Lago de datos
Un lago de datos es un repositorio de almacenamiento que contiene una gran cantidad de datos sin procesar en su formato nativo hasta que se necesitan. Mientras que un almacén de datos jerárquico almacena datos en archivos o carpetas, un lago de datos utiliza una arquitectura plana para almacenar datos. A cada elemento de datos en un lago se le asigna un identificador único y se le asigna un conjunto de etiquetas de metadatos extendidos. Cuando surge una pregunta comercial, se puede consultar el lago de datos para obtener datos relevantes, y ese conjunto más pequeño de datos se puede analizar para ayudar a responder la pregunta.
El término lago de datos a menudo se asocia con el almacenamiento de objetos orientado a Hadoop. En tal escenario, los datos de una organización se cargan primero en la plataforma Hadoop, y luego se aplican las herramientas de análisis de negocios (BA) y minería de datos a los datos donde residen en los nodos de clúster de computadoras de Hadoop.
Al igual que el big data, el término lago de datos a veces se desacredita por ser simplemente una etiqueta de marketing para un producto que respalda a Hadoop. Sin embargo, el término se utiliza cada vez más para describir cualquier gran conjunto de datos en el que el esquema y los requisitos de datos no se definen hasta que se consultan los datos.
El término describe una estrategia de almacenamiento de datos, no una tecnología específica, aunque con frecuencia se usa junto con una tecnología específica (Hadoop). Lo mismo puede decirse del término almacén de datos, que a pesar de que a menudo se refiere a una tecnología específica (base de datos relacional), en realidad describe una estrategia amplia de gestión de datos.
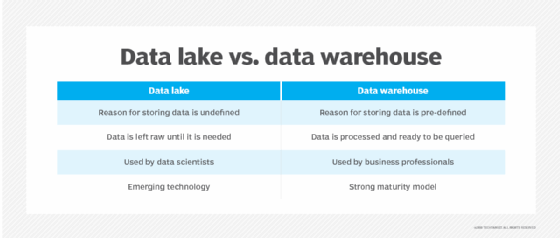
Lago de datos vs. almacén de datos
Los lagos de datos y los almacenes de datos son dos estrategias diferentes para almacenar macrodatos. La distinción más importante entre ellos es que en un almacén de datos, el esquema de los datos está preestablecido; es decir, hay un plan para los datos al ingresar a la base de datos. En un lago de datos, este no es necesariamente el caso. Un lago de datos puede albergar datos estructurados y no estructurados y no tiene un esquema predeterminado. Un almacén de datos maneja principalmente datos estructurados y tiene un esquema predeterminado para los datos que alberga.
Para decirlo de manera más simple, piense en el concepto de almacén frente al concepto de lago. Un lago es líquido, cambiante, amorfo, en gran parte desestructurado y se alimenta de ríos, arroyos y otras fuentes de agua sin filtrar. Un almacén, por otro lado, es una estructura hecha por el hombre, con estantes y pasillos y lugares designados para las cosas dentro de él. Los almacenes almacenan productos seleccionados de fuentes específicas. Los almacenes están preestructurados, los lagos no.
Esta diferencia conceptual central se manifiesta de varias maneras, que incluyen:
Tecnología normalmente utilizada para alojar datos — un almacén de datos suele ser una base de datos relacional alojada en un servidor mainframe empresarial o en la nube, mientras que un lago de datos suele estar alojado en un entorno Hadoop o un repositorio de big data similar.
Fuente de los datos — los datos almacenados en un almacén se extraen de varias aplicaciones de procesamiento de transacciones en línea (OLTP) para respaldar las consultas de análisis comerciales y los mercados de datos para grupos comerciales internos específicos, como equipos de ventas o de inventario. Los lagos de datos suelen recibir datos tanto relacionales como no relacionales de dispositivos de internet de las cosas (IoT), redes sociales, aplicaciones móviles y aplicaciones corporativas.
Usuarios — los almacenes de datos son útiles cuando hay una gran cantidad de datos de los sistemas operativos que deben estar disponibles para su análisis. Los lagos de datos son más útiles cuando una organización necesita un gran repositorio de datos, pero no tiene un propósito para todos y puede permitirse aplicar un esquema al acceder.
Debido a que los datos en un lago a menudo no están curados y pueden provenir de fuentes fuera de los sistemas operativos de la empresa, los lagos no son una buena opción para el usuario promedio de análisis de negocios. En cambio, los lagos de datos son más adecuados para que los usen los científicos de datos, porque se necesita un nivel de habilidad para poder clasificar la gran cantidad de datos sin procesar y extraer fácilmente el significado de ellos.
Calidad de los datos — en un almacén de datos, los datos altamente curados generalmente son confiables como la versión central de true porque contienen datos ya procesados. Los datos en un lago de datos son menos confiables porque podrían llegar de cualquier fuente en cualquier estado. Puede estar curada y puede que no, según la fuente.
Procesamiento — el esquema para los almacenes de datos está en escritura, lo que significa que está preestablecido para cuando los datos se ingresan en el almacén. El esquema de un lago de datos está en lectura, lo que significa que no existe hasta que se ha accedido a los datos y alguien elige usarlos para algo.
Rendimiento/costo — los almacenes de datos suelen ser más costosos para grandes volúmenes de datos, pero la compensación es resultados de consulta más rápidos, confiabilidad y mayor rendimiento. Los lagos de datos están diseñados pensando en el bajo costo, pero los resultados de las consultas mejoran a medida que maduran el concepto y las tecnologías circundantes.
Agilidad — los lagos de datos son muy ágiles; se pueden configurar y reconfigurar según sea necesario. Los almacenes de datos no son tan ágiles.
Seguridad — los almacenes de datos son generalmente más seguros que los lagos de datos porque los almacenes como concepto han existido durante más tiempo y, por lo tanto, los métodos de seguridad han tenido la oportunidad de madurar.
Debido a sus diferencias y al hecho de que los lagos de datos son un concepto más nuevo y aún en evolución, las organizaciones pueden optar por utilizar tanto un almacén de datos como un lago de datos en una implementación híbrida. Esto puede ser para acomodar la adición de nuevas fuentes de datos o para crear un repositorio de archivos para lidiar con la transferencia de datos del almacén de datos principal. Con frecuencia, los lagos de datos son una adición o una evolución de la estructura de gestión de datos actual de una organización en lugar de un reemplazo.
Arquitectura del lago de datos
La arquitectura física de un lago de datos puede variar, ya que el lago de datos es una estrategia que se puede aplicar a múltiples tecnologías. Por ejemplo, la arquitectura física de un lago de datos que usa Hadoop puede diferir de la de un lago de datos que usa Amazon Simple Storage Service (Amazon S3).
Sin embargo, hay tres grandes principios que distinguen un lago de datos de otros métodos de almacenamiento de big data y constituyen la arquitectura básica de un lago de datos. Ellos son:
- No se rechaza ningún dato. Todos los datos se cargan desde varios sistemas de origen y se conservan.
- Los datos se almacenan en un estado sin transformar o casi sin transformar, tal como se recibieron de la fuente.
- Los datos se transforman y se ajustan a un esquema basado en los requisitos de análisis.
Aunque los datos no están estructurados en gran medida y no están orientados a responder ninguna pregunta específica, aún deben estar organizados de alguna manera para que sea posible hacerlo en el futuro. Independientemente de la tecnología que se utilice para implementar el lago de datos de una organización, se deben incluir algunas características para garantizar que el lago de datos sea funcional y saludable y que el gran repositorio de datos no estructurados no se desperdicie. Éstas incluyen:
- Una taxonomía de clasificaciones de datos, que puede incluir tipo de datos, contenido, escenarios de uso y grupos de posibles usuarios.
- Una jerarquía de archivos con convenciones de nomenclatura.
- Herramientas de creación de perfiles de datos para proporcionar información para clasificar objetos de datos y abordar problemas de calidad de datos.
- Proceso de acceso a datos estandarizado para realizar un seguimiento de los miembros de una organización que acceden a los datos.
- Un catálogo de datos con capacidad de búsqueda.
- Protecciones de datos que incluyen enmascaramiento de datos, cifrado de datos y monitoreo automatizado para generar alertas cuando personas no autorizadas acceden a los datos.
- Conocimiento de los datos entre los empleados, que incluye una comprensión de la gestión y el manejo de datos adecuados, capacitación sobre cómo navegar por el lago de datos y una comprensión de la calidad sólida de los datos y el uso adecuado de los datos.
Beneficios de un lago de datos
El lago de datos ofrece varios beneficios, que incluyen:
- La capacidad de los desarrolladores y científicos de datos para configurar fácilmente un modelo de datos, una aplicación o una consulta sobre la marcha. El lago de datos es muy ágil.
- Los lagos de datos son, en teoría, más accesibles. Debido a que no existe una estructura inherente, cualquier usuario puede acceder técnicamente a los datos en el lago de datos, aunque la prevalencia de grandes cantidades de datos no estructurados podría inhibir a los usuarios menos capacitados.
- El lago de datos da soporte a usuarios de distintos niveles de inversión; los usuarios que desean volver a la fuente para recuperar más información, los que buscan responder preguntas completamente nuevas con los datos y los que simplemente requieren un informe diario. El acceso es posible para cada uno de estos tipos de usuarios.
- Los lagos de datos son baratos de implementar porque la mayoría de las tecnologías que se utilizan para administrarlos son de código abierto (es decir, Hadoop) y se pueden instalar en hardware de bajo costo.
- El desarrollo de esquemas y la limpieza de datos que requieren mucha mano de obra se aplazan hasta que una organización haya identificado una necesidad comercial clara de los datos.
- La agilidad permite una variedad de diferentes métodos de análisis para interpretar datos, incluidos análisis de big data, análisis en tiempo real, aprendizaje automático y consultas SQL.
- Escalabilidad por falta de estructura.
Críticas en contra
A pesar de los beneficios de tener un depósito de datos barato y no estructurado a disposición de una organización, se han formulado varias críticas legítimas contra la estrategia.
Una de las mayores locuras potenciales del lago de datos es que podría convertirse en un pantano de datos o un cementerio de datos. Si una organización practica una gestión y gobernanza de datos deficiente, puede perder el rastro de los datos que existen en el lago, incluso cuando se agregan más. El resultado es un cuerpo desperdiciado de datos potencialmente valiosos que se pudren sin ser vistos en el "fondo" del lago de datos, por así decirlo, haciéndolo deteriorado, incontrolado e inaccesible.
Los lagos de datos, si bien brindan accesibilidad teórica a cualquier persona en una organización, pueden no ser tan accesibles en el uso práctico, porque los analistas de negocios pueden tener dificultades para analizar fácilmente datos no estructurados de una variedad de fuentes. Este desafío práctico de accesibilidad también puede contribuir a la falta de un mantenimiento de datos adecuado y resultar en el desarrollo de un cementerio de datos. Es importante maximizar la inversión en un lago de datos y reducir el riesgo de implementación fallida.
Otro problema con el término lago de datos en sí es que se usa en muchos contextos en el discurso público. Aunque tiene más sentido usarlo para describir una estrategia de administración de datos, también se ha usado comúnmente para describir tecnologías específicas y, como resultado, tiene un nivel de arbitrariedad. Este desafío puede dejar de serlo una vez que el término madure y encuentre un significado más concreto en el discurso público.
Vendedores
Aunque un lago de datos no es una tecnología específica, existen varias tecnologías que los habilitan. Algunos proveedores que ofrecen esas tecnologías son:
- Apache — ofrece el ecosistema de código abierto Hadoop, uno de los servicios de lago de datos más comunes.
- Amazon — ofrece Amazon S3 con una escalabilidad prácticamente ilimitada.
- Google — ofrece Google Cloud Storage y una colección de servicios para sincronizarlo con la administración.
- Oracle — ofrece Oracle Big Data Cloud y una variedad de servicios PaaS para ayudar a administrarlo.
- Microsoft — ofrece Azure Data Lake como un almacenamiento de datos escalable y Azure Data Lake Analytics como un servicio de análisis paralelo. Este es un ejemplo de cuando el término lago de datos se usa para referirse a una tecnología específica en lugar de una estrategia.
- HVR — ofrece una solución escalable para organizaciones que necesitan mover grandes volúmenes de datos y actualizarlos en tiempo real.
- Podium — ofrece una solución con un conjunto de funciones de gestión fáciles de implementar y utilizar.
- Snowflake — ofrece una solución que se especializa en el procesamiento de diversos conjuntos de datos, incluidos conjuntos de datos estructurados y semiestructurados como JSON, XML y Parquet.
- Zaloni — ofrece una solución que viene con Mica, una herramienta de preparación de datos de autoservicio y un catálogo de datos. Zaloni ha sido calificado como la empresa del lago de datos.






