
Nelson - stock.adobe.com
Die Unterschiede zwischen Cloud, Fog und Edge Computing
Cloud, Edge und Fog Computing unterstützen moderne Anwendungen. Cloud-Computing zentralisiert Ressourcen, Edge ermöglicht Echtzeitverarbeitung und Fog verbindet sie hierarchisch.

Moderne verteilte Computing-Architekturen unterstützen bedeutende technologische Fortschritte, zum Beispiel KI und intelligente Fertigung. Jedes Computing-Modell ist entscheidend für die Unterstützung fortschrittlicher Anwendungen, die die Landschaft verändern, und damit für den Fortschritt in der Informationstechnologie.
Digitale Unternehmen verfügen über weitläufige virtuelle Umgebungen, die eine flexible und widerstandsfähige Infrastruktur erfordern. Diese muss mit den ständig steigenden Anforderungen an Verarbeitung und Speicherung Schritt halten können. Schätzungen zufolge wird die Zahl der vernetzten Geräte bis 2030 weltweit auf über 40 Milliarden steigen. Angesichts der massiven Steigerung der Ausgaben für die Entwicklung von KI-Anwendungen investieren Cloud-Anbieter Hunderte von Milliarden Dollar in den Ausbau von Rechenzentren.
Fortschrittliche digitale Anwendungen erfordern eine flexible, effiziente und zuverlässige Infrastruktur. Die zugrunde liegenden Verarbeitungs- und Speichermodelle, die dies ermöglichen, sind Cloud Computing, Edge Computing und Fog Computing. Jedes dieser Modelle spielt eine wichtige Rolle in der Infrastruktur. Obwohl sie oft als Gegensätze dargestellt werden, können sich die Modelle ergänzen.
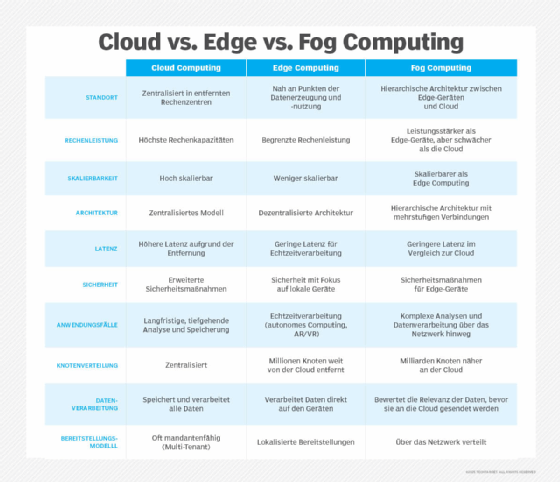
Cloud Computing vs. Edge Computing vs. Fog Computing
Alle diese Modelle haben ihren Ursprung im Grid Computing, einem in den 1990er Jahren entwickelten Konzept. Beim Grid Computing werden Rechenressourcen für rechenintensive Anforderungen in Anwendungen wie wissenschaftlicher Forschung, Spieledesign und Finanzrisikomanagement gebündelt. Zu den in Netzwerken gängigen digitalen Rechenmodellen gehören die folgenden:
- Cloud Computing: Bietet zentralisierte Ressourcen mit hoher Skalierbarkeit und Rechenleistung und ist somit ideal für langfristige Analysen und Speicherung geeignet.
- Edge Computing: Verarbeitet Daten direkt an oder in der Nähe der Quelle und ist somit nützlich für Echtzeitanwendungen mit geringen Latenzanforderungen.
- Fog Computing: Dient als Zwischenebene, analysiert die Wichtigkeit von Daten vor der Übertragung in die Cloud und ermöglicht eine verteilte Verarbeitung im gesamten Netzwerk.
Cloud Computing
Cloud Computing unterstützt eine Vielzahl von Diensten, darunter IaaS und SaaS. Dadurch können Rechen- und Speicherdienste nach Bedarf auf Basis eines Pay-per-Use- oder Abonnementmodells bereitgestellt werden, sodass keine Vorabinvestitionen in die Kapitalausstattung erforderlich sind.
Die Technologie entstand Mitte der 2000er Jahre, als der Online-Händler Amazon mit seinem On-Demand-Dienst Elastic Compute Cloud (EC2) den IaaS-Markt erschloss. EC2 nutzte die überschüssigen Kapazitäten aus dem eigenen Online-Handelsgeschäft, um kostengünstige, hochvolumige virtualisierte Rechendienste anzubieten. Amazon tat dasselbe mit Speicherplatz durch seine S3-Angebote (Simple Storage Service).
Die Vorteile liegen auf der Hand: Unternehmen können ihre Verarbeitungs- und Speicherkapazitäten schnell erhöhen. Cloud Computing nutzt ein konsolidiertes Computing-Modell, das es Clients ermöglicht, von einer zentralisierten Umgebung aus auf Ressourcen zuzugreifen. Cloud-Dienste können privat oder mandantenfähig sein, wobei sich die Clients die Hardware-Ressourcen teilen.
Die Sicherheit von Cloud Computing basiert auf umfassenden Maßnahmen, zum Beispiel Verschlüsselung, Zugriffskontrollen und kontinuierlicher Überwachung, um die in entfernten Rechenzentren gespeicherten Daten und Anwendungen zu schützen. So können Unternehmen Cloud-Dienste nutzen, ohne sensible Informationen zu gefährden.
Edge Computing
Computing ist zunehmend dezentralisiert und erfordert eine effektivere Bereitstellung von Rechenleistung für latenzempfindliche Anwendungen. Edge Computing spielt eine wichtige Rolle bei der Beschleunigung der Anwendungsleistung und der Steigerung der Effizienz.
Dabei werden Daten in der Nähe des Ortes, an dem sie erstellt und genutzt werden, verarbeitet und gespeichert. Die Hardware, darunter Edge-Server und hyperkonvergente Infrastruktur-Appliances, wird in sekundären oder tertiären Rechenzentren betrieben.
Cloud-Anbieter arbeiten häufig mit Drittanbietern oder Telekommunikationsbetreibern zusammen, um ihre Dienste für die lokale Verarbeitung auf den Edge-Bereich auszuweiten.
Anwendungsfälle für Edge Computing umfassen Anwendungen, die eine Echtzeitverarbeitung erfordern, zum Beispiel autonome Fahrzeuge, Augmented Reality und Virtual Reality sowie Smart Cities.
Zu den Sicherheitsfunktionen von Edge Computing gehören Verschlüsselung, Authentifizierung und physische Sicherheitsvorkehrungen, um unbefugten Zugriff zu verhindern und sensible Informationen näher an ihrer Quelle zu halten, anstatt sie an Cloud-Server zu senden.
Fog Computing
Fog Computing ist im Wesentlichen eine Erweiterung von Edge Computing. Es handelt sich um ein stärker verteiltes Modell, das mehrere Ebenen der Verarbeitung und Speicherung umfasst. Fog Computing stellt die Netzwerkinfrastruktur für die Rechenverarbeitung zwischen Edge-Geräten und Cloud-Computing-Einrichtungen bereit, ist jedoch nicht auf den Edge oder die Cloud beschränkt. Es unterstützt Anwendungsfälle wie komplexe Analysen und andere Datenverarbeitungsprozesse an dezentralen Punkten im gesamten Netzwerk.
Fog Computing schafft mehrere Schutzebenen über verteilte Verarbeitungsknoten zwischen Edge-Geräten und der Cloud. Es kombiniert lokale Authentifizierung, verschlüsselte Datenübertragung und zentralisierte Überwachung, um Informationen zu schützen, während sie verschiedene Ebenen der Netzwerkinfrastruktur durchlaufen.
Wie sind diese Modelle für fortgeschrittene Anwendungen aufeinander abgestimmt?
Anstatt davon auszugehen, dass Fog-, Edge- und Cloud-Computing gegensätzliche Modelle sind, ist es hilfreich, sich zu überlegen, wie sie zusammenarbeiten können. Jedes Modell hat eine einzigartige Rolle bei der Unterstützung von Anwendungsfällen, die sich in bestimmten Umgebungen ergänzen können. Betrachten wir das folgende Beispiel.
Cloud-Computing-Umgebungen sind oft mandantenfähig. Dies hält zwar die Kosten niedrig, wirft aber auch Fragen hinsichtlich der Sicherheit und der Einhaltung gesetzlicher Vorschriften auf. Aufgrund der Entfernung zwischen den Punkten der Datenerstellung und -nutzung ist Cloud Computing nicht dafür optimiert, Anwendungen mit geringen Latenzanforderungen zu unterstützen. Hier kommt Edge Computing ins Spiel.
Edge Computing ist eine natürliche Erweiterung von Cloud Computing. Es wendet Cloud-Dienste in der Nähe der Punkte der Datenerstellung und -nutzung an, um Echtzeitanalysen zu ermöglichen. Die Natur von Edge-Computing-Implementierungen passt gut zu lokalen Anforderungen an die Datenresidenz und berücksichtigt somit Sicherheits- und Datenschutzbedenken.
Allerdings werden Daten nicht immer am Ort ihrer Erstellung verarbeitet. In komplexeren Anwendungsfällen, in denen die Datenverarbeitung an verschiedenen Netzwerkknotenpunkten stattfindet, ist Fog Computing nützlich. Dies ist wichtig für groß angelegte Anwendungen, die Analysen über Standorte und Geräte hinweg durchführen, zum Beispiel groß angelegte IoT-Implementierungen.






