
sdecoret - stock.adobe.com
Die Digitalisierung erfordert eine intakte Datenintegration
Datenintegration als eine Herausforderung für die Digitalisierung erfordert eine Infrastruktur, die die Verwertung von Information aus verschiedenen Quellen gewährleistet.
Die Herausforderungen der Digitalisierung verursachen zum Teil erheblichen Innovationsdruck bei den IT-Verantwortlichen der Unternehmen. Doch Innovationsketten bedingen bereits seit dem Beginn elektronischer Datenverarbeitung den kontinuierlichen Veränderungsprozess der Hard- und Softwaretechnologie. Dieser trägt nachhaltig dazu bei, sämtliche Bereiche klassischer Arbeitswelten digital zu unterstützen, die Arbeitsprozesse zu verschlanken und Wertschöpfungsketten zu reorganisieren.
Dadurch, dass durch die technologische Entwicklung weitgehend Medienbrüche reduziert, Prozesslücken geschlossen und Abläufe automatisiert werden können, ist es heute möglich, Prozessdurchläufe erheblich zu beschleunigen sowie Prozesskosten zu reduzieren. Unternehmenskritische Entscheidungen können somit just in time gefällt werden.
Doch gerade dieses Ziel scheint aufgrund des unterschiedlichen Verteilungs- und Reifegrads der Unternehmensapplikationen besonders schwierig zu sein. Ab einer bestimmten Unternehmensgröße wird die Anzahl der eingesetzten Applikationen (Quellsysteme) und somit der darin enthaltenen Informationen rasch unübersichtlich. Dringend benötigte Daten stehen nicht überall dort zur Verfügung, wo sie eigentlich benötigt werden.
Natürlich hat jedes Quellsystem im Unternehmen eine dedizierte Aufgabe und einen speziellen Fokus. Die Daten des Quellsystems werden auf eine spezifische Art organisiert und gespeichert und verfügen somit über ihre eigene Sprache. Die Information aus solchen Datensilos zu befreien und für die digitale Nutzung verfügbar zu machen, bezeichnet man als Datenintegration. Die Bereitstellung der Information, losgelöst vom Quellsystem sowie den Zugriff über Cloud-Dienste als Datenvirtualisierung.
Daten – Information – Wissen
Um Daten nutzbar zu machen, müssen diese aus dem spezifischen Format des Quellsystems herausgelöst und in ein Format gebracht werden, welches für die Nutzung außerhalb des Quellsystems geeignet ist. Da Quellsysteme oft eine domänenspezifische Art der Datenorganisation aufweisen, müssen die Daten an dieser Schnittstelle in ein nach außen hin verständliches Format transformiert werden.
Diese Transformation kann von einer einfachen Konvertierung (zum Beispiel TIFF nach JPEG für grafische Daten) über spezielle Mapping-Mechanismen (zum Beispiel RAL 1234 nach Rot) bis hin zu aufwändigen Zerlegungsmechanismen bei zusammengesetzten Daten wie sprechenden Nummernsystemen (zum Beispiel Zerlegung von 12-011-1234 in Produktgruppe 12-Dieselmotor, 345-Baureihe 1000 und 1234-8-Zylinder) reichen. Werden die Daten auf diese Art nutzbar, sprechen wir von Informationen, das heißt werden Daten interpretierbar, entstehen Informationen.
Dies ist die Grundlage für den nächsten Schritt: das Verknüpfen von Informationen aus unterschiedlichen Quellen. Denn nur eine intelligente Verknüpfung bringt den eigentlichen Mehrwert. Da, wo die Grenzen der Quellsysteme erreicht sind, bringt die Verknüpfung zusätzliches Wissen in die Information. Beispielsweise Wissen über Zusammenhänge, Kombinierbarkeiten und Kompatibilität, das ansonsten im Unternehmen oft nur aus dem Wissen von Spezialisten, erfahrenen Mitarbeitern oder sogar nur aus Kompetenzteams abgeleitet werden kann. Ein Datenintegrationsprojekt sorgt stets für eine fachbereichs- oder sogar organisationsübergreifende Transparenz der unternehmensspezifischen Datenlandschaft.
Dabei entstehen aus Daten Informationen und aus den Informationen schließlich Wissen. Darin liegt die tiefere Bedeutung einer erfolgreichen Datenintegration: Sie macht Daten durch Anreicherung und sinnvolle Verknüpfungen für den jeweiligen Anwender wertvoller. Die zusammengeführten Informationen können die Grundlage für innovative Geschäftsmodelle bilden, das heißt, die sinnvoll integrierten Daten zu neuen digitalen Services führen. Also genau zu dem, was sich viele Unternehmen ursprünglich von der digitalen Transformation erhoffen.
Virtualisierung
Alles oben Beschriebene können wir im laufenden Betrieb aus den Quellsystem heraus erzeugen. Damit sind wir immer hochaktuell – jedoch ebenso vom Laufzeitverhalten der Quellsysteme abhängig. Darüber hinaus beeinflusst die Datenintegration die Quellsysteme direkt, da bei jeder Abfrage teilweise aufwendige Auswertungen im Quellsystem stattfinden müssen, die gegebenenfalls dort noch nicht mal vorgedacht sind beziehungsweise sogar der typischen Arbeitsweise des Quellsystems widersprechen.
Außerdem stellt sich generell die Frage, welchen Datenstand eines operativen Quellsystems man sinnvoll nutzen kann. Ein Zugriff zu einem beliebigen Zeitpunkt liefert unter Umständen irgendein momentanes Ergebnis unklarer Qualität. Eine Kopplung an bestimmte Status der Information ist also definitiv notwendig. Ist ein definierter Status im Quellsystem erreicht, macht eine Bereitstellung für die Nutzung Sinn. In anderen Fällen nicht.
Diese Situation zieht sich über verschiedene Quellsysteme hinweg. Ein bestimmter Stand aus Quellsystem A macht nur Sinn mit einem dazu passenden Stand aus Quellsystem B (siehe Abbildung 1). Jede andere Kombination erzeugt inkonsistente Daten. Wichtig ist hierbei, dass wir davon ausgehen müssen, dass manche der Quellsysteme eine Versionierung unter diesen Gesichtspunkten gar nicht kennen. Es handelt sich um operative Systeme, für die eine Gültigkeit zum Zeitpunkt X absolut ausreichend ist und eine Reproduzierbarkeit gar nicht erforderlich ist, geschweige denn eine rechtssichere Revisionierung.
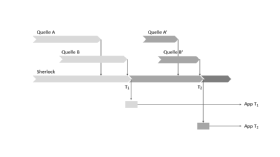
Für unseren Anwendungsfall ist es jedoch entscheidend, dass ein bestimmter Stand an Daten aus System A mit einem bestimmten Stand an Daten aus System B zusammenpasst – oder eben nicht. Um diese Stände jeweils reproduzieren zu können, ist eine vom Quellsystem entkoppelte Speicherung dieser Daten erforderlich. Der Datenstand, den ein Quellsystem A als konsistent und freigegeben deklariert – dieser Datenstand muss mit einem ebenso definierten Datenstand aus System B zusammenspielen. Auch wenn die Daten in den Quellsystemen weiterentwickelt, weitergepflegt und gespeichert werden. Nur eine definierte Beziehung von Daten aus A und B ist konsistent und funktioniert zusammen.
Eine Aufgabe der Informationsbereitstellung ist es, diesen Stand reproduzierbar zu machen. Dies bedeutet, den Stand unabhängig von den betroffen Quellsystemen bereitstellen zu können. In einer von den Quellsystemen unabhängigen Umgebung diese Informationen also zu kennen, in Beziehung zu setzen und bereitzustellen. Dies bezeichnen wir als Datenvirtualisierung.
Eine Datenintegration ohne Datenvirtualisierung wird nur in sehr eingeschränkten Situationen ein brauchbares Ergebnis liefern. Die Datenvirtualisierung ist für die Nutzung der Daten unerlässlich. Erst auf Basis eines virtualisierten Informationsmodells sind neue, informationsbasierte Services überhaupt realisierbar.
Zur Datenintegration und Virtualisierung setzen wir auf unsere selbstentwickelte Cloud-basierte Informationsplattform Sherlock, die sämtliche hierfür notwendigen Werkzeuge mitbringt. Tools mit ähnlichem Ansatz sind am Markt verfügbar, sollten aber die dargestellten Features vollständig abbilden.
Mehrstufige Entkopplung über Time & Logic
Durch die oben beschriebenen Methoden der Integration und Virtualisierung findet eine Entkopplung auf mehreren Ebenen statt. Einerseits handelt es sich um eine Entkopplung auf logischer Ebene. Zunächst wird in den Quellsystemen definiert, welche Daten zur Nutzung bereitgestellt werden. Nur diese werden in der Informationsbereitstellung betrachtet. Rein interne oder ausschließlich transaktionsorientierte Daten spielen hier typischerweise keine Rolle (erste Stufe der Entkopplung).
Die Datenlogik des Quellsystems folgt den individuellen Bedürfnissen aus dessen Nutzungskontext. Die Daten werden aus diesem Kontext herausgelöst und in eine neutrale, logische Ebene überführt. Durch diese zweite Entkopplungsstufe (2a) werden aus den Daten weiterhin nutzbare Informationen. Ebenso im zweiten Schritt der logischen Entkopplung (2b) werden Sichten definiert, die jeweils anwendungsfallspezifische Zusammenstellungen der Informationen bereitstellen.
Auf diese Sichten wird dann über eine WebAPI-Schnittstelle zugegriffen. Jede Sicht liefert genau die Informationen, die für einen spezifischen Anwendungsfall relevant sind - nicht mehr und nicht weniger. Der dritte Schritt der logischen Entkopplung findet durch die Anwendung statt, die die Information über die WebAPI-Schnittstelle abruft. Sie sorgt für die anwendergerechte Auswertung, Aufbereitung und Darstellung der gewünschten Informationen.
Neben der logischen Entkopplung ist aber auch die zeitliche Entkopplung unter mehreren Gesichtspunkten relevant. In den Quellsystemen erfolgt eine stetige Bearbeitung der dort vorhandenen Daten. Nur definierte, freigegebene Stände sind typischerweise für die weitere Nutzung relevant. Der Zeitpunkt der Übertragung ist also an einen definierten Status der Daten im Quellsystem gebunden.
Dies ist die erste Stufe der zeitlichen Entkopplung. Die Integration in die Informationsplattform findet sofort nach der Übertragung statt. Die Übernahme der Daten in die Sichten (in Sherlock bezeichnen wir sie als Collections) kann entweder ebenfalls sofort erfolgen, über eine zeitliche Steuerung (zum Beispiel alle 24 Stunden) oder ebenfalls an einen Status gekoppelt sein.
Die Bereitstellung in der Sicht ist demnach die zweite zeitliche Entkopplung. Hier kann darüber hinaus auch ein Staging-Verfahren stattfinden, das nur getestete Informationsstände an der Schnittstelle überhaupt sichtbar werden lässt. Und in der dritten Stufe entscheidet die Anwendung selbst, ob sie live auf die Informationsplattform zugreift oder sich die aktualisierten Informationen auch zu definierten Zeitpunkten oder bei Erreichen eines bestimmten Status abholt.

„Datenintegration als eine zentrale Herausforderung für die Digitalisierung erfordert in den Unternehmen eine Infrastruktur, die die Nutzbarkeit von Information aus unterschiedlichen Quellen sicherstellt.“
Rainer Boersig, Fischer Information Technology AG
Drei Stufen der Entkopplung, jeweils auf logischer und auf zeitlicher Ebene – diese Schritte sind erforderlich, um die digitale Nutzbarkeit von Informationen, die aus unterschiedlichen Quellsystemen bereitgestellt werden, sicherstellen zu können. Weniger Schritte sind nur in dedizierten Einzelfällen ausreichend. Wir sprechen hier von Single Point Applications, die allerdings nicht als allgemeiner Ansatz für die Digitalisierung herangezogen werden können.
Mehr als drei Schritte führen zu erhöhter Komplexität und bringen nicht den entsprechenden zusätzlichen praktischen Nutzen. Mit drei klaren Schritten wird generell die notwendige Flexibilität erreicht, die für die digitale Nutzung der gewünschten Informationen notwendig ist.
Fazit
Datenintegration als eine zentrale Herausforderung für die Digitalisierung erfordert in den Unternehmen eine Infrastruktur, die die Nutzbarkeit von Information aus unterschiedlichen Quellen sicherstellt. Das hier vorgestellte Konzept ermöglicht die notwendige Flexibilität, erlaubt die Versorgung einer Vielzahl von Anwendungen mit relevanten Daten und kann dabei mit den Anforderungen der Unternehmen wachsen. Anwendungen, Portale und Apps können auf dieser Basis schnell implementiert werden.
Über den Autor:
Rainer Börsig ist Chief Technical Officer (CTO) bei der Fischer Information Technology AG. Der Diplom-Informatiker (FH) ist seit 25 Jahren bei der Fischer Information Technology AG tätig. Als Technischer Leiter ist er für die Produkte verantwortlich und berät Kunden bei der Implementierung innovativer, digitaler Geschäftsmodelle.
Die Autoren sind für den Inhalt und die Richtigkeit ihrer Beiträge selbst verantwortlich. Die dargelegten Meinungen geben die Ansichten der Autoren wieder.






