
Olivier Le Moal - stock.adobe.co
Wie man Performance-Probleme in Python angeht
Python ist eine gute Sprache für Nicht-Programmierer, um mathematische und wissenschaftliche Aufgaben zu erledigen. Wie man Python-Leistungsprobleme beseitigt.
Python hat oft einen schlechten Ruf, was die Leistung angeht. Hier eine typische Diskussion zwischen einem Python-Entwickler und einem Kritiker:
Kritiker: Python ist nicht so schnell wie Java.
Fan: Doch, ist es. Sehen Sie sich diesen Benchmark an.
Kritiker: Der zählt nicht, weil es ein Single-Thread ist.
Fan: OK, sehen Sie sich diesen Multithreading-Benchmark an.
Kritiker: Es gibt nicht genug CPU-Kerne in diesem Benchmark.
Fan: Gut. Sehen Sie sich diesen Benchmark an.
Kritiker: Der zählt nicht, weil er eine C-Bibliothek verwendet.
Fan: Na und?
Dieses Hin und Her ignoriert oder verharmlost echte Probleme, die darüber entscheiden, wie man Probleme löst und die Arbeit erledigt.
Tatsache ist, dass Python eine gute Wahl für Nicht-Informatiker ist, die für Aufgaben in mathematischen und wissenschaftlichen Bereichen programmieren müssen. Eine Vielzahl von gut getesteten Python-Bibliotheken wurde entwickelt, um eine Leistung zu erzielen, die es mit anderen Programmiersprachen aufnehmen kann.
Python versus Java: Äpfel und Birnen
Python ist eine dynamisch typisierte Sprache. Sie wird oft mit Java verglichen, das eine statisch typisierte Sprache ist.
Dynamische Typisierung bedeutet, dass die Typüberprüfung in Python häufig während der Ausführung des Programms erfolgt. Java führt die gesamte Typüberprüfung zur Kompilierzeit durch. Wenn es eine nennenswerte Menge an Typüberprüfung gibt, ist es unangemessen, Python mit einer statisch typisierten Sprache zu vergleichen. Sie machen absichtlich unterschiedliche Dinge zur Laufzeit, auch wenn sie denselben Algorithmus implementieren.
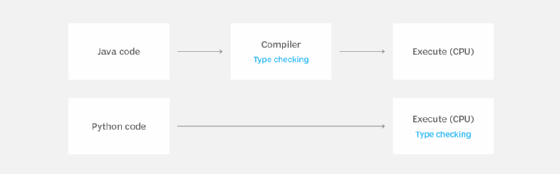
Gleichzeitig ist die Behauptung eines Python-Programmierers, dass es keine Leistungseinbußen gibt, unsinnig. Das gilt nur für Fälle, in denen die Typüberprüfung auf ein Minimum reduziert wurde, was in der Praxis nicht der Fall ist.
Ein Python-Programmierer sollte sich auf die Vorteile der dynamisch typisierten Sprache konzentrieren und darlegen, warum er der Meinung ist, dass die Kosten für die Laufzeitleistung es wert sind. Einige Beispiele sind:
- schnellere Entwicklung
- weniger ausführlicher Code
- leichter zu erlernen
- leichtere Verarbeitung von Daten
Über die Bedeutung – und den Wahrheitsgehalt – all dieser Argumente lässt sich streiten. Befürworter von statisch typisierten Sprachen können ihre eigene Liste von Argumenten vorlegen, warum ihre Sprache besser ist. Python-Entwickler sollten sich auf diese Unterschiede konzentrieren und nicht auf die Ausführungsgeschwindigkeit, um einen Vergleich zu ermöglichen.
Nicht-Informatiker finden dynamisch typisierte Sprachen einfacher zu erlernen und damit zu arbeiten als statisch typisierte Sprachen. Solange die Leistung angemessen ist, sollten sie eine dynamisch typisierte Sprache als Hilfsmittel für eine bestimmte Aufgabe wählen. Python eignet sich für fast jeden besser, der nicht programmiert, im Vergleich zu statisch typisierten Sprachen wie Java, C, C++ oder C#.
Wenn es Zweifel an der Leistungsfähigkeit dynamisch typisierter Sprachen gibt, stellen Sie ChatGPT zwei Fragen:
- Wie lese ich eine csv-Datei in Java?
- Wie lese ich eine csv-Datei in Python?
Vergleichen Sie die Erklärungen, und es ist klar: Python ist leichter umzusetzen für Nicht-Programmierer und Anfänger.
Multithreading und Pythons globale Interpretersperre
Die globale Interpretersperre (Global Interpreter Lock, GIL) in Python ermöglicht es dem Interpreter, Speicher oder Python-Objekte einfach und sicher zu verwalten. Allerdings verursacht GIL bei bestimmten Anwendungstypen Leistungsprobleme, da sie nur die gleichzeitige Ausführung von Python-Code durch einen Thread erlaubt. Abbildung 2 veranschaulicht das Problem mit der GIL in einer Anwendung mit zwei Threads, die auf einer CPU mit zwei Kernen laufen.
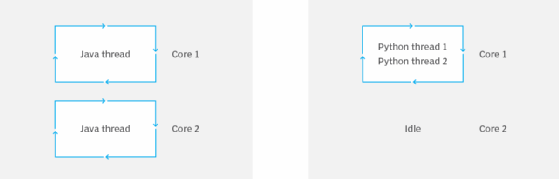
Das praktische Ergebnis der GIL ist, dass Python nur die Hälfte der CPU mit zwei Kernen und ein Viertel der Verarbeitungsleistung bei CPUs mit vier Kernen nutzt. Moderne CPUs haben oft viel mehr Kerne, was das Problem verschärft.
Nicht alle Python-Interpreter sind auf eine GIL angewiesen, aber der beliebteste Python-Interpreter, CPython, tut dies. Viele Leute haben dafür plädiert, GIL in Python 3.0 zu entfernen, da es ohnehin zu anderen Änderungen kommen würde. Hier ist, was Python-Schöpfer Guido van Rossum im Jahr 2007 sagte: „Ich würde eine Reihe von Patches in Py3k nur dann begrüßen, wenn die Leistung für ein Single-Thread-Programm (und für ein Multi-Thread-Programm, das aber I/O-gebunden ist) nicht abnimmt.“
Das Ersetzen der GIL durch andere Mechanismen zur Handhabung von Referenzierungszählung, Garbage Collection und Speicherverwaltungsaufgaben wird Single-Thread-Programme, die an die CPU gebunden sind, ausbremsen. Python hat also immer noch die GIL, obwohl es Bestrebungen (PEP 703) gibt, sie zu deaktivieren.
Überwindung der GIL zur Verbesserung der Leistung von Python
Es gibt einige Möglichkeiten für Python-Programmierer, das GIL-Problem zu umgehen.
Eine Möglichkeit besteht darin, mehrere Prozesse anstelle von mehreren Threads laufen zu lassen. Dadurch können mehrere Kerne gleichzeitig Python-Code ausführen. Allerdings entsteht dabei in der Regel ein Overhead durch redundantes Laden von Daten und Kommunikation zwischen den Prozessen. Außerdem kann dies die Komplexität der Anwendung erhöhen, was einige der Vorteile einer dynamisch typisierten Sprache zunichte macht.
Eine andere Möglichkeit, wie Python-Programme mehrere Kerne nutzen können, ist die Verwendung von C-Bibliotheken auf Threads, die nicht durch die GIL begrenzt sind. Hier kommt die Kritik „die eigentliche Arbeit wird in C erledigt“ her.

Die meisten Entwickler verwenden Bibliotheken, die sie nicht selbst geschrieben haben, und wissen nicht, in welcher Sprache die Bibliotheken geschrieben sind, oder es ist ihnen egal. Python-Entwickler sollten genauso vorgehen – wenn eine Bibliothek hilft, X besser zu machen, dann sollte man sie benutzen. Die anwendungsspezifische Logik wird immer noch in Python geschrieben und ist auch für Nicht-Informatiker leicht zu verstehen.
Die Verwendung einer C-Bibliothek für die numerische Verarbeitung auf niedriger Ebene unterscheidet sich nicht von der Verwendung einer Java-Bibliothek zur Implementierung der HTTP-Verarbeitung auf niedriger Ebene eines API-Servers.
Etwas vom Anwendungscode Getrenntes muss die notwendige, wiederholbare und schwierige Arbeit ausführen, und der Anwendungscode kontrolliert, wie diese Arbeit ausgeführt wird. Die Java-HTTP-Bibliothek verwendet die Java-Laufzeitumgebung (JRE), die ihrerseits native, in C geschriebene Methoden verwendet.
Es kann vorkommen, dass Sie Python-Anwendungscode in C implementieren müssen. Das ist vielleicht nicht ideal oder einfach, aber es ist eine vernünftige Lösung für Situationen, in denen die GIL einen Engpass darstellt. In der Regel kann es sich um eine einfache Implementierung eines Algorithmus handeln, während die Komplexität der Anwendung im Python-Code verbleibt.
Optionen für Python-Bibliotheken: NumPy und Pandas
Es gibt viele leistungsfähige Python-C-Bibliotheken, die eine hohe Leistung für wissenschaftliche Anwendungen bieten, die große Datenmengen in Arrays oder Matrizen verarbeiten. Sie arbeiten in C und umgehen daher die GIL-Thread-Beschränkung. NumPy und Pandas sind zwei beliebte Bibliotheken.
NumPy erstellt und verwaltet Arrays, zweidimensionale Matrizen und n-dimensionale Formen. Es kann eine große Anzahl von Operationen auf den Arrays durchführen, darunter fast alles, was eine wissenschaftliche Anwendung benötigt, wie zum Beispiel:
- grundlegende Arithmetik
- logische Funktionen
- schnelle Fourier-Transformationen
- lineare Algebra
- Trigonometrie
- Statistik
Die Implementierungen sind optimiert, und Multithreading kann bei Bedarf eingesetzt werden. Für große mathematische Datensätze ist eine Python-Anwendung mit NumPy genauso leistungsfähig wie jede andere Sprache.
Pandas, das auf NumPy aufbaut, bietet Datenmanipulationsfunktionen auf höherer Ebene und eine tabellarische Ansicht der Daten, ähnlich wie eine SQL-oder Excel-Tabelle. Seine Funktionalität importiert Daten aus verschiedenen Quellen, einschließlich SQL-, JSON-, Excel- und CSV-Dateien. Es verwendet auch matplotlib, um viele Arten von Visualisierungen der Daten zu erzeugen, wie zum Beispiel Balken-, Torten-, Linien- und Histogramme.
Zusammen decken Pandas und NumPy genügend der wichtigsten Programmieranforderungen ab, die Python-Entwickler für große Datenverarbeitungsfunktionen und eine Leistung benötigen, die sie in jeder anderen Sprache erreichen könnten.
Obwohl NumPy sehr leistungsfähig und effizient ist, gibt es Erweiterungen für bestimmte Klassen von Anwendungen. In vielen Fällen sind die Module, die zusätzliche Funktionen bieten, auf NumPy aufgebaut oder verwenden eine NumPy-ähnliche Schnittstelle, um die Lernkurve zu minimieren. Zu den zusätzlichen Funktionalitäten gehören:
- Verwendung von GPUs
- Deep Learning
- Dask Arrays zur Parallelisierung
- zusätzliche Datentypen
Python-Entwickler müssen die Datenstruktur korrekt und genau spezifizieren. Eines der Ziele der dynamischen Typisierung in Python ist, dass Funktionen unabhängig vom Typ der bereitgestellten Daten funktionieren sollten, solange diese Daten die Funktion zulassen.
Hier ist ein aktuelles Beispiel: Pandas hat eine CSV-Datei gelesen und eine Spalte mit Werten erzeugt. Es führt erfolgreich viele Fließkomma-Operationen auf der Spalte durch, kopiert die Spalte aber im Stillen viele Male in ein neues Array mit Fließkomma-Werten. Indem man Pandas den Spaltentyp mitteilt und die Spaltendaten beim Laden der Daten an Ort und Stelle ändert, kann eine 100-fache Leistungssteigerung erzielt werden.
Python ist eine gute Wahl für Programmierer, ob Anfänger oder Profi, die Code für bestimmte Aufgaben benötigen, zum Beispiel in mathematischen und wissenschaftlichen Bereichen. Zahlreiche und gut getestete Bibliotheken wurden optimiert, um Leistungsprobleme zu umgehen und Ergebnisse zu liefern, die mit denen anderer Programmiersprachen konkurrieren können.






