
pressmaster - Fotolia
Compare computación perimetral frente a computación de nube
Los administradores de TI no tienen que elegir entre el borde y la nube, pero deben conocer los pros y los contras de cada tecnología para incorporarlos de la mejor manera posible a las operaciones empresariales.

Tanto la nube pública como la computación perimetral son tecnologías que complementan el centro de datos tradicional y ayudan a optimizar la utilización y gestión de los recursos, pero no son ideales para todas las organizaciones o escenarios. El caso de uso es un factor importante a la hora de decidir qué modelo de despliegue tiene más sentido para determinadas cargas de trabajo, pero antes de que los administradores de TI puedan decidir si utilizar la nube o el borde –o, más probablemente, una mezcla de ambos–, necesitan entender los pros y los contras de cada uno.
Conceptos básicos de la computación en nube
A estas alturas, la mayoría de la gente está familiarizada con la computación de nube: Se crea una plataforma en la que los recursos –computación, almacenamiento y red– pueden aplicarse de forma flexible a una carga de trabajo de manera altamente virtualizada para satisfacer mejor las necesidades de las cargas de trabajo dinámicas modernas.
Ventajas de la computación en nube
La nube tiene muchas ventajas, entre ellas:
- Aprovisionamiento de recursos flexible y altamente dinámico. Con la configuración adecuada, la nube puede flexibilizar los recursos aplicados a una carga de trabajo bajo demanda. Por ejemplo, una carga de trabajo que tiene un pico repentino en su necesidad de potencia de cálculo puede hacer que ésta se aplique a partir de montones de recursos virtuales. Cuando el pico de demanda finaliza, el recurso puede liberarse y volver a colocarse en el montón, listo para las necesidades de la siguiente carga de trabajo.
- Altamente virtualizado. De nuevo, en una nube bien diseñada, la virtualización de la plataforma significa que las cargas de trabajo obtienen altos niveles de portabilidad. Una instancia de una aplicación puede trasladarse de una parte de la nube a otra, si es necesario, y esto puede hacerse rápidamente. Esto mejora la disponibilidad y el rendimiento.
Desventajas de la computación en nube
La nube también tiene sus desventajas, tales como:
- Sigue habiendo un límite de recursos. Esto es cierto, sobre todo en las nubes privadas. Ninguna organización quiere gestionar una plataforma en la que esté pagando por una capacidad de recursos demasiado grande. Los costos asociados a una mala utilización de los recursos incluyen no solo las necesidades de energía para mantener todo en funcionamiento, sino el tamaño total de un centro de datos, la refrigeración necesaria, las licencias de los sistemas operativos y las aplicaciones, el mantenimiento, etc. Lo más probable es que las nubes públicas ya gestionen cientos de miles de cargas de trabajo, por lo que pueden manejar mejor este aspecto; las nubes privadas que solo gestionan decenas o cientos de cargas de trabajo podrían no tener el margen de recursos necesario.
- Dificultades para tratar los aspectos más físicos de un entorno. Aunque la virtualización de los recursos es una poderosa ventaja para la nube, no puede hacerse cuando se depende de la posición física o de las capacidades de un solo activo.
- Las nubes públicas no suelen estar conectadas a las necesidades más físicas de una organización a través de enlaces de gran ancho de banda. Utilizar una plataforma de nube centralizada en un entorno es generalmente una buena idea. Sin embargo, si esa nube depende de una conexión lenta y de menor ancho de banda para acceder a los datos de un entorno, podrían producirse problemas importantes como el aserrado de datos y las colisiones de paquetes cuando las cargas de datos son elevadas.

La nube en un entorno de TI moderno
Objetivamente, la nube es una gran idea, pero se enfrenta a algunos problemas cuando se observan los cambios en el entorno de TI en los últimos dos años. El principal es el floreciente ámbito de IoT. Aquí, los dispositivos están repartidos por el entorno físico de TI de una organización, llevando a cabo una serie de tareas diferentes, desde simples mediciones hasta acciones complejas en función de los requisitos de, por ejemplo, una línea de producción o un edificio inteligente. Los dispositivos IoT son ricos en datos, ya que tienden a crear una gran cantidad de datos. Estos datos tienden a ser parlanchines: no son un flujo continuo, sino que se crean a lo largo de una serie de eventos. Gran parte de los datos son inútiles; los dispositivos IoT tienden a crear datos que a menudo se limitan a indicar que todo está bien. Estos datos no necesitan atravesar la red, pero muchos dispositivos IoT no tienen la inteligencia incorporada para saberlo.
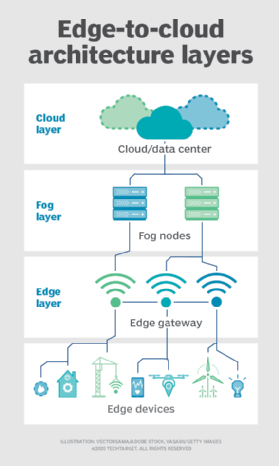
Aquí radica la dicotomía: intentar gestionar completamente un entorno de IoT a través de una plataforma de nube completa no es la forma óptima de hacer las cosas. El problema es que, para que una nube se ocupe de todos los datos creados por estos dispositivos IoT, todos esos datos deben atravesar la red hasta donde reside esa capacidad de la nube. Esto conlleva una latencia en los propios datos, junto con lo que puede ser un gran golpe en el ancho de banda general de la nube, incluso con la flexibilidad de recursos que la nube pone en juego. Por suerte, existe otra opción: la computación perimetral.
Conceptos básicos de computación perimetral
La idea que subyace a la computación de borde es trasladar toda o parte de la manipulación y el análisis de los datos fuera del centro de una plataforma de TI hacia el lugar donde se crean los datos, minimizando el movimiento de datos, mejorando el rendimiento y situando la inteligencia necesaria más cerca de los propios dispositivos del IoT. Así, una unidad de computación especial, conocida como dispositivo de borde, puede colocarse dentro del entorno para capturar, manipular, analizar y tomar decisiones sobre qué acciones deben llevarse a cabo en qué áreas. De nuevo, una buena idea en teoría, pero los problemas surgen en la práctica.
Ventajas de la computación perimetral
Las ventajas de la computación de borde incluyen:
- Coloca la inteligencia de datos más cerca de donde se necesita. Esto significa que se mejoran las respuestas, y con muchos dispositivos IoT que son actuadores u otros elementos impulsados por eventos, existe la necesidad de respuestas lo más cercanas posible al tiempo real en algunas situaciones.
- Minimiza las transferencias de datos a través de la red más amplia. Esto significa que hay más ancho de banda de red disponible para necesidades de manipulación y análisis de datos más urgentes.
- Permite que se aplique un enfoque más de «piel de cebolla» a las transferencias de datos. Aquí, el dispositivo de borde puede capturar y analizar los datos procedentes de un grupo de dispositivos IoT y puede filtrar los datos obviamente inútiles. También puede ver si hay algo que apunte a un problema inmediato y enviar esos datos para un análisis más detallado a la nube centralizada o a otro dispositivo de borde más capaz y cercano al núcleo.
Desventajas de la computación perimetral
Sin embargo, la computación de borde también sufre problemas, entre ellos:
- Definición del borde. Las plataformas en la nube ya han enturbiado la definición de dónde se encuentra el borde de una plataforma informática y sus componentes. En el caso de la computación de borde, que se ocupa de muchas más entidades físicas en el mundo de los dispositivos IoT, podría parecer obvio que éstas representan el borde, ya que son nodos finales. Sin embargo, ¿de cuántos dispositivos IoT debe ser responsable un dispositivo de borde? ¿De qué tipos de dispositivos IoT debería ser responsable un único dispositivo de borde?
- Falsos positivos y negativos. Dado que la mayoría de los dispositivos IoT son dispositivos relativamente tontos, con poca capacidad para analizar o gestionar sus propios dispositivos, el dispositivo de borde debe asumir la responsabilidad de esto. Sin embargo, los dispositivos de borde deben ser rentables; un dispositivo de borde que cuide, por ejemplo, de 10 dispositivos IoT, no puede costar miles de dólares. Por lo tanto, los dispositivos de borde podrían sufrir deficiencias en sus capacidades, lo que llevaría a un mal análisis de datos y a la iniciación de eventos. Los usuarios deben tener cuidado con la elección de sus dispositivos de borde.
Elegir entre el borde y la nube
Para la mayoría, no se trata de elegir entre la nube y la computación de borde, sino que ambas son necesarias para gestionar un entorno moderno. La idea es tener los recursos donde más se necesitan. Para las cargas de trabajo optimizadas para la nube, esto puede ser generalmente en cualquier lugar dentro de la propia nube virtual.
Para la IoT, donde la ubicación física de ese dispositivo es una preocupación importante, y existe la necesidad de que la captura de recursos, el filtrado y el análisis estén lo más cerca posible de los dispositivos físicos, la computación de borde es una mejor opción. Sin embargo, los datos que se alimentan de una red de computación de borde generalmente se alimentarán en el entorno de la nube principal para un análisis más profundo y el procesamiento de eventos.
Computación de niebla (fog computing) y nube de borde
Aquellos que estudian la computación de borde en un mundo de nube también pueden encontrar el término computación de niebla; esto, esencialmente, reúne los dos conceptos como más de un concepto único. Los dispositivos de computación perimetral se colocan lo más cerca posible de la necesidad real, pero con una estrecha integración con la plataforma principal de la nube centralizada.
Otro término que se puede ver es el de nube de borde, que significa cosas diferentes para distintas personas; muchos lo ven como lo mismo que la computación de niebla. Para otros, se trata más bien de una plataforma de infraestructura total completamente integrada y optimizada que se apoya en las construcciones de red subyacentes para gestionar los flujos de datos y el análisis. Sin embargo, la nube de borde y la computación de niebla son conceptos similares.




