Apache Hadoop YARN (Yet Another Resource Negotiator)
Apache Hadoop YARN es la tecnología de gestión de recursos y programación de trabajos en el marco de procesamiento distribuido de código abierto Hadoop. YARN, uno de los componentes centrales de Apache Hadoop, es responsable de asignar recursos del sistema a las diversas aplicaciones que se ejecutan en un clúster de Hadoop y programar tareas para que se ejecuten en diferentes nodos del clúster.
El término YARN proviene de las siglas de Yet Another Resource Negotiator, pero comúnmente se lo denomina solo por el acrónimo; el nombre completo era humor autocrítico por parte de sus desarrolladores. La tecnología se convirtió en un subproyecto de Apache Hadoop dentro de Apache Software Foundation (ASF) en 2012 y fue una de las características clave agregadas en Hadoop 2.0, que se lanzó para pruebas ese año y estuvo disponible de forma generalizada en octubre de 2013.
La adición de YARN expandió significativamente los usos potenciales de Hadoop. La encarnación original de Hadoop emparejó estrechamente el Sistema de archivos distribuido de Hadoop (HDFS) con el marco de programación y el motor de procesamiento MapReduce orientado por lotes, que también funcionó como administrador de recursos y programador de trabajos de la plataforma de big data. Como resultado, los sistemas Hadoop 1.0 solo podían ejecutar aplicaciones MapReduce —una limitación que Hadoop YARN eliminó.
Antes de obtener su nombre oficial, YARN se llamaba informalmente MapReduce 2 o NextGen MapReduce. Pero introdujo un nuevo enfoque que desacoplaba la gestión de recursos del clúster y la programación del componente de procesamiento de datos de MapReduce, lo que le permitió a Hadoop admitir diversos tipos de procesamiento y una gama más amplia de aplicaciones. Por ejemplo, los clústeres de Hadoop ahora pueden ejecutar consultas interactivas, transmisión de datos y aplicaciones de análisis en tiempo real en Apache Spark y otros motores de procesamiento simultáneamente con trabajos por lotes de MapReduce.
Características y funciones de Hadoop YARN
En una arquitectura de clúster, Apache Hadoop YARN se encuentra entre HDFS y los motores de procesamiento que se utilizan para ejecutar aplicaciones. Combina un administrador de recursos central con contenedores, coordinadores de aplicaciones y agentes a nivel de nodo que monitorean las operaciones de procesamiento en los nodos individuales del clúster. YARN puede asignar recursos dinámicamente a las aplicaciones según sea necesario, una capacidad diseñada para mejorar la utilización de recursos y el rendimiento de las aplicaciones en comparación con el enfoque de asignación más estático de MapReduce.
Además, YARN admite múltiples métodos de programación, todos basados en un formato de cola para enviar trabajos de procesamiento. El Programador FIFO predeterminado ejecuta las aplicaciones en base al primero en entrar, primero en salir, como se refleja en su nombre. Sin embargo, es posible que eso no sea óptimo para los clústeres que comparten varios usuarios. En cambio, la herramienta conectable Fair Scheduler de Apache Hadoop asigna a cada trabajo que se ejecuta al mismo tiempo su "parte justa" de los recursos del clúster, según una métrica de ponderación que calcula el programador.
Otra herramienta conectable, llamada Capacity Scheduler, permite que los clústeres de Hadoop se ejecuten como sistemas de múltiples inquilinos compartidos por diferentes unidades en una organización o por múltiples compañías, y cada uno obtiene una capacidad de procesamiento garantizada basada en acuerdos individuales de nivel de servicio. Utiliza colas y subcolas jerárquicas para garantizar que se asignen suficientes recursos de clúster a las aplicaciones de cada usuario antes de permitir que los trabajos de otras colas aprovechen los recursos no utilizados.
Hadoop YARN también incluye una función de sistema de reserva que permite a los usuarios reservar recursos del clúster por adelantado para trabajos de procesamiento importantes a fin de garantizar que se ejecuten sin problemas. Para evitar sobrecargar un clúster con reservas, los administradores de TI pueden limitar la cantidad de recursos que pueden reservar los usuarios individuales y establecer políticas automatizadas para rechazar las solicitudes de reserva que superen los límites.
La federación de YARN es otra característica notable que se agregó en Hadoop 3.0, que estuvo disponible en general en diciembre de 2017. La capacidad de federación está diseñada para aumentar la cantidad de nodos que una sola implementación de YARN puede admitir, de 10,000 a varias decenas de miles o más, mediante el uso de una capa de enrutamiento para conectar varios "subclusters", cada uno equipado con su propio administrador de recursos. El entorno funcionará como un clúster grande que puede ejecutar trabajos de procesamiento en cualquier nodo disponible.
Componentes clave de Hadoop YARN
En MapReduce, un proceso maestro de JobTracker supervisó la administración de recursos, la programación y el monitoreo de los trabajos de procesamiento. Creó procesos subordinados llamados TaskTrackers para ejecutar mapas individuales y reducir tareas e informar sobre su progreso, pero la mayor parte del trabajo de asignación y coordinación de recursos se centralizó en JobTracker. Eso creó cuellos de botella en el rendimiento y problemas de escalabilidad a medida que aumentaba el tamaño de los clústeres y la cantidad de aplicaciones —y los TaskTrackers asociados.
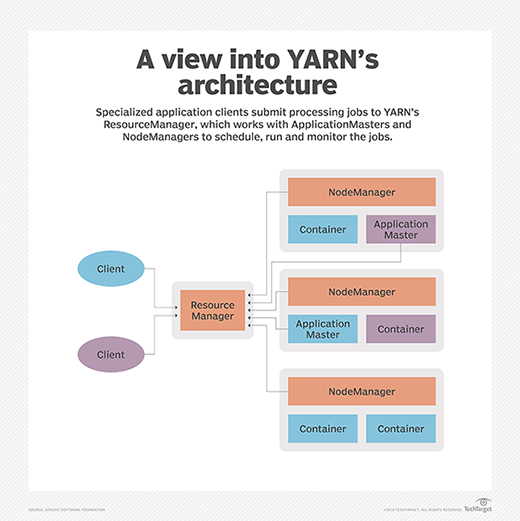
Apache Hadoop YARN descentraliza la ejecución y el monitoreo de los trabajos de procesamiento al separar las diversas responsabilidades en estos componentes:
- Un ResourceManager global que acepta envíos de trabajos de los usuarios, programa los trabajos y les asigna recursos.
- Un esclavo NodeManager que se instala en cada nodo y funciona como un agente de supervisión y presentación de informes del ResourceManager
- Un ApplicationMaster que se crea para cada aplicación para negociar recursos y trabajar con NodeManager para ejecutar y monitorear tareas.
- Contenedores de recursos controlados por NodeManagers y asignados a los recursos del sistema asignados a aplicaciones individuales.

Los contenedores YARN generalmente se configuran en nodos y se programan para ejecutar trabajos solo si hay recursos del sistema disponibles para ellos, pero Hadoop 3.0 agregó soporte para crear "contenedores oportunistas" que se pueden poner en cola en NodeManagers para esperar a que los recursos estén disponibles. El concepto de contenedor oportunista tiene como objetivo optimizar el uso de los recursos del clúster y, en última instancia, aumentar el rendimiento general del procesamiento en los sistemas Hadoop.
Además, aunque el enfoque estándar ha sido ejecutar contenedores YARN directamente en los nodos del clúster, Hadoop 3.1 incluirá la capacidad de colocarlos dentro de contenedores Docker. Eso aislaría las aplicaciones entre sí y el entorno de ejecución de NodeManager; además, se pueden ejecutar múltiples versiones de aplicaciones simultáneamente en diferentes contenedores Docker.
Ventajas de YARN
El uso de Apache Hadoop YARN para separar HDFS de MapReduce hizo que el entorno de Hadoop fuera más adecuado para usos de procesamiento en tiempo real y otras aplicaciones que no pueden esperar a que finalicen los trabajos por lotes. Ahora, MapReduce es solo uno de los muchos motores de procesamiento que pueden ejecutar aplicaciones Hadoop. Ya ni siquiera tiene un bloqueo en el procesamiento por lotes en Hadoop: en muchos casos, los usuarios lo reemplazan con Spark para obtener un rendimiento más rápido en aplicaciones por lotes, como extraer, transformar y cargar trabajos.
Spark también puede ejecutar aplicaciones de procesamiento de flujo en clústeres de Hadoop gracias a YARN, al igual que tecnologías que incluyen Apache Flink y Apache Storm. YARN también ha abierto nuevos usos para Apache HBase, una base de datos complementaria de HDFS, y para Apache Hive, Apache Drill, Apache Impala, Presto y otros motores de consulta SQL-on-Hadoop. Además de más opciones de aplicaciones y tecnología, YARN ofrece escalabilidad, utilización de recursos, alta disponibilidad y mejoras de rendimiento sobre MapReduce.






