Datenaustausch von Entwicklerteams und Machine Learning
Die Storage-Lösung Feast, die unter anderem von Google entwickelt wurde, bietet Speichermöglichkeiten für Machine-Learning-Projekte sowie effiziente Funktionen.
Geht es um die Entwicklung von Projekten im Machine-Learning-Bereich, arbeiten besonders häufig mehrere, verschiedene Teams zusammen. Hier wird es oft schwierig, Daten effektiv auszutauschen, vor allem wenn es keine Plattform gibt, die für ML optimiert ist. Dabei soll Feasthelfen. Im Fokus von Feast steht dabei auch die Bereitstellung von Features, die Teams untereinander austauschen können. Jedes Team kann Features in Feast hochladen und andere Features der anderen Teams im Projekt nutzen. Die Features können im laufenden Training der KI, aber auch im produktiven Betrieb nutzbar sein. Dazu kommt noch die Möglichkeit, eine Standardisierung von Features vorzunehmen, die über Feast austauschbar sind.
Feast und Kubeflow
Feast soll mit Kubeflow zusammenarbeiten. Dabei handelt es sich um ein Toolkit für die Entwicklung von ML-Projekten und den Betrieb mit Kubernetes. GO-JEK und Google Cloudhaben Feast als Open-Source-Feature-Store entwickelt. Daher ist der Betrieb über Kubeflow und Kubernetes naheliegend. Durch den gemeinsamen Datenspeicher können Entwickler einen zentralen Speicher nutzen, um wichtige Funktionen zu sichern und jederzeit zu finden, wenn diese benötigt werden. Vor allem bei internationalen Teams, die auch in verschiedenen Zeitzonen arbeiten, ist es sinnvoll, einen zentralen Datenspeicher bereitzustellen.
Im Fokus von Feast steht dabei auch die Bereitstellung von Features, die Teams untereinander austauschen können.
Features für verschiedene Anwendungsbereiche oder Projekte werden oft neu entwickelt, obwohl ein anderes Team bereits ein Feature entwickelt hat, das für den benötigten Einsatz ausreichend wäre. Das heißt, mit Feast lässt sich nicht nur die Arbeit effektiver durchführen, sondern auch deutlich Zeit sparen und doppelte Entwicklungen vermeiden, wenn bestehende Arbeiten anderer Teams hätten wiederverwendet werden können.
Teilweise ist es schwer, für manche Teams aktuelle Funktionen zu nutzen und in ML-Programmen einzubinden. Die Kombination von Streaming und Batch-Derivate-Funktionen sowie deren Bereitstellung erfordert Fachwissen, das nicht alle Teams haben. Die Aufnahme und Bereitstellung von Funktionen, die sich aus dem Streaming von Daten ergeben, erfordert außerdem oft eine spezialisierte Infrastruktur. Haben Teams dieses Wissen nicht parat, lassen sich Streaming-Daten oder andere Funktionen oft nicht einbinden. Liegen solche Features aber in Feast vor, können alle Teams das entsprechende Feature nutzen.
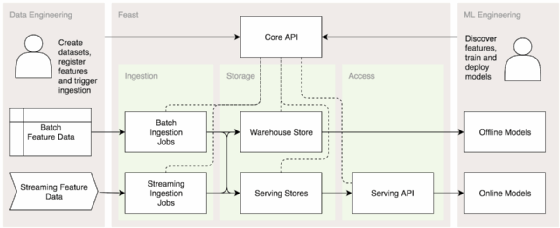
Feast kann auch die Erfassung von Featuredaten aus Batch- und Streaming-Quellen übernehmen. Auch Datenbanken für historische und aktuelle Daten lassen sich einbinden. Mit einem Python SDK können Anwender Trainingsdatensätze aus dem Feature „Warehouse“ generieren. Sobald das Modell bereitgestellt ist, kann es über eine Client-Bibliothek auf Featuredaten aus der Feast Serving API zugreifen.
Abbildung 1: Feast in die ML-Entwicklung einbinden
Einsatzgebiete von Feast
Feast ermöglicht es auch, dass Entwickler auf historische Featuredaten zugreifen können. Dadurch können Feast-Benutzer Datensätze von Features für die Verwendung in Trainingsmodellen erstellen. Der Vorteil besteht darin, dass dies eine Fokussierung auf die Modellierung und weniger Feature-Engineering ermöglicht.
Featuredaten, die in Feast gespeichert sind, stellt die Lösung für Modelle in der Produktion über eine Feature-Service-API zur Verfügung. Der Zugriff auf neue Funktionswerte erfolgt dabei mit geringer Latenz.
Feast unterstützt außerdem eine konsistente Verarbeitung und Datenaufnahme aus Batch- und Streaming-Quellen, zusammen mit Apache Beam. Das gilt für das Feature Warehouse und den Feature Serving Store. Teams sind mit Feast also in der Lage, Dokumentation, Metadaten und Metriken über Features zu erfassen.