
shintartanya - stock.adobe.com
Tipps zur Microservices-Verfügbarkeit in Ausnahmesituationen
Die COVID-19-Pandemie erhöht die Benutzeraktivität bei zahlreichen Anwendungen – das erfordert es, Leistung und Verfügbarkeit von Microservices zu skalieren.

Wenn die Benutzeranforderungen unerwartete und anhaltende Höchststände erreichen, werden die Skalierbarkeit und Fehlertoleranz einer Anwendung auf den Prüfstand gestellt. Die COVID-19-Pandemie ist dafür das Paradebeispiel. Softwarearchitekten sind besonders gefordert, da die Pandemie die Nachfrage nach verteilten Anwendungen steigert. Sie müssen wichtige Entscheidungen treffen, wie sie die Verfügbarkeit gewährleisten.
Microservices sind bei solchen Ereignissen ein Vorteil, da sie eine effizientere Skalierung als monolithische App-Architekturen ermöglichen. Schließlich müssen nur die Komponenten von Microservices, die mehr nachgefragt werden, mit mehr Instanzen hochgefahren werden.
Der Ressourcenverbrauch wächst zwar immer noch, jedoch ohne den Abfall, der bei monolithischer Skalierung anfällt. Für Unternehmen bedeutet das: Sie können die Elastizität und Resilienz monolithischer Anwendungen verbessern, indem sie benutzerbezogene Komponenten in Microservices umwandeln und die ständig verwendeten Komponenten in einem funktionalen Monolithen belassen.
Die Aufrechterhaltung einer hohen Verfügbarkeit für Microservices ist jedoch keine einfache Aufgabe. Mit den folgenden Expertentipps erfahren Sie mehr zu Skalierung und Replikationsmethoden sowie Grundlagen des Lastausgleichs und API-Gateways, um Microservices an die Anforderungen der Benutzer anzupassen. Sie lernen, hohe Verfügbarkeiten für Microservices sicherzustellen, indem Sie Caching einsetzen. Damit erzielen Sie eine hohe Leistung auch unter starken Lasten. Und ein Monitoring ist die Basis für eine schnelle Problemlösung.
Warum Skalierung von Microservices wichtig ist
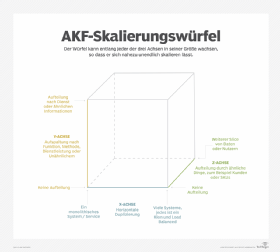
Anwendungsarchitekten skalieren Applikationen häufig auf drei Arten, die als X-, Y- und Z-Achsenskalierung bezeichnet werden (das folgende Bild zeigt einen von AKF Partners entwickelten Skalierungswürfel). Die X-Achsenskalierung wird verwendet, um die Skalierbarkeit und Verfügbarkeit des Systems mit mehr Instanzen oder Hardware zu erhöhen. Dazu werden oft Serviceinstanzen geklont, die sich dann hinter einem Load Balancer befinden.
Die Y-Achse setzt voraus, dass das System physisch in separate funktionale Teile zerlegt werden kann. Das System wird einer funktionalen Dekompression unterzogen. Diese verfeinert die Granularität, um die Skalierung einzelner Services als Reaktion auf Anforderungen zu unterstützen. Je nachdem, wie abhängig oder unabhängig diese voneinander sind, kann das mit einem höheren Kommunikationsaufwand einhergehen.
Schließlich weisen Entwickler bei der Z-Achsenskalierung Servern bestimmte Teilmengen replizierter Daten zu. Server mit demselben Code werden nur mit Teilen der Daten betrieben. Diese Server sind nur dazu bestimmt, diese bestimmte Teilmenge von Daten und Routeninformationen entsprechend zu verarbeiten.
Da die verschiedenen Skalierungsachsen unterschiedliche Auswirkungen auf die Entwicklung und den Betrieb haben, sollte auch aus betriebswirtschaftlichen Gründen genau überlegt werden, welche Qualitätsanforderungen das angestrebte System erfüllen soll.
Die Skalierung der Y-Achse ist direkt mit dem Design hochverfügbarer Microservices verknüpft, da Entwickler diejenigen Dienste, die unabhängig voneinander skalieren müssen, entsprechend segmentieren müssen. Aufgrund globaler Veränderungen in Bezug auf die Art und Weise, wie Menschen online arbeiten, lernen und spielen, kann die Z-Achse nun auch eine wichtige Rolle bei der Fehlertoleranz von Microservices spielen.
Da sich die Z-Achsenskalierung auf die Aufteilung von Servern basierend auf Eigenschaften wie dem geografischen Standort oder Kunden-IDs konzentriert, wird es viel einfacher, Fehler zu identifizieren und zu isolieren, die andernfalls zu Kaskadenfehlern über alle Dienste hinweg führen würden.
Skalierungsmethoden sind jedoch nicht das Ende der Entscheidungsmöglichkeiten eines Architekten. Es sind noch weitere Entscheidungen zur Überwachung, Nachverfolgung und Ressourcenzuweisung zu treffen. Joydip Kanjilal, Softwarearchitekt und technischer Berater, erläutert diese Probleme in einem früher veröffentlichten Artikel über die Skalierungsfähigkeiten von Microservices.
Service-to-Service Load Balancing
Entwickler, die besser mit monolithischen Architekturen vertraut sind, werden feststellen, dass der Lastausgleich bei Microservies ein zusätzliches Problem darstellt. Dies liegt daran, dass die Kommunikation in einer Microservices-Architektur von Service zu Service erfolgt und nicht wie bei monolithischen Anwendungen von Client zu Server. Aus diesem Grund suchen Entwickler jetzt nach neuen Load-Balancing-Techniken, mit denen Workloads gleichzeitig auf viele Dienste verteilt werden.
Eine Load-Balancing-Technik, die für die Hochverfügbarkeit von Microservices entwickelt wurde, ist das API-Gateway. Ein API-Gateway ist eine Komponente, die als einzelner Eintritts- und Verteilungspunkt für den Anwendungsverkehr und als Verbindungspunkt für unabhängige Komponenten fungiert. Client-Anforderungen werden an das Gateway gesendet, das diese Anforderungen als API-Aufruf empfängt. Anschließend wird ein weiterer API-Aufruf erstellt, der die Anforderung an den oder die entsprechenden Dienste verteilt. API-Gateways können auch Übersetzungen und Protokolle zwischen einzelnen Softwareteilen verwalten.
Der Technologieanalyst Twain Taylor hat einen Artikel geschrieben, in dem mehr Details über diese Techniken und die Auswirkungen der Service-zu-Service-Kommunikation auf den Lastausgleich dargestellt sind – einschließlich einer Überprüfung der cloud-nativen Tools und Werkzeuge von Drittanbietern, die für die Service-to-Service-Kommunikation entwickelt wurden.
Integriertes Daten-Caching
Ob eine App aktiv oder inaktiv ist, ist nur ein Verfügbarkeitskriterium. Eine wichtige Überlegung für hohe Verfügbarkeiten von Microservices ist auch die Leistung einer App. Am besten designen Sie die Anwendung mit integriertem Caching, um eine hohe Leistung unter hoher Last aufrechtzuerhalten.
Durch das Zwischenspeichern von Daten werden Informationen immer von einem Datenbankserver bereitgehalten, wenn ein Microservice sie benötigt. Durch Caching kann ein Ausfall auch maskiert werden, indem die Daten verfügbar gemacht werden, unabhängig davon, ob der Ursprungsdienst aktiv ist oder nicht.
Kanjilal schreibt in einem Artikel, der für Anwender von Microservices geschrieben wurde, von zwei Arten von Caches – Preloaded und Lazy Loaded. Er erklärt auch Möglichkeiten zur Optimierung von Ressourcen und zur Skalierung von Microservices mit gemeinsam genutzten Caches.
Überwachung und Tracing bei Problemen
Unabhängig davon, wie gründlich Sie Microservices mit hohen Verfügbarkeiten entwerfen: Um schnellstmöglich Probleme zu erkennen, die die Benutzererfahrung beeinträchtigen können, sollten Sie ein speziell auf Ihre Anwendungsarchitektur zugeschnittenes Monitoring bereitstellen.
Die schlechte Nachricht ist: Microservices erschweren die Überwachung. Im Gegensatz zu monolithischen App-Bereitstellungen werden verteilte Dienste gleichzeitig ausgeführt. Eine einzelne Aktion kann mehrere Dienste parallel aufrufen. Daher verdeckt dieser Architekturstil auftretende Fehler von Natur aus, da die Identifizierung eines einzelnen Fehlerpunkts exponentiell komplexer wird.
Um dieses Problem zu bewältigen, richten Sie am besten eine semantische Überwachung und verteiltes Tracing ein. Diese liefern ein klareres Bild der Verfügbarkeit und des Zustands von Diensten.
Die semantische Überwachung – sie wird auch als synthetische Transaktionsüberwachung bezeichnet – testet aus Anwendersicht die Funktionalität von Geschäftstransaktionen, die Serviceverfügbarkeit und die allgemeine Anwendungsleistung. Die Technik imitiert typische Anwenderaktivitäten und sammelt entsprechende Leistungsstatistiken, um Warnungen auszugeben, Servicelevel zu berechnen und Datenanalysen vorzunehmen.
Das verteilte Tracing ist eine weitere Technik. Sie überwacht den Pfad, den eine Anforderung durch jedes Modul oder jede Dienstinstanz nimmt, selbst wenn sie über verteilte Replikatinstanzen und mehrere Aufrufe übertragen wird.
Die Technologie liefert einfach Trace-Daten zwischen den verschiedenen Aufrufen der Microservices mit. Auf diese Weise können die Support-Teams für Anwendungen Fehler und Leistungsengpässe lokalisieren – ein wesentlicher Bestandteil der Hochverfügbarkeit von Microservices. Entwickler sollten so viel wie möglich darüber lernen, wie verteiltes Tracing funktioniert und welche Tools dabei helfen können.





