreSQL-Version des Amazon Relational Database Service (RDS) für die Persistenz – die RDS-Instanz ist die einzige langlebigere Ressource in der Datenplattform.
Die RDS-Dateien gelangen von einem externen Amazon S3 Bucket in die Batch-Schicht, dann werden sie über Lambda kopiert, durch Queubrew geleitet und durch die DynamoDB-Aktivitätsschicht bewegt, wie im Speed Layer.
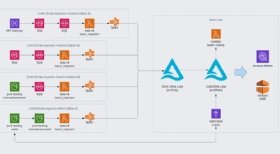
Allerdings stießen die Entwickler bei der Aufnahme einer großen Anzahl großer Dateien auf einen potenziellen Engpass, der zu einer schlechten Leistung in den Datenverarbeitungs-Engines führt. Um dieses Problem zu lösen, baute Equinox seinen Data Lake mit dem Open-Source-Dateiformat Delta Lake für seine zugrunde liegende Storage Engine. Delta Lake unterstützt Upsert-Operationen und native Komprimierung, die beide die Dateigröße reduzieren.
Durch die Integration mit Glue fungiert Delta Lake als zentrales Repository für alle Daten. Von dort aus können Datenanalysten und Business-Intelligence-Teams die benötigten Daten abfragen und sie mit Athena analysieren.
Mit diesem ereignisgesteuerten Setup führte Equinox VARIS mit einem vorhersehbaren, kostengünstigen Profil ohne Skalierungsprobleme ein.
Ereignisgesteuerte Analytik bei BMW
Globale Unternehmen wie BMW haben oft Schwierigkeiten, alle Daten, die sie erhalten, zu speichern und zu zentralisieren. Der ConnectedDrive-Backend-Service von BMW verarbeitet über eine Milliarde Anfragen pro Tag von seinen Fahrzeugen. Analysten müssen für Modellierungen oder Anwendungsfälle auf diese Daten zugreifen, egal ob sie in Deutschland oder Japan sitzen. Die re:Invent-Sitzung How BMW Group uses AWS serverless analytics for a data-driven ecosystem befasste sich mit der Datenpipeline des Unternehmens.
Der Cloud Data Hub von BMW ist ein zentraler Data Lake, der Daten aufnimmt, orchestriert und analysiert. Er dient der BMW-eigenen globalen IT-Gruppe sowie den Data Scientists und Business-Analysten, die Anwendungsfälle und Machine-Learning-Modelle erstellen. BMW verwendet AWS Glue und Kinesis Data Firehouse zum Einlesen von Daten, Amazon S3 und Glue für die Organisation und Orchestrierung sowie Amazon SageMaker, Athena und Amazon EMR für die Analyse der Daten.
Schauen wir uns das Setup an.
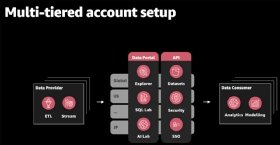
Dies ist eine mehrstufiges Konto-Setup, das heißt jeder Datenanbieter oder -verbraucher hat sein eigenes AWS-Konto – insgesamt mehr als 500. Es gibt drei Hauptkomponenten für dieses Setup:
- Datenaufnahme durch Glue- und Kinesis-Stream-Provider;
- Datenorchestrierung durch das Datenportal und die API-Schicht; und
- Datenanalyse durch Datenkonsumenten.
Die Software- und Dateningenieure von BMW betreiben den Datenmarktplatz des Automobilherstellers, wo sie sowohl globale als auch lokale Datenaufnahmen erstellen. Am anderen Ende der Pipeline können Analysten über ihr AWS-Konto auf die Daten zugreifen.
„Die wichtigste Funktion [des Cloud Data Hub] ist das zentrale Datenportal“, sagt Simon Kern, Lead DevOps Engineer bei der BMW Group. „Es ist die einzige Anlaufstelle für Sie, wenn Sie Daten von der BMW Group erhalten oder wenn Sie einen neuen Anwendungsfall erstellen möchten.“
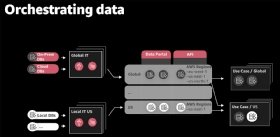
Innerhalb des zentralen Datenportals können Analysten Datensätze per SQL erkunden und abfragen, Metadaten verwalten und die notwendige Infrastruktur bereitstellen. Die Datensätze bestehen aus S3 Buckets und Glue, welches die Metadaten speichert und entweder für den globalen oder einen lokalen Hub spezifiziert ist. Diese Datensätze beruhen auf universellen APIs, welche die Verwaltung der Datensätze sowie Security, Compliance und Single Sign-On (SSO) übernehmen.
Aufnahme und Analyse sind relativ einfach. Wie wir bereits erwähnt haben, gibt es zwei Möglichkeiten, wie Daten in den Cloud Data Hub gelangen:
- AWS Glue. Daten können aus relationalen Datenbanken verarbeitet werden.
- Amazon Kinesis. Daten können aus der vernetzten Fahrzeugflotte von BMW einströmen.
Die Daten durchlaufen dann das Datenportal und die API, wo sie in Services wie Amazon SageMaker für die Erstellung von Machine-Learning-Modellen und Athena für die Datenanalyse verwendet werden können.
Wie Equinox stieß auch BMW nach der Datenaufnahme auf ein Dateiproblem. Um dies zu lösen, wurde ein Verdichtungsmodul entwickelt, das auf Glue läuft. Dieses Modul crawlt, findet kleine Dateien und verbindet sie zu größeren Dateien.
BMW startete dieses Projekt im Jahr 2019 und hat seitdem 15 Systeme und ein PB an Daten eingelesen.







