
Rawpixel.com - stock.adobe.com
Was ist die MTTR und wie hilft sie bei BC/DR?
Die Mean Time to Repair (MTTR) ist eine Kennzahl für die Fähigkeiten einer BC/DR-Lösung und des Anbieters, die sie bereitstellen. Lesen, Sie wie diese definiert und berechnet wird.

IT-Profis haben im Laufe der Jahre zahlreiche Metriken entwickelt, um die Leistung ihrer Technik zu messen. Das taten sie für technische Systeme, Prozesse und Komponenten. Wenn etwas nicht ordnungsgemäß funktioniert, benötigen Techniker und Entscheider eine Möglichkeit, um festzustellen, wie lange die Behebung eines Problems voraussichtlich dauern wird. Dies ist besonders wichtig im Bereich der Business Continuity (BC) und der Wiederherstellung nach Störungen (Disaster Recovery, DR).
Die mittlere Reparaturzeit (MTTR, Mean Time To Repair, manchmal auch „To Recovery“, also mittlere Zeit bis zur Reparatur beziehungsweise Wiederherstellung) ist eine seit Jahrzehnten übliche Kennzahl.
Sie gibt die durchschnittliche Zeitdauer an, die für die Reparatur eines Systems wahrscheinlich benötigt wird, bevor es wieder normal funktioniert. Je niedriger der MTTR-Wert ist, desto einfacher müsste es demnach sein, ein Problem zu beheben. Bei der Verwaltung von Systemen, Technik und Prozessen besteht das Ziel darin, die durchschnittliche Reparaturzeit zu verringern. Wenn die MTTR beispielsweise 0 beträgt (was quasi nicht machbar ist), ist die Wahrscheinlichkeit eines Ausfalls sehr viel geringer als bei einem positiven MTTR-Wert. Eine MTTR Null ist natürlich nur mit hohem Aufwand und Redundanz zu erreichen, beispielsweise durch automatisches Failover – gegebenenfalls eines Failovers eines kompletten Rechenzentrums einschließlich der Versorgung desselben – und weitere Maßnahmen.
Wenn das Ziel ein ununterbrochener Betrieb ist, bedeutet ein niedriger MTTR-Wert, dass das betreffende Element – falls es ausfällt – relativ leicht zu reparieren ist und nur wenig Zeit benötigt, um den normalen Betrieb wieder aufzunehmen.
Warum ist die MTTR eine wichtige Kennzahl?
MTTR ist ein entscheidendes Element in Plänen zur Geschäftskontinuität und Wiederherstellung im Katastrophenfall (BC/DR) und deshalb eine wichtige Kennzahl. Die Ermittlung der MTTR trägt dazu bei, dass Systeme ohne Unterbrechung funktionieren.
Bei Anlagen mit einer niedrigen MTTR ist typischerweise schon einmal die Wahrscheinlichkeit eines Ausfalls gering. Falls sie ausfallen, dauert die Wiederherstellung und Wiederaufnahme des normalen Betriebs nur wenig Zeit. Stellen BC/DR-Teams dagegen fest, dass ein System eine hohe MTTR hat, etwa vier bis fünf Tage, sollten sie es wahrscheinlich ersetzen. Updates und neuere Komponenten sind weitere Möglichkeiten, die MTTR in einem bestehenden System zu verringern. Die Unternehmensleitung muss entscheiden, ab welchem Schwellenwert eine hohe MTTR einen vollständigen Austausch oder eine Neugestaltung des Elements erforderlich macht.
Wie wird die MTTR berechnet?
Die MTTR ist ein Durchschnittswert aus der Analyse mehrerer Faktoren. Für einen bestimmten Zeitraum, zum Beispiel einen Tag, eine Woche oder einen Monat, wird für jede von der IT durchgeführte Reparatur die Zeit, die diese Reparatur in Anspruch nimmt, zu anderen ähnlichen Reparaturwerten addiert. Dieser Wert, der in der Regel in Stunden ausgedrückt wird, wird dann durch die Anzahl der ungeplanten oder unvorhergesehenen Reparaturereignisse während des Analysezeitraums geteilt. Darunter sind alle Ereignisse zu verstehen, die eine Reparatur erfordern, aber nicht geplant waren. Geplante Wartungszeiträume werden bei der MTTR-Berechnung allerdings nicht berücksichtigt.
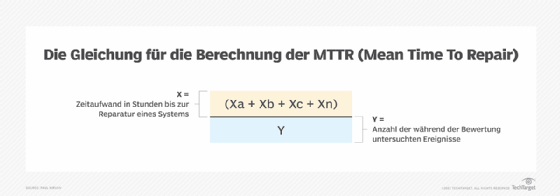
In der Praxis werden die BC/DR-Teams diese Berechnung auf eine Reihe von reparaturbedürftigen Ereignissen anwenden. Dadurch erhalten sie die MTTR. Auf dieser Grundlage lässt sich leichter abschätzen, auf welchen Wert die MTTR gesenkt werden muss, um einen unterbrechungsfreien Betrieb zu ermöglichen oder ob die derzeitigen Systeme ausreichen.
Diese Berechnung scheint zwar relativ einfach zu sein und BC/DR-Teams können sie leicht mit einer Tabellenkalkulation konfigurieren, aber es können auch Fehler entstehen. So geht die MTTR-Gleichung davon aus, dass die Aufgaben von entsprechend geschultem Personal nacheinander ausgeführt werden.

Wenn die Reihenfolge der Aufgaben geändert wird, wenn mehrere Aufgaben gleichzeitig ausgeführt werden oder wenn die Person, die die Aufgaben ausführt, nicht richtig geschult ist, kann die Berechnung zu einem falschen Ergebnis führen. Die Berechnung sollte gegebenenfalls auch berücksichtigen, dass im Katastrophenfall nicht das ausreichend geschulte Personal zur Verfügung steht. Dann werden Reparaturen eventuell durch Mitarbeiter vorgenommen, die sich anhand einer Anleitung dem Problem widmen. (Vorausgesetzt es sind Anleitungen dann auch verfügbar.) Die MTTR-Berechnung sollte daran angepasst werden – vielleicht durch die Messung einer Reparatur unter Worst-Case-Bedingungen.
MTTR und MTBF im Vergleich
Häufig wird in Verbindung mit der MTTR die mittlere Zeit zwischen zwei Ausfällen (MTBF, Mean Time Between Failure) eines Systems verwendet. Die MTBF ist eine weitere wichtige Leistungs- und Wartungskennzahl. Die MTBF drückt die durchschnittliche Zeit zwischen dem Auftreten von System- und Prozessausfällen in einem System aus. Diese Kennzahl gibt also Aufschluss über die Zuverlässigkeit eines Systems oder Prozesses.
Ähnlich wie bei der MTTR ist es unwahrscheinlich, dass ein System ausfällt, wenn der MTBF-Wert 0 beträgt. Dann kann das System als zu 100 Prozent zuverlässig angesehen werden. Da es jedoch zu Systemausfällen kommt, zeigt eine MTBF größer Null an, dass das System oder der Prozess mit einer Wahrscheinlichkeit ausfällt.
Ein MTBF-Wert über 0 (fünf bis 10 Stunden oder ein bis zwei Tage) bedeutet, dass das System oder der Prozess viel wahrscheinlicher ausfällt.
Eine MTBF von ein bis zwei Jahre steht für eine eher hohe Zuverlässigkeit des Systems. Dabei wird wohlgemerkt von einem möglichen Fehler ausgegangen. Die MTBF beschreibt zwingend nicht die Gesamtlebensdauer eines Systems oder die Zeit zwischen zwei Totalausfällen. Bei einer Festplatte kann die MTBF auch die Zeit zwischen Schreibfehlern oder die Positionierungsfehler beschreiben. IT-Verantwortlich bemühen sich also, den MTBF-Wert so hoch wie möglich zu halten, müssen aber trotzdem auf häufigere Ausfälle vorbereitet sein.

Sowohl MTTR als auch MTBF geben Aufschluss über die Lieferfähigkeit und Zuverlässigkeit eines Systems, Prozesses oder einer anderen Aktivität. Die Werte für jede Kennzahl können, wie beschrieben, auf Situationen hinweisen, in denen Abhilfemaßnahmen erforderlich sind.
Zu beachten ist, dass in komplexeren Systemen wie einem Computer für jede einzelne Komponente eine MTBF und eine MTTR betrachtet werden können. Ein Beispiel aus dem Alltag: Die Glühbirne in der Küchenlampe ist kaputt (MTBF einige hundert Stunden, MTTR einige Minuten), jedoch ist die Küchenschublade mit den Ersatzglühbirnen leer.
Es muss eine neue Glühbirne gekauft werden (MTBF Null, MTTR 46 Minuten). Dabei wird festgestellt, dass der Anlasser des Autos (MTBF einige Jahre, MTTR einige Tage) defekt ist beziehungsweise der Bus zum Supermarkt/Einzelhändler (MTBF einige Tage, MTTR eine Stunde) ausfällt. So steigert sich die MTTR für die Küchenlampe von einigen Minuten auf einige Tage, von der familiären Diskussion über notwendige Instandhaltungen mal abgesehen.
Wie man die MTTR verringert
Eine niedrigere MTTR bedeutet also, dass ein System oder Prozess gut funktioniert und schnell wiederherzustellen ist. Die Verringerung der MTTR für bestimmte Punkte beginnt mit der Festlegung einer Basis-MTTR, die den Ausgangspunkt bildet. Nachfolgende MTTR-Berechnungen im Vergleich zur Basislinie zeigen BC/DR-Teams und Administratoren, ob Fortschritte bei der System- und Prozessleistung erzielt wurden.
Es gibt zahlreiche Maßnahmen, die eine Organisation ergreifen kann, um die MTTR-Werte zu senken. Dazu gehören die folgenden:
- Aufbau eines Vorrats an Ersatzteilen und Komponenten für den Fall, dass eine Produktionskomponente ausfällt.
- Durchführung regelmäßiger Tests und Leistungsüberprüfungen, um sicherzustellen, dass die Systeme gut funktionieren.
- Durchführung einer Analyse der Auswirkungen auf das Geschäft, um festzustellen, welche Systeme und Prozesse am kritischsten sind, und Berechnung der MTTR zur Überwachung der Leistung.
- Hinzufügen von MTTR zu anderen Leistungsmetriken wie MTBF, Recovery Time Objective (Wiederherstellungszeitzielsetzung) und Recovery Point Objective (Wiederherstellungspunktzielsetzung).
- Einsatz eines optimierten Notfallplans, der geschäftskritische Anlagen schützt und eine rasche Reaktion auf eine Störung ermöglicht.
- Einsatz spezieller Schnellreaktionsteams, die auf System- und Prozessausfälle über ein Störungsreaktionsteam hinaus reagieren.
- Installation von Überwachungssystemen mit Sensoren, die Warnungen ausgeben, wenn Systeme nicht mehr ordnungsgemäß funktionieren.
- Rationalisierung der Helpdesk-Ressourcen zur Vereinfachung des Meldeprozesses, von der Problemerkennung bis zur Einreichung des Tickets.
- die Reparaturteams für die Geräte umfassend zu schulen und das Personal zu schulen, damit es als Backup dienen kann.
- Aktualisierung des Change-Management-Prozesses, um die Fehleranfälligkeit zu minimieren, zum Beispiel durch Hinzufügen von Verifizierungstests, um sicherzustellen, dass das System ordnungsgemäß funktioniert.





