
Dukhanina Ekaterina - stock.adob
SAP Hub für generative KI: ein Einstieg
Der Hub für generative KI bündelt Modellzugriff, Prompt-Logik und Richtlinien. SAP-Anwendungen nutzen LLMs damit standardisiert, steuerbar und in bestehende Prozesse integriert.

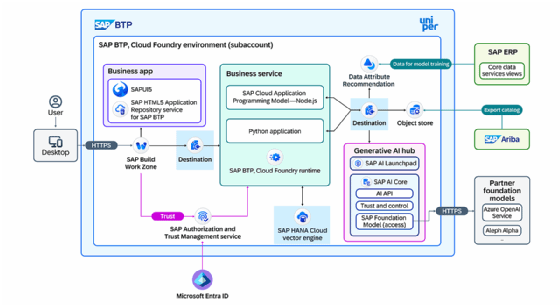
Ein generativer KI-Stack in der SAP Business Technology Platform (BTP) verlagert die Interaktion mit Large Language Models (LLM) in eine kontrollierte Laufzeitumgebung. Der Hub für generative KI (Generative AI Hub) bildet dabei die zentrale Zugriffsschicht innerhalb von SAP AI Core und bündelt Modellzugriffe, Orchestrierung, Prompt-Management und Governance in einer konsolidierten Architektur. Anwendungen greifen nicht direkt auf externe Modellanbieter zu, sondern adressieren eine standardisierte API, die sämtliche Zugriffe kapselt, steuert und protokolliert.
Architekturfluss und Zugriffspfad innerhalb von SAP BTP
Der Zugriff beginnt auf Anwendungsebene mit Clients, die Requests über HTTPS an die SAP Business Technology Platform (BTP) senden. Ein App Router übernimmt die Weiterleitung an Backend-Komponenten und verbindet Frontend-Anwendungen mit der Geschäftslogik. Diese Logik liegt in Application Services, die über Destination Services konfiguriert sind und Zielsysteme referenzieren. Authentifizierung und Autorisierung laufen über zentrale Trust- und Identity-Komponenten.
Der nächste Schritt führt in den API Hub, der als Vermittlungsschicht zwischen Anwendung und KI-Diensten fungiert. Innerhalb dieses Hubs befinden sich das SAP AI Launchpad zur Verwaltung und SAP AI Core als Laufzeitkomponente. AI Core stellt die eigentlichen Endpunkte bereit, verwaltet Deployments und übernimmt die Kommunikation mit Foundation-Modellen. Diese Modelle liegen entweder innerhalb der Plattform oder bei externen Anbietern, die über gesicherte Verbindungen angebunden sind.
Orchestrierung als Abstraktionsschicht für Modellzugriffe
Die Orchestrierung ersetzt direkte Modellaufrufe durch eine standardisierte Zugriffsschicht. Anwendungen definieren lediglich Parameter wie Modellname, Version und Prompt-Struktur. Ein Wechsel zwischen verschiedenen Modellen erfolgt ohne Änderung des Codes, indem nur der Modellparameter angepasst wird. Diese Abstraktion ermöglicht parallele Tests identischer Prompts gegen unterschiedliche Modelle und liefert vergleichbare Ergebnisse hinsichtlich Qualität, Kosten und Laufzeit.
Die Orchestrierung integriert zusätzliche Verarbeitungsschritte. Content Filtering entfernt unerwünschte Inhalte vor der Ausgabe. Data Masking anonymisiert sensible Informationen vor der Übergabe an externe Modelle. Prompt Templating strukturiert Eingaben und trennt statische Instruktionen von dynamischen Daten. Grounding ergänzt den Modellkontext durch externe Datenquellen und bildet die Grundlage für RAG-Szenarien (Retrieval-augmented Generation), bei denen Antworten auf Unternehmensdaten basieren.
Ein einzelnes Orchestration Deployment bündelt mehrere Modelle. Es ist nicht erforderlich, jedes Modell separat bereitzustellen. Stattdessen verwaltet eine Konfiguration den Zugriff auf alle erlaubten Modelle. Diese Konfiguration enthält Name, Executable, Szenario und Version und wird über SAP AI Launchpad erstellt. Nach erfolgreicher Bereitstellung wechselt der Status in den aktiven Zustand und steht Anwendungen als Endpoint zur Verfügung.
Modellrestriktion und kontrollierter Zugriff
Innerhalb eines Orchestration Deployments lassen sich Modelle gezielt einschränken. Eine Konfiguration definiert eine Liste erlaubter oder ausgeschlossener Modelle. Der Parameter modelFilterList enthält Modellnamen und optional Versionen. modelFilterListType steuert die Interpretation dieser Liste. Unter allow stehen ausschließlich definierte Modelle zur Verfügung. Unter deny werden definierte Modelle blockiert.
Diese Mechanik dient der Einhaltung interner Richtlinien und reduziert das Risiko unkontrollierter Modellnutzung. Gleichzeitig lassen sich neue Modelle temporär freigeben, ohne bestehende Anwendungen anzupassen. Die Einschränkung erfolgt zentral und wirkt sich unmittelbar auf alle angebundenen Anwendungen aus.
Modelllebenszyklus und Upgrade-Strategien
Die Verwaltung von Modellversionen beeinflusst Stabilität und Wartungsaufwand. Eine Konfiguration mit latest greift automatisch auf die aktuelle Version eines Modells zu. Diese Variante reduziert administrativen Aufwand, führt jedoch zu potenziellen Änderungen im Antwortverhalten. Anwendungen können unerwartete Unterschiede in Struktur oder Inhalt der Antworten erhalten.
Eine feste Versionsbindung verhindert solche Effekte. Anwendungen verwenden eine explizit definierte Modellversion und behalten damit ein konstantes Verhalten. Der Wechsel auf eine neue Version erfolgt kontrolliert nach Tests. Diese Strategie erhöht den Aufwand, bietet jedoch maximale Kontrolle und eignet sich für produktive Systeme mit stabilen Anforderungen.
Parametersteuerung und Modellcharakteristik
Die Qualität der Antworten hängt von Parametern ab, die im Request definiert sind. Temperatur beeinflusst die Varianz der Ausgabe. Niedrige Werte liefern deterministische Ergebnisse für strukturierte Aufgaben. Höhere Werte erzeugen variablere Antworten. Max Tokens begrenzt die Länge der Ausgabe und verhindert überlange Antworten. Presence Penalty reduziert Wiederholungen neuer Inhalte, Frequency Penalty reduziert Wiederholungen bereits verwendeter Tokens.
Die Auswahl des Modells orientiert sich an mehreren Faktoren. Komplexe Modelle liefern höhere Qualität bei anspruchsvollen Aufgaben, verursachen jedoch höhere Kosten. Spezialisierte Modelle eignen sich für domänenspezifische Inhalte. Latenzanforderungen beeinflussen die Wahl zwischen Echtzeitverarbeitung und Batch-Verarbeitung. Die Architektur erlaubt es, diese Faktoren parallel zu evaluieren, indem identische Anfragen gegen verschiedene Modelle ausgeführt werden.
Prompt Engineering als strukturierte Steuerungsebene
Prompts übernehmen die zentrale Steuerfunktion zwischen Anwendung und Modell. Sie definieren nicht nur den Inhalt einer Anfrage, sondern legen auch fest, in welcher Form die Antwort vorliegt und wie stabil sich das Verhalten des Modells im Betrieb verhält. Die Entwicklung erfolgt nicht linear, sondern in mehreren aufeinander aufbauenden Iterationen. Ein erster Entwurf liefert häufig noch unstrukturierte Antworten, die zwar inhaltlich brauchbar sind, sich jedoch nicht ohne Weiteres automatisiert weiterverarbeiten lassen.
Im nächsten Schritt folgt die systematische Präzisierung. Rollen bringen Struktur in die Interaktion. Die Systemrolle legt Verhalten, Grenzen und Regeln fest, wodurch sich die Ausgabe stabilisieren lässt. Die Userrolle enthält die eigentlichen Eingabedaten und bleibt variabel. Diese Trennung verhindert, dass sich Instruktionen und Nutzdaten vermischen und sorgt für reproduzierbare Ergebnisse.
Darauf aufbauend werden Antwortmöglichkeiten eingeschränkt. Freitext verliert an Bedeutung, stattdessen kommen definierte Wertebereiche und feste Kategorien zum Einsatz. Diese Einschränkung reduziert Interpretationsspielräume und verbessert die Konsistenz. Anschließend rückt das Ausgabeformat in den Fokus. Ein strikt vorgegebenes JSON-Schema ersetzt narrative Antworten. Anwendungen können die Ergebnisse dadurch direkt übernehmen, ohne zusätzliche Transformation oder Fehleranfälligkeit beim Parsen.
In der letzten Ausbaustufe wird das Verhalten weiter abgesichert. Der Prompt enthält explizite Vorgaben, die ausschließlich valide JSON-Strukturen erlauben und jede zusätzliche Ausgabe unterbinden. Unstrukturierte Texteingaben werden so schrittweise in präzise, maschinenlesbare Daten überführt. Erst in dieser Form lassen sich generative Modelle stabil in operative Prozesse integrieren, ohne dass nachgelagerte Systeme zusätzliche Logik zur Interpretation benötigen.
Prompt Registry und Template-Verwaltung
Mit zunehmender Komplexität reicht eine lokale Verwaltung von Prompts nicht aus. Die Prompt Registry speichert Prompts zentral und versioniert sie. Anwendungen greifen auf diese Definitionen zu, anstatt sie im Code zu hinterlegen. Ein Prompt Template definiert die Struktur eines Prompts mit Platzhaltern für dynamische Inhalte. Diese Platzhalter werden zur Laufzeit durch konkrete Daten ersetzt. Zusätzlich können Standardwerte und Modellparameter innerhalb des Templates definiert werden. Dadurch entsteht eine enge Kopplung zwischen Prompt und Laufzeitverhalten.
Die Verwaltung erfolgt über zwei Schnittstellen. Eine imperative API erlaubt direkte Änderungen und eignet sich für Entwicklung und Tests. Eine deklarative API integriert Templates in Versionskontrollsysteme. Änderungen erfolgen über Repository-Updates und werden automatisch in die Laufzeitumgebung übernommen. Diese Vorgehensweise integriert Prompt-Verwaltung in bestehende CI/CD-Prozesse.
Der Zugriff auf Templates erfolgt über eindeutige IDs oder Kombinationen aus Name, Szenario und Version. Eine ID garantiert unverändertes Verhalten. Versionsbasierter Zugriff erlaubt die Nutzung aktueller Varianten. Die Historie eines Prompts bleibt nachvollziehbar und unterstützt Analyse sowie Fehlerdiagnose.
Prompt Hardening und strukturelle Absicherung
Produktive Systeme erfordern robuste Prompts. Der Prompt enthält klare Einschränkungen, die unerwünschte Inhalte verhindern. Zusätzlich definiert er Regeln zum Umgang mit sensiblen Daten. Antworten enthalten ausschließlich die geforderten Felder und keine zusätzlichen Informationen.
Eine strukturierte Darstellung mit XML-ähnlichen Abschnitten trennt Instruktionen, Ausgabeformat und Eingabedaten. Diese Struktur reduziert Fehlinterpretationen durch das Modell und erhöht die Stabilität der Ausgabe. Ergänzend können Beispiele innerhalb des Prompts definiert werden, um gewünschtes Verhalten zu verdeutlichen.
Integration in Entwicklungsmodelle
SAP stellt Software Development Kits (SDK) für verschiedene Programmiersprachen bereit. Python eignet sich für datengetriebene Anwendungen. JavaScript und TypeScript integrieren sich in Full-Stack-Anwendungen. Das SAP Cloud Application Programming Model (CAP) unterstützt cloud-native Anwendungen innerhalb des SAP-Ökosystems. Java deckt klassische Enterprise-Anwendungen ab.
Alle SDKs greifen auf dieselbe Orchestrierungsschicht zu. Entwickler definieren Modellparameter, Prompt-Struktur und Zielmodell. Die Ausführung erfolgt über standardisierte Methoden, wodurch sich Implementierungen vereinheitlichen lassen.
Erweiterte Integrationsszenarien
Die Integration generativer KI beschränkt sich nicht auf einzelne Anwendungen. Die Architektur unterstützt Prozessintegration, ereignisgesteuerte Integration, API-Integration sowie Datenintegration. Diese Ebenen verbinden generative KI mit bestehenden Geschäftsprozessen und ermöglichen eine durchgängige Automatisierung.
API-Management übernimmt dabei die Steuerung externer Schnittstellen. Neue Serverinstanzen und Feedbackmechanismen erlauben eine kontinuierliche Anpassung der Nutzung und unterstützen die Bewertung von Integrationsstrategien.
Erweiterte Nutzungsszenarien und Modelle
Neben Beschaffungsszenarien ergeben sich weitere Anwendungsfelder in Recruiting, Asset Management und dialogbasierten Systemen. Der Hub für generative KI stellt Zugriff auf verschiedene Modelltypen bereit, darunter SAP-eigene Modelle sowie Modelle externer Anbieter. Modelle wie SAP-ABAP-1 analysieren ABAP-Code, SAP-RPT-1 unterstützt Prognosen. Parallel lassen sich Modelle verschiedener Anbieter in einer Umgebung testen.
Ein interaktiver Playground ermöglicht Tests von Prompts, Parametern und Modellverhalten. Entwickler analysieren Auswirkungen von Metadaten und vergleichen Ergebnisse direkt innerhalb der Plattform.
Betrieb und Kostenkontrolle
Die Nutzung generativer Modelle basiert auf dem Token-Verbrauch. Optimierungsläufe für Prompts reduzieren Kosten durch effizientere Anfragen. Gleichzeitig ermöglicht die Orchestrierung eine zentrale Kontrolle über Nutzung und Ressourcenverbrauch. Automatisierte Optimierungsmechanismen analysieren Prompt-Performance und passen Konfigurationen an.
Die Kombination aus Orchestrierung, Prompt-Management und Governance bildet eine kontrollierte Umgebung für generative KI. Anwendungen greifen über standardisierte Schnittstellen auf Modelle zu, während zentrale Mechanismen Zugriff, Verhalten und Versionierung steuern. Dadurch lässt sich generative KI in bestehende Unternehmensprozesse integrieren, ohne Kontrolle über Daten, Kosten und Verhalten zu verlieren.




