Fehlermanagement (Fault Management)

Fehlermanagement, Störungsmanagement oder englisch Fault Management ist die Komponente des Netzwerkmanagements, die sich mit der Erkennung, Isolierung und Lösung von Problemen befasst. Richtig implementiert, kann das Netzwerkfehlermanagement dafür sorgen, dass Konnektivität, Anwendungen und Dienste optimal funktionieren, Fehlertoleranz bieten und Ausfallzeiten minimieren. Plattformen oder Werkzeuge, die speziell für diesen Zweck entwickelt wurden, werden als Fehlermanagementsysteme bezeichnet.
Fehler entstehen durch Fehlfunktionen oder Ereignisse, die die Bereitstellung von Diensten stören, verschlechtern oder behindern. Beispiele für Fehler sind Hardwareausfälle, Verbindungsverluste oder Änderungen des Port-Status. Sobald ein Fehler erkannt wird, benachrichtigt die Verwaltungsplattform den Administrator (und alle weiteren autorisierten oder benannten Parteien) mit einem Alarm oder einer Warnung. Diese Benachrichtigungen können in der grafischen Benutzeroberfläche des Fehlermanagementsystems angezeigt werden, viele Plattformen können diese Warnungen aber auch per E-Mail, SMS und/oder über eine mobile App weiterleiten.
Darüber hinaus lassen sich Netzwerk-Fehlermanagementsysteme so konfigurieren, dass bestimmte Ereignisse mittels Programmen und Skripten automatisch behoben oder sogar verhindert werden.
Das Fehlermanagement ist eine Komponente von FCAPS (Fault Management, Configuration, Accounting, Performance and Security), einem von der International Organization for Standardization (ISO) geschaffenen Rahmenwerk für das Netzwerkmanagement.
Wichtige Funktionen des Fehlermanagements
Insgesamt umfasst das Fehlermanagement eines Netzwerks eine Vielzahl von Funktionen. Hier sind einige Beispiele für Aktionen und Dienste, die von Fehlermanagementsystemen zur Aufrechterhaltung des Netzwerkbetriebs durchgeführt werden:
- festlegen von Schwellenwerten für potenzielle Fehlerzustände
- ständige Überwachung des Systemstatus und des Nutzungsgrads
- kontinuierliches Scannen nach Bedrohungen, zum Beispiel Viren und Trojanern
- allgemeine Diagnose
- fernsteuern von Systemelementen, einschließlich Workstations und Servern, von einem einzigen Standort aus
- Alarme, die Administratoren und Benutzer über drohende und tatsächliche Fehlfunktionen informieren
- verfolgen der Standorte potenzieller und tatsächlicher Störungen
- automatische Korrektur von potenziell problemverursachenden Bedingungen
- automatische Behebung tatsächlicher Störungen
- detaillierte Protokollierung des Systemstatus und der durchgeführten Maßnahmen
Arten des Fehlermanagements
Es gibt zwei Arten des Fehlermanagements im Netzwerk: aktives und passives Fehlermanagement.
Beim aktiven Fehlermanagement werden verschiedene Tools wie Ping oder TCP/UDP-Port-Checks eingesetzt, um Geräte kontinuierlich abzufragen und ihren Status zu ermitteln. Es ist vergleichbar mit einer Person, die jeden im Raum in wiederholten Abständen fragt: "Wie geht es Ihnen?" Auf diese Weise kann das Fehlermanagementsystem potenzielle Probleme proaktiv und in Echtzeit erkennen sowie beheben – manchmal sogar, bevor sie zu Problemen werden –, doch der Preis dafür ist ein größeres Geplapper im Netzwerk.
Passive Fehlermanagementsysteme hingegen überwachen ihre Netzwerkumgebung auf Ereignisse, die auf einen Fehler oder Ausfall hinweisen. Diese Informationen können unter anderem aus Fehlerprotokollen oder SNMP-Traps stammen. Es ist vergleichbar mit einer Person, die leise zuhört, bis jemand um Hilfe ruft. Das passive Fehlermanagement ist zwar ressourcenschonender, hat aber den Nachteil, dass es Fehler möglicherweise erst entdeckt, wenn es zu spät ist.
Prozess des Fehlermanagements
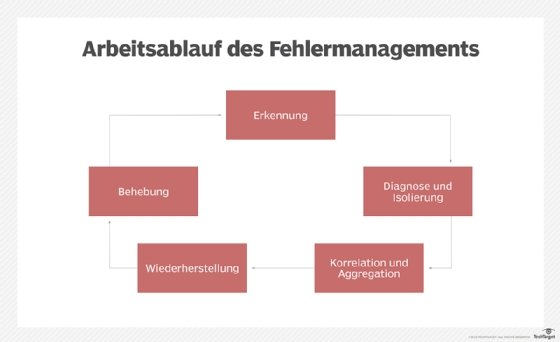
Obwohl der Ablauf beim Fehlermanagement bei kommerziellen Plattformen von Anbieter zu Anbieter leicht variieren kann, folgt er im Allgemeinen diesem Lebenszyklus, wenn ein Alarm ausgelöst wird:
- Fehlererkennung: Das System stellt fest, dass die Bereitstellung von Diensten unterbrochen wurde oder die Leistung nachgelassen hat.
- Fehlerdiagnose und -isolierung: Die Fehlerquelle, zum Beispiel ein Komponenten- oder ein Stromausfall, und ihre Position in der Topologie des Netzwerks werden ermittelt.
- Korrelation und Aggregation von Ereignissen: Da ein einziger Fehler mehrere Alarme auslösen kann, gruppieren Fehlermanagementsysteme häufig verwandte Ereignisse für Administratoren und bieten eine Ursachenanalyse.
- Wiederherstellung des Dienstes: Das Netzwerkmanagementsystem führt automatisch alle vorkonfigurierten Skripte oder Programme aus, um die Netzwerkdienste so schnell wie möglich wieder zum Laufen zu bringen.
- Problembehebung: Die Fehlerursache wird behoben, repariert oder ersetzt. Je nach Ursache kann auch ein manuelles Eingreifen erforderlich sein.






