
Gorodenkoff - stock.adobe.com
Was man beim Protokollieren von Microservices beachten muss
Für die Protokollierung von Microservices braucht es eine zentralisierte Ansicht der verteilten Services. Das ist alles andere als trivial. Fünf Tipps hierzu.

Anwendungsprotokolle vereinfachen die Problemlösung im Support. Die Protokollierung von Microservices ist allerdings nicht trivial. Wenn Teams versuchen, Microservices zu protokollieren, stehen sie vor mehreren Herausforderungen. Unbedingt erforderlich ist dafür eine zentralisierte Ansicht mehrerer verteilter Services.
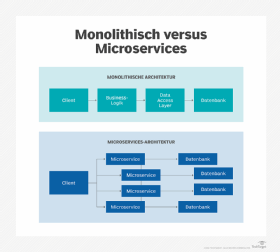
Ein Anwendungsprotokoll ist eine wesentliche Komponente jeder Anwendung. Dies gilt unabhängig davon, ob es sich um eine monolithische Anwendung handelt oder ob sie auf Microservices basiert. Allerdings stellen Microservices besondere Herausforderungen: Die Architektur von Microservices-basierten Anwendungen macht die Protokollierung zu einem komplizierten Unterfangen.
Bei Microservices laufen und kommunizieren ständig mehrere Services untereinander und erzeugen dabei ihre eigenen Protokolle. Wenn ein oder mehrere Services ausfallen, sollte das Team wissen, bei welchem Service ein Problem aufgetreten ist und warum. Es ist auch schwierig, den gesamten Anforderungsfluss in Microservices zu entschlüsseln. Welche Services wurden zum Beispiel aufgerufen? Und in welcher Reihenfolge und Häufigkeit wurde ein Service aufgerufen?
Es gibt jedoch einige Möglichkeiten, um die mit der Protokollierung von Microservices verbundenen Komplikationen zu umgehen. Dazu gehören aussagekräftige Protokolle, eine eindeutige Korrelations-ID zum Nachvollziehen der Anforderungen und eine Möglichkeit zum Verfolgen von Fehlern, die sich über mehrere Services erstrecken.
Beachten Sie jedoch, dass diese Praktiken leichter gesagt als umgesetzt sind. Und dass diese Probleme immer komplexer werden, wenn Unternehmen ihre Palette an Microservices über mehrere Apps hinweg erweitern. Deshalb ist es so wichtig, vorausschauend zu planen.
Eine Korrelations-ID verwenden
Eine bedeutende Herausforderung bei Microservices ist es, den Fluss der Ereignisse über Services hinweg zu verstehen. Die Protokollierung von Microservices muss deshalb den Transaktionspfad über mehrere Services berücksichtigen. Wenn Services andere Services aufrufen, die wiederum weitere Services aufrufen: wie findet man heraus, welcher Service bei welchem Aufruf fehlgeschlagen ist? Es besteht grundsätzlich die Möglichkeit, dass das Protokoll Millionen von Protokollnachrichten enthält. Hier hilft eine Korrelations-ID.
Eine Korrelations-ID ermöglicht die verteilte Ablaufverfolgung über Services hinweg. Eine Korrelations-ID ist eine eindeutige Kennung, mit der Entwickler Gruppen von Operationen trennen und einzelne Anforderungen verfolgen können. Dabei spielt es keine Rolle, wie die Korrelations-ID generiert wird, solange sie eindeutig ist, für nachgelagerte Services zugänglich ist und sorgfältig zusammen mit anderen wichtigen Daten zu Serviceaufrufen protokolliert wird.
Wenn eine Transaktion, die mehrere Services durchläuft, über eine Korrelations-ID verfügt, kann man bei der Fehlerbearbeitung eine ID-Suche in den Protokollen starten. Sie können sich dann Daten zu den einzelnen Serviceaufrufen anzeigen lassen, einschließlich der Häufigkeit, mit der ein Service verwendet wurde. Auf diese Weise kann die Korrelations-ID identifizieren, von welchem Service der Transaktionsfehler stammt.
Protokolle angemessen strukturieren
Microservices-basierte Anwendungen können mehrere Technologie-Stacks enthalten. Wenn eine solche Anwendung unterschiedliche Strukturen verwendet, um Daten in ihren Stacks zu protokollieren, kann dies die Standardisierung der Protokollierung behindern. Beispielsweise kann ein Service ein Pipe-Symbol als Begrenzer für Felder verwenden, während ein anderer Service ein Komma als Begrenzer verwendet. Dies bedeutet, dass Problemlöser die einzelnen Protokolle nicht auf dieselbe Weise analysieren können.
Entwickler sollten die Protokolldaten einer Anwendung deshalb strukturieren, um das Parsen zu vereinfachen und nur relevante Informationen zu protokollieren. Diese strukturierte Protokollierung hilft bei der Erstellung einfacher und flexibler Microservices-Protokolle.
Mit einer Datenvisualisierung können Sie sogar noch einen Schritt weiter gehen. Teams können der Microservices-Protokollierung eine Dashboard-Funktion hinzufügen. Diese liefert dann eine visuelle Darstellung der Informationen, die in den Anwendungsprotokollen enthalten sind.
Einen zentralen Protokollspeicher verwenden
Das Implementieren eines Protokollspeichers für jeden verteilten Microservice ist eine schwierige Aufgabe – allein schon deshalb, da jeder Service einen eigenen Mechanismus für die Ereignisprotokollierung benötigt. Mit zunehmender Anzahl von Microservices wird es immer schwieriger, diesen Ansatz zu verwirklichen.
Die Speicherung einzelner Protokolle erhöht die Komplexität beim Aufrufen und Analysieren von Protokollen erheblich. Senden Sie die Protokolle stattdessen an einen zentralen Speicherort, damit Sie leicht darauf zugreifen können. Durch das Aggregieren können Teams die Protokolldaten einfacher verwalten und miteinander korrelieren, um Probleme zu lösen.
Protokolle effizient abfragen
Die Fähigkeit, Protokolle effizient abzufragen, ist wichtig bei der Suche nach Fehlern, die über mehrere Microservices hinweg auftreten. Über die Korrelations-ID sollte ein Entwickler oder Tester in der Lage sein, auf den vollständigen Anforderungsfluss innerhalb der Anwendung zuzugreifen.
Teams können die Protokolldaten abfragen, um den Prozentsatz der fehlgeschlagenen Anforderungen zu ermitteln, die von jeder Anforderung benötigte Zeit und die Häufigkeit jedes Serviceaufrufs. Eine effizientere Möglichkeit besteht darin, ein Tool zu verwenden, das Protokolldaten wie ELK Stack, Splunk oder Sumo Logic aggregieren kann.
Ausfälle handhaben
Die Bereitstellung von Anwendungen sollte sich auch auf ein automatisiertes Warnsystem stützen. Dieses System kann die Protokolle analysieren und Warnmeldungen senden, wenn bei einem oder mehreren Services ein Fehler auftritt. Entwickler sollten auch das Timing von Fehlern berücksichtigen.
Zum Beispiel ist es möglich ist, dass die Protokollierungskomponente zu einer bestimmten Tageszeit aufgrund hoher Anmeldungen oder automatisierter Prozesse nicht verfügbar ist. Schließlich sollten die Anwendungen immer einen Fallback-Service enthalten, der mit Protokollierungsfehlern umgehen und bei Bedarf Protokolldaten wiederherstellen kann.
Informative Anwendungsprotokolle
Wenn ein Fehler auftritt, sollte das Protokoll alle erforderlichen Informationen zu dem Problem enthalten. Je mehr Informationen man bei der Fehlerbearbeitung aus den Protokollen der Microservices entnehmen kann, desto einfacher und schneller können sie feststellen, was schiefgelaufen ist.
Protokolle sollten mindestens die folgenden Informationen enthalten:
- Name des Service
- Nutzername
- IP-Adresse
- Korrelations-ID
- Empfangszeit der Nachricht in UTC, nicht in Ortszeit
- Zeitaufwand
- Name der Methode
- Call Stack
Erfahren Sie mehr über Softwareentwicklung
-
![]()
Ein Leitfaden zur Absicherung nicht-menschlicher Identitäten
Von: Dave Shackleford
-
![]()
Nutzer und Berechtigungen in Microsoft-Umgebungen verwalten
Von: Thomas Joos
-
![]()
IT Security: Bewährte Verfahren zum Umgang mit Logfiles
Von: Ed Moyle
-
![]()
Wie Sie Azure Functions mithilfe von Entra ID absichern
Von: Liam Cleary



