
Ye Liew - Fotolia
NVIDIA, AMD und Intel: Drei unterschiedliche Ansätze zur GPU-Virtualisierung
Bei der GPU-Virtualisierung haben Unternehmen die Wahl zwischen NVIDIA, AMD und Intel. So unterscheiden sich die vGPU-Ansätze der drei Anbieter.

Die GPU-Virtualisierung erlangt derzeit wieder mehr Aufmerksamkeit, vor allem auch durch die Tatsache, dass NVIDIA mit Intel und AMD mittlerweile eine starke Konkurrenz erhalten hat. In diesem Artikel geht es weniger um konkrete Benchmark-Vergleiche, sondern vielmehr um einen Überblick über die grundlegenden Konzepte hinter der GPU-Virtualisierung mit NVIDIA, AMD und Intel.
Ein großer Teil der Informationen stammt dabei aus einem Vortrag, den Randy Groves von Teradici auf dem BriForum Boston 2016 gehalten hat.
Wie funktioniert eine GPU?
Bevor wir einen genaueren Blick auf die konkreten Ansätze werfen, sollten wir uns aber zunächst etwas allgemeiner mit den Grundfunktionen einer GPU befassen. Den größten Teil einer GPU machen Shader aus, die Grafikberechnung und Rendering für 3D-Modelle und ähnliches durchführen. Je mehr Shader, umso mehr Berechnungen können auch parallel durchgeführt werden. Je schneller sie sind, umso schneller werden die Berechnungen durchgeführt. Ganz pauschal gesagt machen vor allem die Shader eine GPU aus.
Shader können aber nicht nur für die Grafikberechnung eingesetzt werden, wie schon der Begriff General Purpose GPU (GPGPU) nahelegt. Da GPUs meist viele Shader enthalten und diese im Grunde nichts anders als Gleitkomma-CPUs sind, können sie sehr viele Berechnungen zur gleichen Zeit vornehmen, was als Parallel Computing bekannt ist. Diese Möglichkeit wird allerdings unterschiedlich genutzt, und zwar sowohl in physischen wie auch in virtuellen Umgebungen. Die Begriffe CUDA oder OpenCL bezeichnen Schnittstellen für parallele Rechenaufgaben, bei denen die GPU GPGPU-Aufgaben übernimmt und eben über CUDA- oder OpenCL-APIs angesprochen wird.
Zusätzlich zu Shader enthalten GPUs aber zum Beispiel auch Decoder und Encoder, die normalerweise aber nur einen kleinen Teil einer GPU ausmachen. Ob und wie sie verwendet werden hängt davon ab, ob die Anwendung das hardwarebeschleunigte Kodieren oder Dekodieren unterstützt und ob wiederum die GPU den verwendet Codec unterstützt.
Drei Ansätze zur GPU-Virtualisierung
Ganz generell gibt es drei unterschiedliche Ansätze, wie eine GPU virtuellen Maschinen zur Verfügung gestellt werden kann: API Intercept, GPU-Virtualisierung (vGPU) und Pass-Through.
Die älteste Variante, API Intercept, funktioniert auf dem Level von OpenGL und DirectX. Hierbei werden Befehle über eine API abgefangen, an die GPU gesendet, nach der Berechnung zurückgeholt und dem Anwender angezeigt. Da all dies rein über Software funktioniert, werden keinerlei GPU-Funktionen offengelegt. Allerdings hängen die Softwarefunktionen meist hinter denen physischer GPUs hinterher, vor allem was die API-Unterstützung betrifft.
API Intercept bietet im Normalfall eine gute Performance – wenn alles funktioniert –, hat aber mit Kompatibilitätsproblemen vor allem bei grafikintensiven Anwendungen zu kämpfen. Bislang ist dies aber die einzige Variante, die vMotion unterstützt.
Im Zusammenhang mit der Desktop-Virtualisierung ist vGPU die derzeit beliebteste Variante der GPU-Virtualisierung. Hierbei erhalten Anwender einen direkten Zugriff auf einen Teil der physischen GPU. Gegenüber dem API Intercept bietet dies den Vorteil, dass das Betriebssystem so die tatsächlichen Treiber von Intel, AMD oder NVIDIA verwenden kann, wodurch Applikationen native Grafikaufrufe statt einem generalisierten Subset nutzen können.
Damit bietet die GPU-Virtualisierung eine bessere Performance als API Intercept. Auch wenn Anwendungen direkten Zugriff auf die CPU erhalten, so doch nur auf einen kleinen Teil, und auch dieser Zugriff kann noch limitiert werden. vGPU bietet eine hohe Anwendungskompatibilität, unterstützt aber vMotion nicht.
Pass-Through ist schon länger auf dem Markt als vGPU-Konfigurationen und verbindet virtuelle Maschinen direkt mit einer GPU. Wenn man auf einem Server zwei Grafikkarten zur Verfügung hat, dann kann man auch lediglich zwei virtuelle Maschinen mit den beiden GPUs ausstattet – je eine Grafikkarte wird an eine virtuelle Maschine durchgeschleift. Alle anderen VMs auf dem Server gehen dann leer aus.
Pass-Through-Konfigurationen eignen sich daher lediglich für sehr grafikintensive Workloads, weil die Applikation so die komplette GPU zur Verfügung hat. Pass-Through bietet dabei eine recht hohe Anwendungskompatibilität, ist aber durch die alleinige Nutzung einer Grafikkarte durch nur eine virtuelle Maschine auch sehr kostspielig.
vGPU-Möglichkeiten mit Intel, AMD und NVIDIA
Da vGPU die momentan am weitesten verbreitete GPU-Virtualisierung für die Desktop-Virtualisierung darstellt, konzentrieren wir uns im Folgenden vor allem darauf. Im Großen und Ganzen gibt es derzeit drei Unternehmen, die im Bereich vGPU aktiv sind: Intel mit GVT-g, AMD mit MxGPU und NVIDIA mit GRID vGPU. Alle drei benutzen unterschiedliche Begriffe, die aber eigentlich nur Produktnamen darstellen. Was alle drei wirklich voneinander unterscheidet ist die Art und Weise, wie sie GPUs virtualisieren.
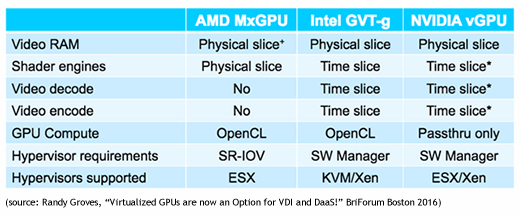
Video-RAM: Alle drei Ansätze stellen virtuellen Maschinen einen kleinen Teil physischer RAM-Ressourcen als Video-RAM zur Verfügung. Der große Unterschied liegt dann im Umgang mit diesem VRAM. Da AMDs MxGPU zu 100 Prozent hardwarebasiert ist, sind die individuellen Framebuffer der virtuellen Maschinen physisch voneinander isoliert. Bei NVIDIA und Intel dagegen wird diese Isolierung durch Software erreicht. In den meisten Fällen dürfte dies kaum von Bedeutung sein, in manchen Situationen könnten aber Fragen rund um die Framebuffer-Sicherheit zum Problem werden.
Shader-Engines: AMD unterscheidet sich auch mit Blick auf die Aufteilung der Shader-Engines von Intel und NVIDIA. Mit der MxGPU wird virtuellen Maschinen ein kleiner, dedizierter physischer Teil der Shader zugewiesen, während Intel und NVIDIA virtuellen Maschinen unterschiedliche Zeit-Slots über alle Shader hinweg zuordnen. Im Ergebnis erhalten Anwender per Time-Slicing für kurze Zeitperioden Zugriff auf die komplette GPU, während AMD andererseits die gesamte Zeit Zugriff auf einen kleinen Teil der GPU-Ressourcen bietet.
Wenn Anwender mit Intel- oder NVIDIA-GPUs wenige oder gar keine GPU-Ressourcen benötigen, dann macht das längere Zeitperioden für andere Nutzer frei. Je weniger Anwender, umso besser also die Performance. Mit AMD ändert die Anzahl der Anwender oder die Auslastung der zugewiesenen Ressourcen nichts an der Gesamt-Performance. Dediziert zugewiesene Shader bleiben in diesem Fall ungenutzt.
Weitere Artikel zur GPU-Virtualisierung:
Ist die GPU-Virtualisierung endlich bereit für den Enterprise-Einsatz?
GPU-Virtualisierung mit Citrix und VMware
So rendert GPU-Technologie komplexe Grafiken
Da das Time-Slicing mit Intel und NVIDIA aber durch Software geregelt wird, können GPUs nicht einfach so wieder in den generellen Pool zurücküberführt werden, bis nicht auch der letzte Befehl endgültig abgearbeitet wurde. Falsch ausgeführte Applikationen könnten so zu Problemen mit den GPU-Ressourcen anderer virtueller Maschinen führen.
Video-Kodierung/-Dekodierung: Bei der Kodierung und Dekodierung unterscheiden sich alle drei vGPU-Ansätze. AMD beispielsweise bietet überhaupt keine Funktion zur Kodierung oder Dekodierung mit MxGPU. Intel und NVIDIA setzen auch hierfür auf das Time-Slicing, wobei NVIDIA durch drei separate Time-Slice-Mechanismen für jede Komponente (Shader, Video-Kodierung und Video-Dekodierung) gegenüber Intel im Vorteil ist. Wenn ein Anwender beispielsweise lediglich Video-Daten kodiert, zieht dies deshalb weder die GPU an sich noch dekodierende Anwender in Mitleidenschaft.
GPU Compute: Die Grundlagen hierfür haben wir im ersten Teil bereits erklärt. Der große Unterschied zwischen den drei vGPU-Modellen besteht darin, dass AMD und Intel über virtuelle Maschinen OpenCL-APIs unterstützen, während NVIDIA GPGPU-Anwendungsfälle lediglich in Pass-Through-Konfigurationen unterstützt.
Hypervisor-Anforderungen: Sowohl Intel als auch NVIDIA setzen einen Software-Manager voraus, der im Hypervisor installiert werden muss. Das sollte zwar kein großes Problem darstellen, weil beide GPUs für bestimmte Plattformen zertifiziert sind, aber es ist immerhin ein zusätzlicher Schritt. AMD dagegen setzt hierfür auf Single-Root I/O-Virtualisierung (SR-IOV), was letztlich bedeutet, dass sich die MxGPU dem BIOS wie mehrere GPUs präsentiert, wodurch keine zusätzliche Software im Hypervisor selbst nötig ist.
Mit der Zeit kann man für alle drei Karten eine breite Unterstützung auf den wichtigsten Hypervisoren erwarten, aktuell gibt es aber durchaus noch Beschränkungen. AMD ist derzeit lediglich für ESXi zertifiziert, Intel unterstützt KVM und XenServer und NVIDIA ESXi und XenServer. Hyper-V wird dagegen von keinem der drei Anbieter unterstützt, aber auch das dürfte sich zukünftig ändern.
Folgen Sie SearchDataCenter.de auch auf Twitter, Google+, Xing und Facebook!





