
Andrey Popov - stock.adobe.com
Edge Computing: in welchen Anwendungsfällen es sich eignet
Edge Computing ist nicht für jedes IoT-Gerät oder jeden Workload geeignet. Wir erläutern anhand von Beispielen, wo und wann der Einsatz in Ihrer Architektur sinnvoll ist.

Edge Computing erfreut sich aufgrund seiner Leistungsfähigkeit, Sicherheit und Kostenvorteile gegenüber herkömmlichen Cloud-Architekturen wachsender Beliebtheit, ist aber nicht immer die beste Lösung für verteilte Workloads.
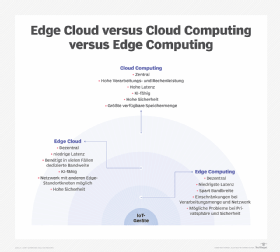
Edge Computing ist eine Bezeichnung für solche Architekturen, die Daten direkt in oder in der Nähe von Geräten verarbeiten, die diese Daten erzeugen und benötigen. Das sind zum Beispiel Endbenutzer-PCs, Mobiltelefone oder IoT-Sensoren (Internet of Things, Internet der Dinge). Das unterscheidet es von herkömmlichem Cloud Computing, bei dem zentrale Server Daten empfangen, verarbeiten und an Client-Geräte zurücksenden.
Edge Computing kann die Netzwerklatenz reduzieren, die Belastung des Netzwerks durch Datenverkehr verringern und in einigen Fällen die Kosten senken, indem die Verarbeitung auf die Geräte der Endnutzer ausgelagert wird.
Aufgrund der genannten Vorteile gehen manche Cloud-Architekten dazu über, so viele Workloads wie möglich an den Edge zu verlagern. Zuvor sollten sie jedoch unter anderem den Aufbau der vorhandenen Anwendung, die Leistungs- und Sicherheitsanforderungen berücksichtigen.
Zwei Arten von Edge-Computing-Architekturen
Zunächst gilt es abzuwägen, welche der beiden Varianten von Edge Computing in Frage kommen:
Device Edge Computing, bei dem die Client-Geräte die Daten direkt verarbeiten.
Cloud Edge Computing, bei dem die Edge-Hardware, die geografisch näher an den Client-Geräten liegt als zentralisierte Cloud-Rechenzentren, die Daten verarbeitet.
Das Device-Edge-Modell ist gut geeignet, wenn die Client-Geräte in der Lage sind, die erforderliche Verarbeitungslast zuverlässig zu bewältigen. Handelsübliche PCs oder Laptops sind dafür ausgerüstet, aber IoT-Sensoren mit niedrigem Stromverbrauch verfügen möglicherweise nicht über die für eine effiziente Datenverarbeitung erforderlichen Rechen- und Speicherressourcen.
Bei einem Device-Edge-Modell kann es auch dann zu Schwierigkeiten kommen, wenn viele verschiedene Arten von Edge-Geräten und Betriebssystemen im Einsatz sind, die alle über unterschiedliche Fähigkeiten und Konfigurationen verfügen.
Beim Cloud-Edge-Modell spielen die Endgeräte bei der Gestaltung der Architektur keine wesentliche Rolle, da die Datenspeicherung oder -verarbeitung nicht von der zentralen Cloud auf diese Geräte verlagert wird. Stattdessen laufen diese Prozesse auf Servern, die am Edge der Cloud positioniert sind. Diese Server befinden sich in der Regel in einem Rechenzentrum, das näher an den Endbenutzern liegt als die zentrale Cloud.
Einschränkungen beim Edge Computing
Bevor man sich entscheidet, einen Workload an den Edge zu verlagern, sollte man prüfen, ob und welche Edge-Modelle für den konkreten Anwendungsfall geeignet sind. Scheitert das Implementieren, landet man schnell wieder bei einem traditionellen Cloud-Modell.
Sicherheit am Edge
Edge Computing reduziert einige Sicherheitsrisiken, da sich Daten nur für minimale Zeiträume in der Übertragung befinden, führt aber dafür neue, komplexe Sicherheitsprobleme ein.
Wer zum Beispiel Daten auf Geräten von Endbenutzern speichern oder verarbeiten will, die er nicht kontrolliert, kann die Sicherheit dieser Geräte nur schwer garantieren. Auf diesem Weg kann eine Device-Edge-Infrastruktur verwundbar werden. Selbst wer ein Cloud-Edge-Modell verwendet, bei dem er die Kontrolle über die Edge-Infrastruktur behält, vergrößert die Angriffsfläche, da es mehr Infrastruktur zu verwalten gibt und damit mehr Möglichkeiten für Fehler.
In der Regel ist es einfacher, Daten während der Übertragung über ein Netzwerk zu sichern, als während der Verarbeitung, da man sie bei der Verarbeitung verschlüsseln kann. Aus diesem Grund können die Sicherheitsnachteile des Edge Computing die Vorteile überwiegen.
Edge Computing ist demnach nicht ideal für Workloads mit hohen Sicherheitsspezifikationen. Ein Standard-Cloud-Computing-Modell mit seinen zentralisierten Servern birgt geringere Risiken für Unternehmen, die mit sensiblen Daten arbeiten oder besonders strengen Auflagen für Datensicherheit unterliegen.
Anforderungen an die Latenzzeit
Edge Computing verbessert die Anwendungsleistung und Reaktionszeiten, da die Daten nicht den Hin- und Rückweg zu und von Cloud-Rechenzentren zurücklegen müssen, um verarbeitet zu werden. Dies ist ein entscheidender Vorteil für Workloads, die möglichst kurze Kommunikationszeiten benötigen. Cloud-Anbieter fügen zwar immer weitere Rechenzentrumsstandorte hinzu, aber ihre großen Einrichtungen befinden sich oft an abgelegenen Orten weit entfernt von großen Bevölkerungszentren.
Die meisten Workloads haben eher niedrigere Latenzstandards. Im Vergleich zu einer herkömmlichen Cloud-Architektur kann ein Edge-Netzwerk die Reaktionsfähigkeit des Netzwerks nur um einige Millisekunden verbessern. Für Standardanwendungen sind die Verzögerungen, die mit herkömmlichen Architekturen einhergehen, akzeptabel.
Man sollte also genau abwägen, ob sich im vorliegenden Fall die Latenzverbesserungen wirklich lohnen, insbesondere, wenn man die zusätzlichen Kosten und den Verwaltungsaufwand berücksichtigt.
Datenmenge
Eine weiter Überlegung, die man vorab anstellen sollte, ist, wie groß die Datenmengen sind, die man verarbeiten möchte und ob eine Edge-Infrastruktur diese effizient bewältigen kann. Je mehr Daten die Workloads erzeugen, desto größer muss auch die Infrastruktur zur Analyse und zum Speichern dieser Daten dimensioniert sein. Es ist wahrscheinlich billiger und leichter zu verwalten, wenn die Daten in der Public Cloud liegen.
Demgegenüber sind solche Workloads, die weitgehend zustandslos sind oder keine großen Datenmengen involvieren, tendenziell gute Kandidaten für Edge Computing.
Beispiele für Edge Computing
Um zu verdeutlichen, wie ein guter Kompromiss beim Edge Computing aussehen kann, haben wir im Folgenden einige Beispiele für gute Edge-Computing-Anwendungsszenarien zusammengestellt:
- Autonome Fahrzeuge. Selbstfahrende Autos sammeln große Datenmengen und müssen in Echtzeit Entscheidungen für die Sicherheit der Passagiere und anderer Personen auf oder in der Nähe der Straße treffen. Latenzprobleme könnten bei den Reaktionszeiten der Fahrzeuge Verzögerungen im Millisekundenbereich verursachen, die anderen Verkehrsteilnehmern das Leben kosten könnten.
- Intelligente Thermostate. Diese Geräte erzeugen relativ wenig Daten. Darüber hinaus sammeln einige von ihnen private, sensible Daten, wie zum Beispiel die Tageszeiten, zu denen Bewohner nach Hause kommen und die Wärme regulieren. Diese Daten am Edge zu belassen, statt sie zentral zu speichern, ist praktisch und kann dazu beitragen, Sicherheitsbedenken zu zerstreuen.
- Ampeln. Ampeln haben drei Eigenschaften, die sie zu guten Kandidaten für Edge Computing machen: Die Notwendigkeit, auf Veränderungen in Echtzeit zu reagieren, eine relativ geringe Datenausgabe und zeitweilige Verluste der Internetverbindung.
Hier sind einige Beispiele dafür, für welche Anwendungsfälle sich Edge Computing nicht eignet:
- Konventionelle Anwendungen. Es ist schwer, sich eine konventionelle Anwendung vorzustellen, die wirklich von der Leistung oder Reaktionsfähigkeit einer Edge-Infrastruktur profitiert. Die Zeitersparnis beim Laden der Anwendung oder bei der Beantwortung von Anfragen beträgt einige Millisekunden. Diese Verbesserung ist die Kosten, die mit Edge Computing verbunden sind, selten wert.
- Videokamerasysteme. Videos erzeugen große Datenvolumen. Die Verarbeitung und das Speichern dieser Daten am Edge ist nicht praktikabel, da sie eine große und spezialisierte Infrastruktur erfordern. Es ist viel billiger und einfacher, die Daten in einer zentralen Cloud-Einrichtung zu speichern.
- Intelligente Beleuchtungssysteme. Systeme, mit denen sich die Beleuchtung in Gebäuden über das Internet steuern lässt, erzeugen nicht viele Daten. Aber Glühbirnen – auch intelligente – haben in der Regel nur eine minimale Verarbeitungskapazität. Beleuchtungssysteme benötigen auch keine besonders niedrige Latenzzeit – wenn es ein oder zwei Sekunden dauert, bis sich Lampen einschalten, ist das nicht weiter der Rede wert. Man könnte zwar eine Edge-Infrastruktur für die Verwaltung dieser Systeme aufbauen, lohnen würde sich das aber wahrscheinlich nicht.






