O que é e como funciona a web scraping
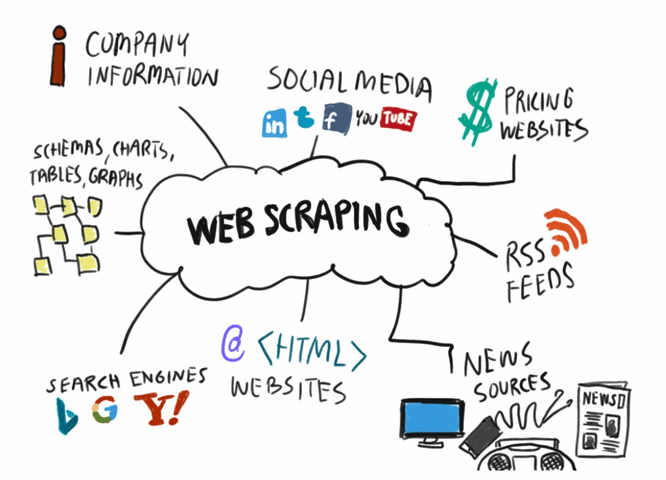
A raspagem de dados da web, também conhecida como web scraping, ou colheita ou extração de dados na web, refere-se basicamente à coleta de dados de sites por meio do Protocolo de Transferência de Hipertexto (HTTP) ou por meio de navegadores da web.
Como funciona a raspagem de dados da web?
Geralmente, a raspagem da web envolve três etapas:
- Primeiro, enviamos uma solicitação GET ao servidor e receberemos uma resposta na forma de conteúdo da web.
- Em seguida, analisamos o código HTML de um site da Web seguindo um caminho de estrutura em árvore.
- Por fim, usamos a biblioteca python para procurar a árvore de análise.
Eu sei o que você pensou –a raspagem da web parece boa em tese, mas na verdade é mais complexa na prática. Precisamos de código para obter os dados que queremos, o que torna a raspagem um privilégio de quem é o mestre da programação. Como alternativa, existem ferramentas de raspagem da web que automatizam a extração de dados da web, deixando esta tarefa na ponta dos dedos do usuário.
Uma ferramenta de raspagem da web carregará os URLs fornecidos pelos usuários e renderizará todo o site. Como resultado, você pode extrair quaisquer dados da web com um simples apontar e clicar e arquivar em um formato viável em seu computador sem codificação.
Por exemplo, você pode querer extrair postagens e comentários do Twitter. Tudo o que você precisa fazer é colar o URL no raspador, selecionar as postagens e comentários desejados e executar. Portanto, economiza tempo e esforços do trabalho mundano de copiar e colar.
https://www.datasciencecentral.com/wp-content/uploads/2021/10/web-scraping-introduction-1.jpg
Como começou a raspagem da web?
Embora para muitas pessoas pareça um conceito totalmente novo, a história da web scraping pode ser datada da época em que a World Wide Web nasceu.
No início, a internet era até impossível de pesquisar. Antes do desenvolvimento dos mecanismos de pesquisa, a internet era apenas uma coleção de sites FTP (File Transfer Protocol) nos quais os usuários navegavam para encontrar arquivos compartilhados específicos. Para localizar e organizar os dados distribuídos disponíveis na internet, as pessoas criaram um programa automatizado específico, hoje conhecido como web crawler/bot, para buscar todas as páginas na internet e copiar todo o conteúdo em bancos de dados para indexação.
Em seguida, a internet cresce, tornando-se o lar de milhões de páginas da Web que contêm um tesouro de dados em várias formas, incluindo textos, imagens, vídeos e áudios. Ela se transforma em uma fonte de dados aberta.
À medida que a fonte de dados se tornou incrivelmente rica e facilmente pesquisável, as pessoas começaram a achar simples buscar as informações que desejam, que muitas vezes se espalham por um grande número de sites, mas o problema ocorria quando queriam obter dados da internet –nem sempre sites ofereciam opções de download e a cópia manual era obviamente tediosa e ineficiente.
E é aí que entra a raspagem da web. A raspagem da web é, na verdade, alimentada por bots/rastreadores da web que funcionam da mesma forma que os usados nos mecanismos de pesquisa. Ou seja, buscar e copiar. A única diferença pode ser a escala. A raspagem da web concentra-se em extrair apenas dados específicos de determinados sites, enquanto os mecanismos de pesquisa costumam buscar a maioria dos sites da internet.
Como é feita a raspagem da Web?
1989 O nascimento da World Wide Web
Tecnicamente, a World Wide Web é diferente da internet. A primeira refere-se ao espaço informacional, enquanto a segunda é a rede formada por computadores.
Graças a Tim Berners-Lee, o inventor da WWW, surgiram 3 coisas que há muito fazem parte de nossa vida diária:
- Uniform Resource Locators (URLs) que usamos para ir ao site que queremos;
- hiperlinks embutidos que nos permitem navegar entre as páginas da web, como as páginas de detalhes do produto nas quais/onde podemos encontrar as especificações do produto e muitas outras coisas como “clientes que compraram isso também compraram”;
- páginas da web que contêm não apenas textos, mas também imagens, áudios, vídeos e componentes de software.
1990 O primeiro navegador da web
Também inventado por Tim Berners-Lee, foi chamado de WorldWideWeb (sem espaços), em homenagem ao projeto WWW. Um ano após o surgimento da web, as pessoas tinham uma forma de vê-la e interagir com ela.
1991 O primeiro servidor web e a primeira página web http://
A web continuou crescendo a uma velocidade bastante moderada. Em 1994, o número de servidores HTTP era superior a 200.
1993-Junho: O primeiro robô web – World Wide Web Wanderer
Embora funcionasse da mesma forma que os robôs da web hoje, destinava-se apenas a medir o tamanho da web.
1993-Dezembro: O primeiro mecanismo de pesquisa na Web baseado em rastreador – JumpStation
Como não havia tantos sites disponíveis na web, os mecanismos de pesquisa da época dependiam de seus administradores de sites humanos para coletar e editar os links em um formato específico. JumpStation trouxe um novo salto. É o primeiro mecanismo de busca da WWW baseado em um robô da web.
Desde então, as pessoas começaram a usar esses rastreadores da web programáticos para coletar e organizar a internet. De Infoseek, Altavista e Excite, até Bing e Google hoje, o núcleo de um bot de mecanismo de pesquisa permanece o mesmo: encontrar uma página da web, fazer o download (buscar), raspar todas as informações apresentadas na página da web e adicioná-la ao banco de dados do mecanismo de pesquisa.
Como as páginas da web são projetado para usuários humanos, e não para facilidade de uso automatizado, mesmo com o desenvolvimento do bot da web, ainda era difícil para engenheiros de computação e cientistas fazerem a raspagem da web, imagine para pessoas normais. Portanto, existem esforços em curso para tornar a web scraping mais disponível. Em 2000, Salesforce e eBay lançaram sua própria API, com a qual os programadores puderam acessar e baixar alguns dos dados disponíveis ao público. Desde então, muitos sites oferecem APIs da web para que as pessoas acessem seu banco de dados público. As APIs oferecem aos desenvolvedores uma maneira mais amigável de fazer web scraping, apenas coletando dados fornecidos por sites.
2004 Python Beautiful soup
Nem todos os sites oferecem APIs. Mesmo quando o fazem, não fornecem todos os dados que você deseja. Portanto, os programadores ainda estavam trabalhando no desenvolvimento de uma abordagem que pudesse facilitar a raspagem da web. Em 2004, a Beautiful Soup foi lançada. É uma biblioteca projetada para Python.
Na programação de computadores, uma biblioteca é uma coleção de módulos de script, como algoritmos comumente usados, que permitem ser usados sem a necessidade de serem reescritos, simplificando o processo de programação. Com comandos simples, a Beautiful Soup dá sentido à estrutura do site e ajuda a analisar o conteúdo de dentro do contêiner HTML. É considerada a biblioteca mais sofisticada e avançada para web scraping, e uma das abordagens mais comuns e populares atualmente.
2005-2006 Software de raspagem visual da web
Em 2006, Stefan Andresen e sua Kapow Software (adquirida pela Kofax em 2013) lançaram a Web Integration Platform versão 6.0, algo agora entendido como software visual de web scraping, que permite aos usuários simplesmente destacar o conteúdo de uma página da web e estruturar esses dados em um arquivo Excel utilizável, ou banco de dados.
Por fim, existe uma maneira de os grandes não programadores fazerem a raspagem da web por conta própria. Desde então, a raspagem da web está começando a se popularizar. Não-programadores podem encontrar facilmente mais de 80 softwares de extração de dados prontos para uso que fornecem processos visuais.
Como será a raspagem da web no futuro?
Coletamos dados, processamos dados e os transformamos em insights acionáveis. Está provado que gigantes de negócios como Microsoft e Amazon investem muito dinheiro na coleta de dados sobre seus consumidores para atingir pessoas com anúncios personalizados. Ao passo que as pequenas empresas são afastadas da concorrência de marketing por falta de capital extra para coletar dados.
Graças às ferramentas de web scraping, qualquer indivíduo, empresa e organização agora podem acessar dados da web para análise. Ao pesquisar “web scraping” em guru.com, você pode obter 10.088 resultados de pesquisa, o que significa que mais de 10.000 freelancers estão oferecendo serviços de web scraping no site.
As crescentes demandas de dados da web por empresas de todo o setor prosperam o mercado de raspagem da web e isso traz novos empregos e oportunidades de negócios.
Enquanto isso, como qualquer outra indústria emergente, a raspagem de dados na web também traz preocupações legais. O cenário legal em torno da legitimidade da web scraping continua a evoluir. Seu status legal permanece altamente específico do contexto. Por enquanto, muitas das questões legais mais interessantes que surgem dessa tendência permanecem sem resposta.
Uma maneira de contornar as possíveis consequências legais da raspagem de dados na web é consultar provedores profissionais de serviços de web scraping.
Saiba mais sobre Rede de dados e internet
-
![]()
Como empresas podem reforçar a segurança e evitar prejuízos no próximo ano
Por:Lizzette Pérez Arbesú
-
![]()
Falha do Cloudflare: impactos, lições aprendidas e conselhos de especialistas
Por:Lizzette Pérez Arbesú
-
![]()
Mais de 100 páginas falsas foram criadas por dia para aplicar golpes na Black Friday
-
![]()
Cipher destaca cuidados fundamentais para os consumidores nesta Black Friday



{kind=link}